Sligro Food Group, Dutch market leader in food service, needed to centralise data to improve retail decision-making and stay competitive. Moving away from on-premise databases, they simplified integration to GCP. Join this session to learn why centralised data is key for Sligro, why enterprises choose Fivetran over legacy tools, and how to integrate data into the cloud for real-time analytics.
 talk-data.com
talk-data.com
Topic
Fivetran
etl
data_integration
cloud
76
tagged
Activity Trend
17
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
13
Databricks DATA + AI Summit 2023
9
dbt Coalesce 2023
5
dbt Coalesce 2022
4
Modern Data Stack Conference 2021
3
Modern Data Stack Conference 2023
3
dbt Coalesce 2025
3
Big Data LDN 2025
3
Data + AI Summit 2025
3
Snowflake World Tour Berlin
2
Airflow Summit 2022
2
The Joe Reis Show
2
Ever wonder how companies in the crowded data and AI space build powerful alliances to drive revenue and growth? In this episode, I sit down with Eleanor Thompson, a partnerships expert based in London and founder of a successful partnerships consultancy. Drawing from her experience running the partner program at Fivetran during its hyper-growth phase, Eleanor shares the essential strategies for building a successful partnership ecosystem from the ground up. We also also discuss the mental fortitude required for entrepreneurship, drawing surprising parallels between running a business and competing in high-intensity fitness events like Hyrox.
Tune in to learn: The fundamental reasons why partnerships are critical for expanding your reach and generating revenue. When is the right time for a startup to focus on partnerships (hint: it's not day one). Eleanor's "4A" framework (Alignment, Ability, Audience, Accountability) for identifying the perfect partner. The key roles, from Partner Sales Engineers to Partner Ops, needed to build a successful partnerships team. Red flags to watch for when a potential partner is more focused on margin than customer value. How AI can be used to identify ideal partners and even predict their future success.
Find Eleanor Thompson online: LinkedIn: Eleanor Thompson Website: https://branchworks.io
BusinessPartnerships #DataEngineering #AI #Entrepreneurship #Tech #Startup #GoToMarket
Timestamps 00:49 - Who is Eleanor Thompson? 02:25 - Why Do Business Partnerships Exist? 05:26 - When is the Right Time for a Company to Start Building Partnerships? 06:40 - The 4A Framework for Defining Your Ideal Partner Profile 08:20 - Joe's Experience Partnering with Big Tech 12:33 - How to Structure a Partnerships Team in a Growing Tech Company 20:49 - What is Partner Operations and Why is It a Critical Hire? 22:30 - The Importance of Trust and Referral Fees 25:15 - Eleanor's Journey as an "Accidental CEO" 30:10 - The Mental Fitness and Resilience Required to Be a Founder 41:20 - How to Use AI in Your Partnership Strategy 45:00 - How to Spot a Good Partner on the Very First Call 46:33 - Red Flags to Watch For in Potential Partners 51:35 - How Fitness and Hyrox Competitions Fuel Business Success 59:45 - Where to Find Eleanor Thompson
Red Hat’s unified data and AI platform relies on Apache Airflow for orchestration, alongside Snowflake, Fivetran, and Atlan. The platform prioritizes building a dependable data foundation, recognizing that effective AI depends on quality data. Airflow was selected for its predictability, extensive connectivity, reliability, and scalability. The platform now supports business analytics, transitioning from ETL to ELT processes. This has resulted in a remarkable improvement in how we make data available for business decisions. The platform’s capabilities are being extended to power Digital Workers (AI agents) using large language models, encompassing model training, fine-tuning, and inference. Two Digital Workers are currently deployed, with more in development. This presentation will detail the rationale and background of this evolution, followed by an explanation of the architectural decisions made and the challenges encountered and resolved throughout the process of transforming into an AI-enabled data platform to power Red Hat’s business.
