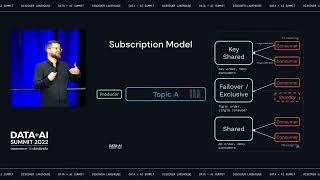
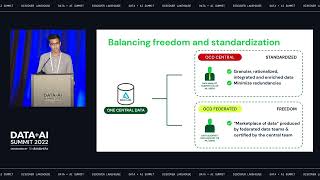
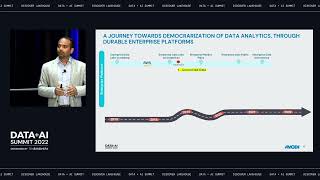
At Apple, data scientists and engineers are running enormous Spark workloads to deliver amazing cloud services. Apple Cloud Service supports the ever-increasing scale of Spark workloads and resource requirements with great user experience: from code to deployment management, one interface for all compute backends.
In this talk, Aaruna and Zhou would walk through the lessons we learnt and pitfalls encountered for supporting the service at Apple scale - we would share how Apple Cloud Services effectively orchestrate Spark applications, as well as the seamless switchover among different resource managers - be it in Mesos or Kubernetes, private or on-premise infrastructure. We will also cover the monitoring system and how it helps tuning Spark resource requirements with actual execution analysis.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/