Overview of key trends from 2024 and forecast pivotal shifts for 2025. Importance of data quality for accurate marketing. Leveraging AI for web data measurement.
 talk-data.com
talk-data.com
Topic
Data Quality
data_management
data_cleansing
data_validation
537
tagged
Activity Trend
82
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
125
O'Reilly Data Engineering Books
38
Data + AI Summit 2025
37
Databricks DATA + AI Summit 2023
30
O'Reilly Data Science Books
26
DataFramed
22
Big Data LDN 2024
17
Big Data LDN 2025
16
Secrets of Data Analytics Leaders
16
Data Universe 2024
13
Airflow Summit 2025
10
gartner-data-analytics-uk-2025
9
Discover how the Digital Analytics team at Itaú, the largest private bank in Latin America, built a high-quality, unified, and standardized tagging ecosystem that simplified data collection, ensured consistent data quality across various measurement tools, and created a comprehensive, customer-centric data strategy across over 10 apps, thousands of developers, and hundreds of business operations.
Jason Touleyrou, Data Engineering Manager at Corewell Health joined Yuliia to discuss why most organizations struggle with data governance. He argues that data teams should focus on building trust through flexible systems rather than rigid controls. Challenging traditional data quality approaches, Jason suggests starting with basic freshness checks and evolving governance gradually. Drawing from his experience across healthcare and marketing analytics, he shares practical strategies for implementing governance during migrations and measuring data team value beyond conventional metrics. Jason's linkedin page - https://www.linkedin.com/in/jasontouleyrou/

by
Navneet Srivastava
(Amazon Web Services)
,
Andrew Rife
(Vanguard)
,
Shiv Narayanan
(Amazon Web Services)
The quality of data powers business decisions that drive outcomes. Successful businesses run on trusted data that is reliable and accurate. Join this session to learn how to apply Amazon DataZone and AWS Glue to deliver data integrity and consistency through precise data transformation, data cataloging, data governance, and data lineage, as well as to set up data quality checks, automate validation processes, and manage metadata.
Learn more: AWS re:Invent: https://go.aws/reinvent. More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
About AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.
AWSreInvent #AWSreInvent2024

🌟 Session Overview 🌟
Session Name: Empowering Real-Time ML Inference and Training with GRIS: A Deep Dive into High Availability and Low Latency Data Solutions Speaker: Takahiko Saito Session Description: In the rapidly evolving landscape of machine learning (ML) and data processing, the need for real-time data delivery systems that offer high availability, low latency, and robust service level agreements (SLAs) has never been more critical. This session introduces GRIS (Generic Real-time Inference Service), a cutting-edge platform designed to meet these demands head-on, facilitating real-time ML inference and historical data processing for ML model training.
Attendees will gain insights into GRIS's capabilities, including its support for real-time data delivery for ML inference, products requiring high availability, low latency, and strong SLA adherence, and real-time product performance monitoring. We will explore how GRIS prioritizes use cases off the Netflix critical path, such as choosing, playback, and sign-up processes, while ensuring data delivery for critical real-time monitoring tasks like anomaly detection during product launches and live events.
The session will delve into the key design decisions and challenges faced during the MVP release of GRIS, highlighting its low latency, high availability gRPC API for inference, and the use of Granular Historical Dataset via Iceberg for training. We will discuss the MVP metrics, including feature groups, categories, and aggregation windows, and how these elements contribute to the platform's effectiveness in real-time data processing.
Furthermore, we will cover the production readiness of GRIS, including streaming jobs, on-call alerts, and data quality measures. The session will provide a comprehensive overview of the MVP data quality framework for GRIS, including online and offline checks, and how these measures ensure the integrity and consistency of data processed by the platform.
Looking ahead, the roadmap for GRIS will be presented, outlining the journey from POC to GA, including the introduction of processor metrics, event-level transaction history, and the next batch of metrics for advanced aggregation types. We will also discuss the potential for a user-facing metrics definition API/DSL and how GRIS is poised to enable new use cases for teams across various domains.
This session is a must-attend for data scientists, ML engineers, and technology leaders looking to stay at the forefront of real-time data processing and ML model training. Whether you're interested in the technical underpinnings of GRIS or its application in real-world scenarios, this session will provide valuable insights into how high availability, low latency data solutions are shaping the future of ML and data analytics.
🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape. Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀 Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts. Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀 🔗 Find Other Years' Videos: 2023 Big Data Conference Europe https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g 2022 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT 2021 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/ 👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/ 🐦 Twitter: @BigDataConfEU, @europe_rpa 🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/ 🎥 YouTube: http://www.youtube.com/@DATAMINERLT