To accelerate growth, the National Rugby League (NRL) aimed to enhance its fan and participant experience. Using Fivetran as the cornerstone of its modern data stack, NRL centralised data with high-performance pipelines, enabling fast, accurate reporting and real-time insights. They successfully built a Single Customer View (SCV), providing a unified understanding of fans and participants. Learn how NRL transforms its data into a strategic asset to enable smarter decisions and long-term impact.
by
Nina Anderson
(dbt Labs)
,
Mitch Ertle
(Sigma)
,
David Hrncir
(Fivetran)
,
Pradeep Anandapu
(Databricks)
This hands-on lab guides participants through the complete customer data analytics journey on Databricks, leveraging leading partner solutions - Fivetran, dbt Cloud, and Sigma. Attendees will learn how to:- Seamlessly connect to Fivetran, dbt Cloud, and Sigma using Databricks Partner Connect- Ingest data using Fivetran, transform and model data with dbt Cloud, and create interactive dashboards in Sigma, all on top of the Databricks Data Intelligence Platform- Empower teams to make faster, data-driven decisions by streamlining the entire analytics workflow using an integrated, scalable, and user-friendly platform

Organizations have hundreds of data sources, some of which are very niche or difficult to access. Incorporating this data into your lakehouse requires significant time and resources, hindering your ability to work on more value-add projects. Enter the Fivetran Connector SDK- a powerful new tool that enables your team to create custom pipelines for niche systems, custom APIs, and sources with specific data filtering requirements, seamlessly integrating with Databricks. During this session, Fivetran will demonstrate how to (1) Leverage the Connector SDK to build scalable connectors, enabling the ingestion of diverse data into Databricks (2) Gain flexibility and control over historical and incremental syncs, delete capture, state management, multithreading data extraction, and custom schemas (3) Utilize practical examples, code snippets, and architectural considerations to overcome data integration challenges and unlock the full potential of your Databricks environment.

Dropbox, a leading cloud storage platform, is on a mission to accelerate data insights to better understand customers’ needs and elevate the overall customer experience. By leveraging Fivetran’s data movement platform, Dropbox gained real-time visibility into customer sentiment, marketing ROI, and ad performance-empowering teams to optimize spend, improve operational efficiency, and deliver greater business outcomes.Join this session to learn how Dropbox:- Cut data pipeline time from 8 weeks to 30 minutes by automating ingestion and streamlining reporting workflows.- Enable real-time, reliable data movement across tools like Zendesk Chat, Google Ads, MySQL, and more — at global operations scale.- Unify fragmented data sources into the Databricks Data Intelligence Platform to reduce redundancy, improve accessibility, and support scalable analytics.
Data leaders face a dual challenge: handling the explosive growth of data while managing costs — and they have to do both without compromising performance. In this session, we explore strategies to minimize data integration TCO and measure the performance of your pipelines. Hear how Saint Gobain achieved a 40% cost reduction and 250% productivity boost with automated data integration.
Data leaders will learn about:
Modern data architectures for increased efficiency
High-performance pipelines to move business-critical data from SAP
Hidden compute costs and how to reduce them for improved ROI

Learn the technical and soft skills you need to succeed in your career as a data analyst. You’ve learned how to use Python, R, SQL, and the statistical skills needed to get started as a data analyst—so, what’s next? Effective Data Analysis bridges the gap between foundational skills and real-world application. This book provides clear, actionable guidance on transforming business questions into impactful data projects, ensuring you’re tracking the right metrics, and equipping you with a modern data analyst’s essential toolbox. In Effective Data Analysis, you’ll gain the skills needed to excel as a data analyst, including: Maximizing the impact of your analytics projects and deliverables Identifying and leveraging data sources to enhance organizational insights Mastering statistical tests, understanding their strengths, limitations, and when to use them Overcoming the challenges and caveats at every stage of an analytics project Applying your expertise across a variety of domains with confidence Effective Data Analysis is full of sage advice on how to be an effective data analyst in a real production environment. Inside, you’ll find methods that enhance the value of your work—from choosing the right analysis approach, to developing a data-informed organizational culture. About the Technology Data analysts need top-notch knowledge of statistics and programming. They also need to manage clueless stakeholders, navigate messy problems, and advocate for resources. This unique book covers the essential technical topics and soft skills you need to be effective in the real world. About the Book Effective Data Analysis helps you lock down those skills along with unfiltered insight into what the job really looks like. You’ll build out your technical toolbox with tips for defining metrics, testing code, automation, sourcing data, and more. Along the way, you’ll learn to handle the human side of data analysis, including how to turn vague requirements into efficient data pipelines. And you’re sure to love author Mona Khalil’s illustrations, industry