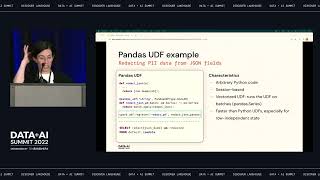
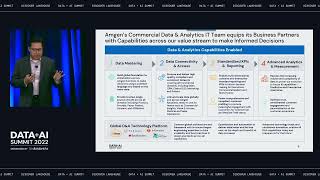
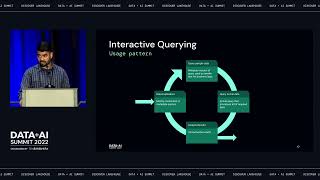
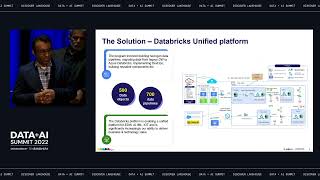
Organizations want data lakes to be the source of truth for analytics. But operational teams rarely recognize the power the data lake, shortening the reach of all the valuable data within it. Instead, these business users often treat operational tools like Salesforce, Marketo, and NetSuite as their source of truth.
The reality is lakehouses and operational tools alike have missed critical pieces of data and don’t provide the full customer picture. Operational Analytics solves this last mile problem by making it possible to sync transformed data directly from your data lake back into these systems to expand the reach of your data.
In this talk you’ll learn: - What Operational Analytics & Reverse ETL are and why they're taking off - How Operational Analytics helps companies today activate and expand the reach of their data - Real-life use cases from companies using Operational Analytics to empower their data teams & give them the seat at the table they deserve
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/