🌟 Session Overview 🌟
Session Name: Roadmap to Responsible AI Speaker: Amardeep Lidder Session Description: In this session, Amardeep will share actionable, tried-and-tested approaches to establish effective governance for AI.
There has naturally been a lot of excitement around the potential of AI. However, many conversations are limited to concepts and buzzwords. AI governance is critical in ensuring the responsible and ethical use of AI, as well as driving discovery and innovation.
Speaker will discuss practical examples and learnings based on their successful data governance programs.
Key Takeaways:
Establishing Data Trust: Our framework to measure and improve data quality and governance, ensuring that model inputs and outputs can be trusted. Navigating Regulatory Compliance: Overview of current regulations and considerations for the future. Mitigating Risks: Establishing guardrails to ensure AI tools and systems remain safe and ethical; safeguarding against bias, privacy, and misuse. Balancing Safety and Innovation: How to enable transparent decision-making and explainability to ensure responsible AI use.
🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape. Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀 Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts. Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀 🔗 Find Other Years' Videos: 2023 Big Data Conference Europe https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g 2022 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT 2021 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/ 👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/ 🐦 Twitter: @BigDataConfEU, @europe_rpa 🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/ 🎥 YouTube: http://www.youtube.com/@DATAMINERLT

🌟 Session Overview 🌟
Session Name: How Well do LLMs Detect Anomalies in Your Data? Speaker: Chloe Caron Session Description: Data quality challenges can severely impact businesses, causing a reported average 12% revenue loss for US companies (according to an Experian report). In this talk, we will follow a journey into constructing an anomaly detector, exploring LLMs, prompt engineering, and data type impacts. Along this path, we will analyze the use of multiple tools, including OpenAI, BigQuery, and Mistral. By the end, you will have gained insights on how to boost the accuracy of your anomaly detector and strengthen your data quality strategy.
🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape. Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀 Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts. Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀 🔗 Find Other Years' Videos: 2023 Big Data Conference Europe https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g 2022 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT 2021 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/ 👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/ 🐦 Twitter: @BigDataConfEU, @europe_rpa 🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/ 🎥 YouTube: http://www.youtube.com/@DATAMINERLT

🌟 Session Overview 🌟
Session Name: Applying Data Quality Monitoring Speaker: Martin Pohjakivi Session Description: To provide reliable data-driven products and services, ensuring relevant and accurate data is crucial. This session will explore approaches to defining a strategy for managing data quality.
🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape. Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀 Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts. Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀 🔗 Find Other Years' Videos: 2023 Big Data Conference Europe https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g 2022 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT 2021 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/ 👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/ 🐦 Twitter: @BigDataConfEU, @europe_rpa 🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/ 🎥 YouTube: http://www.youtube.com/@DATAMINERLT

Understanding your data in context means that all users can discover and comprehend the meaning of their data so they can use it confidently to drive business value. With a centralized data catalog, data can be found easily, data quality can be quantified and tracked with lineage, access permissions can be requested and provisioned, and data can be used to make business decisions. In this session, learn how Amazon DataZone, AWS Glue Data Catalog, and AWS Lake Formation help you build a catalog accessible to all of your data marketplace users.
Learn more: AWS re:Invent: https://go.aws/reinvent. More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
About AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.
AWSreInvent #AWSreInvent2024

