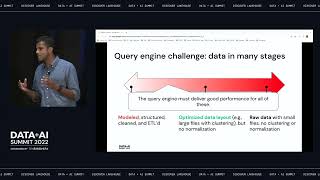
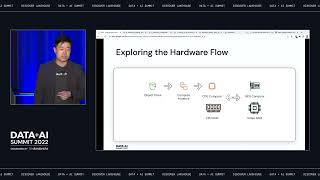
Modern machine learning (ML) workloads, such as deep learning and large-scale model training, are compute-intensive and require distributed execution. Ray is an open-source, distributed framework from U.C. Berkeley’s RISELab that easily scales Python applications and ML workloads from a laptop to a cluster, with an emphasis on the unique performance challenges of ML/AI systems. It is now used in many production deployments.
This talk will cover Ray’s overview, architecture, core concepts, and primitives, such as remote Tasks and Actors; briefly discuss Ray’s native libraries (Ray Tune, Ray Train, Ray Serve, Ray Datasets, RLlib); and Ray’s growing ecosystem to scale your Python or ML workloads.
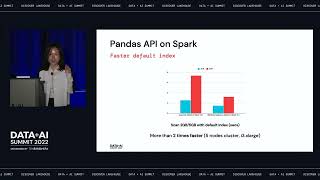
Through a demo using XGBoost for classification, we will demonstrate how you can scale training, hyperparameter tuning, and inference—from a single node to a cluster, with tangible performance difference when using Ray.
The takeaways from this talk are :
Learn Ray architecture, core concepts, and Ray primitives and patterns
Why Distributed computing will be the norm not an exception
How to scale your ML workloads with Ray libraries:
Training on a single node vs. Ray cluster, using XGBoost with/without Ray
Hyperparameter search and tuning, using XGBoost with Ray and Ray Tune
Inferencing at scale, using XGBoost with/without Ray
Connect with us:
Website: https://databricks.com
Facebook: https://www.facebook.com/databricksinc
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/data...
Instagram: https://www.instagram.com/databricksinc/