Versioning isn't just for source code. Being able to track changes to data is critical for answering questions about data provenance, quality, and reproducibility. Daniel Whitenack joins me this week to talk about these concepts and share his work on Pachyderm. Pachyderm is an open source containerized data lake. During the show, Daniel mentioned the Gopher Data Science github repo as a great resource for any data scientists interested in the Go language. Although we didn't mention it, Daniel also did an interesting analysis on the 2016 world chess championship that complements our recent episode on chess well. You can find that post here Supplemental music is Lee Rosevere's Let's Start at the Beginning. Thanks to Periscope Data for sponsoring this episode. More about them at periscopedata.com/skeptics
 talk-data.com
talk-data.com
Topic
Data Lake
311
tagged
Activity Trend
Top Events
Summary
Do you wish that you could track the changes in your data the same way that you track the changes in your code? Pachyderm is a platform for building a data lake with a versioned file system. It also lets you use whatever languages you want to run your analysis with its container based task graph. This week Daniel Whitenack shares the story of how the project got started, how it works under the covers, and how you can get started using it today!
Preamble
Hello and welcome to the Data Engineering Podcast, the show about modern data infrastructure Go to dataengineeringpodcast.com to subscribe to the show, sign up for the newsletter, read the show notes, and get in touch. You can help support the show by checking out the Patreon page which is linked from the site. To help other people find the show you can leave a review on iTunes, or Google Play Music, and tell your friends and co-workers Your host is Tobias Macey and today I’m interviewing Daniel Whitenack about Pachyderm, a modern container based system for building and analyzing a versioned data lake.
Interview with Daniel Whitenack
Introduction How did you get started in the data engineering space? What is pachyderm and what problem were you trying to solve when the project was started? Where does the name come from? What are some of the competing projects in the space and what features does Pachyderm offer that would convince someone to choose it over the other options? Because of the fact that the analysis code and the data that it acts on are all versioned together it allows for tracking the provenance of the end result. Why is this such an important capability in the context of data engineering and analytics? What does Pachyderm use for the distribution and scaling mechanism of the file system? Given that you can version your data and track all of the modifications made to it in a manner that allows for traversal of those changesets, how much additional storage is necessary over and above the original capacity needed for the raw data? For a typical use of Pachyderm would someone keep all of the revisions in perpetuity or are the changesets primarily just useful in the context of an analysis workflow? Given that the state of the data is calculated by applying the diffs in sequence what impact does that have on processing speed and what are some of the ways of mitigating that? Another compelling feature of Pachyderm is the fact that it natively supports the use of any language for interacting with your data. Why is this such an important capability and why is it more difficult with alternative solutions?
How did you implement this feature so that it would be maintainable and easy to implement for end users?
Given that the intent of using containers is for encapsulating the analysis code from experimentation through to production, it seems that there is the potential for the implementations to run into problems as they scale. What are some things that users should be aware of to help mitigate this? The data pipeline and dependency graph tooling is a useful addition to the combination of file system and processing interface. Does that preclude any requirement for external tools such as Luigi or Airflow? I see that the docs mention using the map reduce pattern for analyzing the data in Pachyderm. Does it support other approaches such as streaming or tools like Apache Drill? What are some of the most interesting deployments and uses of Pachyderm that you have seen? What are some of the areas that you are looking for help from the community and are there any particular issues that the listeners can check out to get started with the project?
Keep in touch
Daniel
Twitter – @dwhitena
Pachyderm
Website
Free Weekend Project
GopherNotes
Links
AirBnB RethinkDB Flocker Infinite Project Git LFS Luigi Airflow Kafka Kubernetes Rkt SciKit Learn Docker Minikube General Fusion
The intro and outro music is from The Hug by The Freak Fandango Or