In this session, gain the skills needed to deploy end-to-end generative AI applications using your most valuable data. While this session focuses on the Retrieval Augmented Generation (RAG) process, the concepts also apply to other methods of customizing generative AI applications. Discover best practice architectures using AWS database services like Amazon Aurora, Amazon OpenSearch Service, or Amazon MemoryDB along with data processing services like AWS Glue and streaming data services like Amazon Kinesis. Learn data lake, governance, and data quality concepts and how Amazon Bedrock Knowledge Bases, Amazon Bedrock Agents, and other features tie solution components together.
Learn more: AWS re:Invent: https://go.aws/reinvent. More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
About AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.
AWSreInvent #AWSreInvent2024
In this episode, I had the pleasure of speaking with Ken Pickering, VP of Engineering at Going, about the intricacies of streaming data into a Trino and Iceberg lakehouse. Ken shared his journey from product engineering to becoming deeply involved in data-centric roles, highlighting his experiences in ecommerce and InsurTech. At Going, Ken leads the data platform team, focusing on finding travel deals for consumers, a task that involves handling massive volumes of flight data and event stream information.
Ken explained the dual approach of passive and active search strategies used by Going to manage the vast data landscape. Passive search involves aggregating data from global distribution systems, while active search is more transactional, querying specific flight prices. This approach helps Going sift through approximately 50 petabytes of data annually to identify the best travel deals.
We delved into the technical architecture supporting these operations, including the use of Confluent for data streaming, Starburst Galaxy for transformation, and Databricks for modeling. Ken emphasized the importance of an open lakehouse architecture, which allows for flexibility and scalability as the business grows.
Ken also discussed the composition of Going's engineering and data teams, highlighting the collaborative nature of their work and the reliance on vendor tooling to streamline operations. He shared insights into the challenges and strategies of managing data life cycles, ensuring data quality, and maintaining uptime for consumer-facing applications.
Throughout our conversation, Ken provided a glimpse into the future of Going's data architecture, including potential expansions into other travel modes and the integration of large language models for enhanced customer interaction. This episode offers a comprehensive look at the complexities and innovations in building a data-driven travel advisory service.
Data Dynamics: Navigating the Role of Data Product Managers The Data Product Management In Action podcast, brought to you by Soda and executive producer Scott Hirleman, is a platform for data product management practitioners to share insights and experiences. In Episode 22 of Data Product Management in Action, we welcome back our host Michael Toland as he chats with guest Chandan Gadodia. Listen along as they explore the vital role of data product managers. Discover the distinctions between data, IT, and functional product managers and their contributions to product success. Learn more about key focus areas like data pipelines, quality, and standards, as well as the role of AI in enhancing data quality. Join us for an enlightening discussion on the evolving landscape of data management! About our host Michael Toland: Toland is a Product Management Coach and Consultant with Pathfinder Product, aTest Double Operation. He has worked in product officially since 2016, where he worked at Verizon on large scale system modernizations and migration initiatives for reference data and decision platforms. Outside of his professional career, Michael serves as the Treasurer for the New Leaders Council, mentors fellows with Venture for America, sings in the Columbus Symphony, writes satire posts for his blog Dignified Productor Test Double, depending on the topic, and is excited to be chatting with folks on Data Product Management. Connect with Michael on LinkedIn. About our guest Chadan Gadodia: With over a decade serving in data and analytics, Chandan Gadodia, a seasoned Data Product Manager, has held several roles within the industry. From managing internal data assets to overseeing global data products, Chandan's passion for learning from diverse perspectives, connecting with global colleagues, and contributing to growth for himself and his organization has been constant. He is a big advocate for data literacy and strongly believes in data driven business outcomes. Connect with Chadan on LinkedIn. All views and opinions expressed are those of the individuals and do not necessarily reflect their employers or anyone else. Join the conversation on LinkedIn. Apply to be a guest or nominate someone that you know. Do you love what you're listening to? Please rate and review the podcast, and share it with fellow practitioners you know. Your support helps us reach more listeners and continue providing valuable insights!