examples, and a friendly writing style. What's Inside Identify and incorporate external data Communicate with non-technical stakeholders Apply and interpret statistical tests Techniques to approach any business problem About the Reader Written for early-career data analysts, but useful for all. About the Author Mona Khalil is the Senior Manager of Analytics Engineering at Justworks. Quotes Your roadmap to becoming a standout data analyst! An intriguing blend of technical expertise and practical wisdom. - Chester Ismay, MATE Seminars A thoughtful guide to delivering real-world data analysis. It will be an eye-opening read for all data professionals! - David Lee, Justworks Inc. Compelling insights into the relationship between organizations and data. The real-life examples will help you excel in your data career. - Jeremy Moulton, Greenhouse Mona’s wide range of experience shines in her thoughtful, relevant examples. - Jessica Cherny, Fivetran
Fivetran recently passed $300 million ARR and has over 7,000 customers globally. Taylor Brown, the cofounder and COO of Fivetran, joins the show to talk about Fivetran's moat, the impact of AI on the data ingestion space, and open table formats and catalogs. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
The sheer number of tools and technologies that can infiltrate your work processes can be overwhelming. Choosing the right ones to invest in is critical, but how do you know where to start? What steps should you take to build a solid, scalable data infrastructure that can handle the growth of your business? And with AI becoming a central focus for many organizations, how can you ensure that your data strategy is aligned to support these initiatives? It’s no longer just about managing data; it’s about future-proofing your organization. Taylor Brown is the COO and Co-Founder of Fivetran, the global leader in data movement. With a vision to simplify data connectivity and accessibility, Taylor has been instrumental in transforming the way organizations manage their data infrastructure. Fivetran has grown rapidly, becoming a trusted partner for thousands of companies worldwide. Taylor's expertise in technology and business strategy has positioned Fivetran at the forefront of the data integration industry, driving innovation and empowering businesses to harness the full potential of their data. Prior to Fivetran, Taylor honed his skills in various tech startups, bringing a wealth of experience and a passion for problem-solving to his entrepreneurial ventures. In the episode, Richie and Taylor explore the biggest challenges in data engineering, how to find the right tools for your data stack, defining the modern data stack, federated data, data fabrics, data meshes, data strategy vs organizational structure, self-service data, data democratization, AI’s impact on data and much more. Links Mentioned in the Show: FivetranConnect with TaylorCareer Track: Data Engineer in PythonRelated Episode: Effective Data Engineering with Liya Aizenberg, Director of Data Engineering at AwayRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
Generative AI's transformative power underscores the critical need for high-quality data. In this session, Barr Moses, CEO of Monte Carlo Data, Prukalpa Sankar, Cofounder at Atlan, and George Fraser, CEO at Fivetran, discuss the nuances of scaling data quality for generative AI applications, highlighting the unique challenges and considerations that come into play. Throughout the session, they share best practices for data and AI leaders to navigate these challenges, ensuring that governance remains a focal point even amid the AI hype cycle. Links Mentioned in the Show: Rewatch Session from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile app Empower your business with world-class data and AI skills with DataCamp for business
We talked about:
Adrian’s background The benefits of freelancing Having an agency vs freelancing What let Adrian switch over from freelancing The conception of DLT (Growth Full Stack) The investment required to start a company Growth through the provision of services Growth through teaching (product-market fit) Moving on to creating docs Adrian’s current role Strategic partnerships and community growth through DocDB Plans for the future of DLT DLT vs Airbyte vs Fivetran Adrian’s resource recommendations
Links:
Adrian's LinkedIn: https://www.linkedin.com/in/data-team/ Twitter: https://twitter.com/dlt_library Github: https://github.com/dlt-hub/dlt Website: https://dlthub.com/docs/intro
Free ML Engineering course: http://mlzoomcamp.com Join DataTalks.Club: https://datatalks.club/slack.html Our events: https://datatalks.club/events.html

In this session, Vida Health’s senior director of data, mobile, and web engineering shares a story that can help other data and business leaders capitalize on the opportunities being created by current technology innovations, market realities, and real-world problems. This includes a playbook on how Vida Health uses modern data technologies like dbt Cloud, Fivetran, Looker, BigQuery, BigQueryML/dbtML, Vertex AI, LLMs, and more to put data in the driver’s seat to solve meaningful problems in complex industries like healthcare.
Speaker: Trenton Huey, Senior Director, Data and Frontend Engineering, Vida Health
Register for Coalesce at https://coalesce.getdbt.com
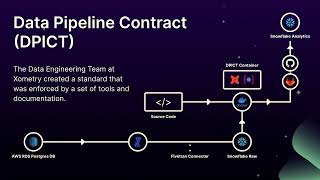
It’s 2023, why are software engineers still breaking analytics reporting? We’ve all been there, being alerted by an analyst or C-level stakeholders, saying “this report is broken”, only to spend hours determining that an engineer deleted a column on the source database that is now breaking your pipeline and reporting.
At Xometry, the data engineering team wanted to fix this problem at its root and give the engineering teams a clear and repeatable process that allowed them to be the owners of their own database data. Xometry named the process DPICT (data pipeline contract) and built several internal tools that integrated seamlessly with their developer’s microservice toolsets.
Their software engineers mostly build their database microservices using Postgres, and bring in the data using Fivetran. Using that as the baseline, the team created a set of tools that would allow the engineers to quickly build the staging layer of their database in the data warehouse (Snowflake), but also alert them of the consequences of removing a table or column in downstream reporting.
In this talk, Jisan shares the nuts and bolts of the designed solution and process that allowed the team to onboard 13 different microservices seamlessly, working with multiple domains and dozens of developers. The process also helped software engineers to own their own data and realize their impact. The team has saved hundreds hours of data engineering time and resources not having to chase down what changed upstream to break data. Overall, this process has helped to bring transparency to the whole data ecosystem.
Speaker: Jisan Zaman, Data Engineering Manager, Xometry
Register for Coalesce at https://coalesce.getdbt.com

In this session, you'll learn tips and tricks from La-Z-Boy on how to modernize infrastructure and tackle complex retail and manufacturing data problems using dbt and Fivetran. Hear from a data leader about their experience and how you can replicate their success. Start your session off with some comfortable data movements to make sure you can extract as much information as possible from our loaded session on data transformation.
Speakers: Alex Hauer, Lead Product Marketing Manager, Fivetran; Selwyn Samuel, Director of Data Analytics & Enterprise Architecture, La-Z-Boy
Register for Coalesce at https://coalesce.getdbt.com
The Fivetran Analytics Engineering team strives to make its dbt packages multi-faceted enough and functional for the majority of data teams, balancing flexibility against ease of implementation. This means that the packages should get you 80% of the way there out of the box, but you're not alone as you cover the final 20%!
Over the years, the team has further developed its understanding of the nuances of analyses and developed different methods for folks to easily tweak packages to their liking. This session will discuss passthrough columns, union macros, and overriding package models, and will teach you how to use these features to make Fivetran's packages work for you or even leverage the same patterns in your own work.
Speaker: Jamie Rodriguez, Senior Analytics Engineer, Fivetran
Register for Coalesce at https://coalesce.getdbt.com
Would you like to know how one of the largest online business insurance organizations in Australia saves 36-72 engineering hours per connector? Watch this session to see how you can influence your business to make quicker and more accurate insights into key business metrics.
Speakers: Alexandra Coffey, Account Executive, Fivetran; Jimmo Vink, Head of Information Management, BizCover
Register for Coalesce at https://coalesce.getdbt.com/
Summary
Cloud data warehouses and the introduction of the ELT paradigm has led to the creation of multiple options for flexible data integration, with a roughly equal distribution of commercial and open source options. The challenge is that most of those options are complex to operate and exist in their own silo. The dlt project was created to eliminate overhead and bring data integration into your full control as a library component of your overall data system. In this episode Adrian Brudaru explains how it works, the benefits that it provides over other data integration solutions, and how you can start building pipelines today.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Your host is Tobias Macey and today I'm interviewing Adrian Brudaru about dlt, an open source python library for data loading
Interview
Introduction How did you get involved in the area of data management? Can you describe what dlt is and the story behind it?
What is the problem you want to solve with dlt? Who is the target audience?
The obvious comparison is with systems like Singer/Meltano/Airbyte in the open source space, or Fivetran/Matillion/etc. in the commercial space. What are the complexities or limitations of those tools that leave an opening for dlt? Can you describe how dlt is implemented? What are the benefits of building it in Python? How have the design and goals of the project changed since you first started working on it? How does that language choice influence the performance and scaling characteristics? What problems do users solve with dlt? What are the interfaces available for extending/customizing/integrating with dlt? Can you talk through the process of adding a new source/destination? What is the workflow for someone building a pipeline with dlt? How does the experience scale when supporting multiple connections? Given the limited scope of extract and load, and the composable design of dlt it seems like a purpose built companion to dbt (down to th

In this video you will learn how to use Fivetran to ingest data from Salesforce into your Lakehouse. After the data has been ingested, you will then learn how you can transform your data using dbt. Then we will use Databricks SQL to query, visualize and govern your data. Lastly, we will show you how you can use AI functions in Databricks SQL to call language learning models.
Read more about Databricks SQL https://docs.databricks.com/en/sql/index.html#what-is-databricks-sql