Re-architect relational applications to NoSQL, integrate relational database management systems with the Hadoop ecosystem, and transform and migrate relational data to and from Hadoop components. This book covers the best-practice design approaches to re-architecting your relational applications and transforming your relational data to optimize concurrency, security, denormalization, and performance. Winner of IBM's 2012 Gerstner Award for his implementation of big data and data warehouse initiatives and author of Practical Hadoop Security, author Bhushan Lakhe walks you through the entire transition process. First, he lays out the criteria for deciding what blend of re-architecting, migration, and integration between RDBMS and HDFS best meets your transition objectives. Then he demonstrates how to design your transition model. Lakhe proceeds to cover the selection criteria for ETL tools, the implementation steps for migration with SQOOP- and Flume-based data transfers, and transition optimization techniques for tuning partitions, scheduling aggregations, and redesigning ETL. Finally, he assesses the pros and cons of data lakes and Lambda architecture as integrative solutions and illustrates their implementation with real-world case studies. Hadoop/NoSQL solutions do not offer by default certain relational technology features such as role-based access control, locking for concurrent updates, and various tools for measuring and enhancing performance. Practical Hadoop Migration shows how to use open-source tools to emulate such relational functionalities in Hadoop ecosystem components. What You'll Learn Decide whether you should migrate your relational applications to big data technologies or integrate them Transition your relational applications to Hadoop/NoSQL platforms in terms of logical design and physical implementation Discover RDBMS-to-HDFS integration, data transformation, and optimization techniques Consider when to use Lambda architecture and data lake solutions Select and implement Hadoop-based components and applications to speed transition, optimize integrated performance, and emulate relational functionalities Who This Book Is For Database developers, database administrators, enterprise architects, Hadoop/NoSQL developers, and IT leaders. Its secondary readership is project and program managers and advanced students of database and management information systems.

Many organizations use Hadoop-driven data lakes as an adjunct staging area for their enterprise data warehouses (EDW). But for those companies ready to take the plunge, a data lake is far more useful as a one-stop-shop for extracting insights from their vast collection of data. With this eBook, you’ll learn best practices for building, maintaining, and deriving value from a Hadoop data lake in production environments. Authors Alice LaPlante and Ben Sharma explain how a data lake will enable your organization to manage an increasing volume of datasets—from blog postings and product reviews to streaming data—and to discover important relationships between them. Whether you want to control administrative costs in healthcare or reduce risk in financial services, this ebook addresses the architectural considerations and required capabilities you need to build your own data lake. With this report, you’ll learn: The key attributes of a data lake, including its ability to store information in native formats for later processing Why implementing data management and governance in your data lake is crucial How to address various challenges for building and managing a data lake Self-service options that enable different users to access the data lake without help from IT Emerging trends that will shape the future of data lakes

In "Data Lake Development with Big Data," you will explore the fundamental principles and techniques for constructing and managing a Data Lake tailored for your organization's big data challenges. This book provides practical advice and architectural strategies for ingesting, managing, and analyzing large-scale data efficiently and effectively. What this Book will help me do Learn how to architect a Data Lake from scratch tailored to your organizational needs. Master techniques for ingesting data using real-time and batch processing frameworks efficiently. Understand data governance, quality, and security considerations essential for scalable Data Lakes. Discover strategies for enabling users to explore data within the Data Lake effectively. Gain insights into integrating Data Lakes with Big Data analytic applications for high performance. Author(s) None Pasupuleti and Beulah Salome Purra bring their extensive expertise in big data and enterprise data management to this book. With years of hands-on experience designing and managing large-scale data architectures, their insights are rooted in practical knowledge and proven techniques. Who is it for? This book is ideal for data architects and senior managers tasked with adapting or creating scalable data solutions in enterprise contexts. Readers should have foundational knowledge of master data management and be familiar with Big Data technologies to derive maximum value from the content presented.

Get Started Fast with Apache Hadoop ® 2, YARN, and Today’s Hadoop Ecosystem With Hadoop 2.x and YARN, Hadoop moves beyond MapReduce to become practical for virtually any type of data processing. Hadoop 2.x and the Data Lake concept represent a radical shift away from conventional approaches to data usage and storage. Hadoop 2.x installations offer unmatched scalability and breakthrough extensibility that supports new and existing Big Data analytics processing methods and models. Hadoop ® 2 Quick-Start Guide is the first easy, accessible guide to Apache Hadoop 2.x, YARN, and the modern Hadoop ecosystem. Building on his unsurpassed experience teaching Hadoop and Big Data, author Douglas Eadline covers all the basics you need to know to install and use Hadoop 2 on personal computers or servers, and to navigate the powerful technologies that complement it. Eadline concisely introduces and explains every key Hadoop 2 concept, tool, and service, illustrating each with a simple “beginning-to-end” example and identifying trustworthy, up-to-date resources for learning more. This guide is ideal if you want to learn about Hadoop 2 without getting mired in technical details. Douglas Eadline will bring you up to speed quickly, whether you’re a user, admin, devops specialist, programmer, architect, analyst, or data scientist. Coverage Includes Understanding what Hadoop 2 and YARN do, and how they improve on Hadoop 1 with MapReduce Understanding Hadoop-based Data Lakes versus RDBMS Data Warehouses Installing Hadoop 2 and core services on Linux machines, virtualized sandboxes, or clusters Exploring the Hadoop Distributed File System (HDFS) Understanding the essentials of MapReduce and YARN application programming Simplifying programming and data movement with Apache Pig, Hive, Sqoop, Flume, Oozie, and HBase Observing application progress, controlling jobs, and managing workflows Managing Hadoop efficiently with Apache Ambari–including recipes for HDFS to NFSv3 gateway, HDFS snapshots, and YARN configuration Learning basic Hadoop 2 troubleshooting, and installing Apache Hue and Apache Spark

Organizations across many industries have recently created fast-growing repositories to deal with an influx of new data from many sources and often in multiple formats. To manage these data lakes, companies have begun to leave the familiar confines of relational databases and data warehouses for Hadoop and various big data solutions. But adopting new technology alone won’t solve the problem. Based on interviews with several experts in data management, author Andy Oram provides an in-depth look at common issues you’re likely to encounter as you consider how to manage business data. You’ll explore five key topic areas, including: Acquisition and ingestion: how to solve these problems with a degree of automation. Metadata: how to keep track of when data came in and how it was formatted, and how to make it available at later stages of processing. Data preparation and cleaning: what you need to know before you prepare and clean your data, and what needs to be cleaned up and how. Organizing workflows: what you should do to combine your tasks—ingestion, cataloging, and data preparation—into an end-to-end workflow. Access control: how to address security and access controls at all stages of data handling. Andy Oram, an editor at O’Reilly Media since 1992, currently specializes in programming. His work for O'Reilly includes the first books on Linux ever published commercially in the United States.

Companies of all sizes are considering data lakes as a way to deal with terabytes of security data that can help them conduct forensic investigations and serve as an early indicator to identify bad or relevant behavior. Many think about replacing their existing SIEM (security information and event management) systems with Hadoop running on commodity hardware. Before your company jumps into the deep end, you first need to weigh several critical factors. This O'Reilly report takes you through technological and design options for implementing a data lake. Each option not only supports your data analytics use cases, but is also accessible by processes, workflows, third-party tools, and teams across your organization. Within this report, you'll explore: Five questions to ask before choosing architecture for your backend data store How data lakes can overcome scalability and data duplication issues Different options for storing context and unstructured log data Data access use cases covering both search and analytical queries via SQL Processes necessary for ingesting data into a data lake, including parsing, enrichment, and aggregation Four methods for embedding your SIEM into a data lake
Learn how to simplify the management of a data lake by enabling git-like operations over files in object storage. See how experimenting, reproducing data, and guaranteeing data quality are simplified and is all possible to achieve through open source tooling.
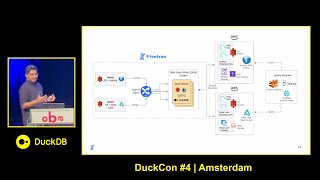
Speaker: Subash Roul (Fivetran) Slides: https://blobs.duckdb.org/events/duckcon4/subash-roul-building-a-data-lake-solution-using-duckdb.pdf

With Eon on Azure, backups don’t just sit idle—they become a first-class data source. Eon transforms cloud backups into Iceberg tables in Blob Storage, instantly queryable through Microsoft Fabric and OneLake. Learn how backup data flows into Fabric engines like SQL, Spark, and KQL, and how it fuels AI innovation with Azure OpenAI. See how organizations can collaborate more effectively by unifying protection, analytics, and AI on Eon’s data lake.