Spark applications often need to query external data sources such as file-based data sources or relational data sources. In order to do this, Spark provides Data Source APIs to access structured data through Spark SQL.
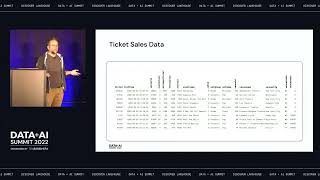
Data Source APIs have optimization rules such as filter push down and column pruning to reduce the amount of data that needs to be processed to improve query performance. As part of our ongoing project to provide generic Data Source V2 push down APIs, we have introduced partial aggregate push down, which significantly speeds up spark jobs by dramatically reducing the amount of data transferred between data sources and Spark. We have implemented aggregate push down in both JDBC and parquet.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/