This book, "Building Modern Data Applications Using Databricks Lakehouse," provides a comprehensive guide for data professionals to master the Databricks platform. You'll learn to effectively build, deploy, and monitor robust data pipelines with Databricks' Delta Live Tables, empowering you to manage and optimize cloud-based data operations effortlessly. What this Book will help me do Understand the foundations and concepts of Delta Live Tables and its role in data pipeline development. Learn workflows to process and transform real-time and batch data efficiently using the Databricks lakehouse architecture. Master the implementation of Unity Catalog for governance and secure data access in modern data applications. Deploy and automate data pipeline changes using CI/CD, leveraging tools like Terraform and Databricks Asset Bundles. Gain advanced insights in monitoring data quality and performance, optimizing cloud costs, and managing DataOps tasks effectively. Author(s) Will Girten, the author, is a seasoned Solutions Architect at Databricks with over a decade of experience in data and AI systems. With a deep expertise in modern data architectures, Will is adept at simplifying complex topics and translating them into actionable knowledge. His books emphasize real-time application and offer clear, hands-on examples, making learning engaging and impactful. Who is it for? This book is geared towards data engineers, analysts, and DataOps professionals seeking efficient strategies to implement and maintain robust data pipelines. If you have a basic understanding of Python and Apache Spark and wish to delve deeper into the Databricks platform for streamlining workflows, this book is tailored for you.
Summary Gleb Mezhanskiy, CEO and co-founder of DataFold, joins Tobias Macey to discuss the challenges and innovations in data migrations. Gleb shares his experiences building and scaling data platforms at companies like Autodesk and Lyft, and how these experiences inspired the creation of DataFold to address data quality issues across teams. He outlines the complexities of data migrations, including common pitfalls such as technical debt and the importance of achieving parity between old and new systems. Gleb also discusses DataFold's innovative use of AI and large language models (LLMs) to automate translation and reconciliation processes in data migrations, reducing time and effort required for migrations. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm welcoming back Gleb Mezhanskiy to talk about Datafold's experience bringing AI to bear on the problem of migrating your data stackInterview IntroductionHow did you get involved in the area of data management?Can you describe what the Data Migration Agent is and the story behind it?What is the core problem that you are targeting with the agent?What are the biggest time sinks in the process of database and tooling migration that teams run into?Can you describe the architecture of your agent?What was your selection and evaluation process for the LLM that you are using?What were some of the main unknowns that you had to discover going into the project?What are some of the evolutions in the ecosystem that occurred either during the development process or since your initial launch that have caused you to second-guess elements of the design?In terms of SQL translation there are libraries such as SQLGlot and the work being done with SDF that aim to address that through AST parsing and subsequent dialect generation. What are the ways that approach is insufficient in the context of a platform migration?How does the approach you are taking with the combination of data-diffing and automated translation help build confidence in the migration target?What are the most interesting, innovative, or unexpected ways that you have seen the Data Migration Agent used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on building an AI powered migration assistant?When is the data migration agent the wrong choice?What do you have planned for the future of applications of AI at Datafold?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links DatafoldDatafold Migration AgentDatafold data-diffDatafold Reconciliation Podcast EpisodeSQLGlotLark parserClaude 3.5 SonnetLookerPodcast EpisodeThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
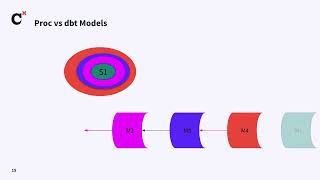
As organizations evolve, many still rely on legacy SQL queries and stored procedures that can become bottlenecks in scaling data infrastructure. In this talk, we will explore how to modernize these workflows by migrating legacy SQL and stored procedures into dbt models, enabling more efficient, scalable, and version-controlled data transformations. We’ll discuss practical strategies for refactoring complex logic, ensuring data lineage, data quality and unit testing benefits, and improving collaboration among teams. This session is ideal for data and analytics engineers, analysts, and anyone looking to optimize their ETL workflows using dbt.
Speaker: Bishal Gupta
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Are you a dbt Cloud customer aiming to fast-track your company’s journey to GenAI and speed up data development? You can't deploy AI applications without trusting the data that feeds them. Rule-based data quality approaches are a dead end that leaves you in a never-ending maintenance cycle. Join us to learn how modern machine learning approaches to data quality overcome the limits of rules and checks, helping you escape the reactive doom loop and unlock high-quality data for your whole company.
Speakers: Amy Reams VP Business Development Anomalo
Jonathan Karon Partner Innovation Lead Anomalo
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
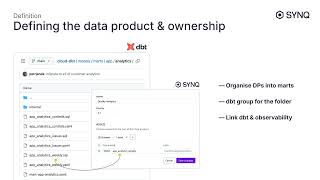
With analytics teams' growing ambition to build business automation, foundational AI systems, or customer-facing products, we must shift our mindset about data quality. Mechanically applied testing will not be enough; we need a more robust strategy akin to software engineering.
We outline a new approach to data testing and observability anchored in the ‘Data Products’ concept and walk through the practical implementation of a production-grade analytics system at SYNQ, powered by ClickHouse and dbt.
Speaker: Petr Janda Founder SYNQ
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

In this session, Gleb Mezhanskiy, CEO of Datafold, will share innovative strategies for automating the conversion of legacy transformation code (i.e., stored procedures) to dbt models, a crucial step in modernizing your data infrastructure. He will also delve into techniques for automating the data reconciliation between legacy and new systems with cross-database data diffing, ensuring data integrity and accelerating migration timelines. Additionally, Gleb will demonstrate how data teams can adopt a proactive approach to data quality post-migration by leveraging a "shift-left" approach to data testing and monitoring.
Speaker: Gleb Mezhanskiy Datafold
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

If you are not confident that the data is correct, you cannot use it to make decisions. To act as an effective partner with the rest of the business, your data team needs to know that their data is accurate and high-quality and be able to demonstrate that to their stakeholders. Join Reuben to learn how to use new features such as unit testing, Advanced CI, model-level notifications, and data health tiles to ship trusted data products faster.
Speaker: Reuben McCreanor Product Manager dbt Labs
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements