To accelerate growth, the National Rugby League (NRL) aimed to enhance its fan and participant experience. Using Fivetran as the cornerstone of its modern data stack, NRL centralised data with high-performance pipelines, enabling fast, accurate reporting and real-time insights. They successfully built a Single Customer View (SCV), providing a unified understanding of fans and participants. Learn how NRL transforms its data into a strategic asset to enable smarter decisions and long-term impact.
 talk-data.com
talk-data.com
Topic
Modern Data Stack
298
tagged
Activity Trend
28
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
125
Databricks DATA + AI Summit 2023
16
dbt Coalesce 2022
16
O'Reilly Data Engineering Books
15
dbt Coalesce 2023
13
DataFramed
13
The Analytics Engineering Podcast
10
The Joe Reis Show
9
Data Council 2023
5
Making Data Simple
5
Modern Data Stack Conference 2023
5
Modern Data Stack Conference 2021
5
The modern data stack has transformed how organizations work with data, but are our BI tools keeping pace with these changes? As data schemas become increasingly fluid and analysis needs range from quick explorations to production-grade reporting, traditional approaches are being challenged. How can we create analytics experiences that accommodate both casual spreadsheet users and technical data modelers? With semantic layers becoming crucial for AI integration and data governance growing in importance, what skills do today's BI professionals need to master? Finding the balance between flexibility and governance is perhaps the greatest challenge facing data teams today. Colin Zima is the Co-Founder and CEO of Omni, a business intelligence platform focused on making data more accessible and useful for teams of all sizes. Prior to Omni, he was Chief Analytics Officer and VP of Product at Looker, where he helped shape the product and data strategy leading up to its acquisition by Google for $2.6 billion. Colin’s background spans roles in data science, analytics, and product leadership, including positions at Google, HotelTonight, and as founder of the restaurant analytics startup PrimaTable. He holds a degree in Operations Research and Financial Engineering from Princeton University and began his career as a Structured Credit Analyst at UBS. In the episode, Richie and Colin explore the evolution of BI tools, the challenges of integrating casual and rigorous data analysis, the role of semantic layers, and the impact of AI on business intelligence. They discuss the importance of understanding business needs, creating user-focused dashboards, and the future of data products, and much more. Links Mentioned in the Show: OmniConnect with ColinSkill Track: Design in Power BIRelated Episode: Self-Service Business Intelligence with Sameer Al-Sakran, CEO at MetabaseRegister for RADAR AI - June 26 New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business

AI initiatives often stall when data teams can’t keep up with business demand for ad hoc, self-service data. Whether it’s AI agents, BI tools, or business users—everyone needs data immediately, but the pipeline-centric modern data stack is not built for this scale of agility. Promethium enables the data teams to generate instant, contextual data products called Data Answers based on rapid, exploratory questions from the business. Data Answers empower data teams for AI-scale collaboration with the business. We will demo Promethium’s new agent capability to build data answers on Databricks for self-service data. The Promethium agent leverages and extends Genie with context from other enterprise data and applications to ensure accuracy and relevance.

Despite the proliferation of cloud data warehousing, BI tools, and AI, spreadsheets are still the most ubiquitous data tool. Business teams in finance, operations, sales, and marketing often need to analyze data in the cloud data warehouse but don't know SQL and don't want to learn BI tools. AI tools offer a new paradigm but still haven't broadly replaced the spreadsheet. With new AI tools and legacy BI tools providing business teams access to data inside Databricks, security and governance are put at risk. In this session, Row Zero CEO, Breck Fresen, will share examples and strategies data teams are using to support secure spreadsheet analysis at Fortune 500 companies and the future of spreadsheets in the world of AI. Breck is a former Principal Engineer from AWS S3 and was part of the team that wrote the S3 file system. He is an expert in storage, data infrastructure, cloud computing, and spreadsheets.

Getting started with data and AI governance in the modern data stack? Unity Catalog is your gateway to secure, discoverable and well-governed data and AI assets. In this session, we’ll break down what Unity Catalog is, why it matters and how it simplifies access control, lineage, discovery, auditing, business semantics and secure, open collaboration — all from a single place. We’ll explore how it enables open interoperability across formats, tools and platforms, helping you avoid lock-in and build on open standards. Most importantly, you’ll learn how Unity Catalog lays the foundation for data intelligence — by unifying governance across data and AI, enabling AI tuned to your business. It helps build a deep understanding of your data and delivers contextual, domain-specific insights that boost productivity for both technical and business users across any workload.
Summary In this episode of the Data Engineering Podcast, host Tobias Macy welcomes back Shinji Kim to discuss the evolving role of semantic layers in the era of AI. As they explore the challenges of managing vast data ecosystems and providing context to data users, they delve into the significance of semantic layers for AI applications. They dive into the nuances of semantic modeling, the impact of AI on data accessibility, and the importance of business logic in semantic models. Shinji shares her insights on how SelectStar is helping teams navigate these complexities, and together they cover the future of semantic modeling as a native construct in data systems. Join them for an in-depth conversation on the evolving landscape of data engineering and its intersection with AI.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Your host is Tobias Macey and today I'm interviewing Shinji Kim about the role of semantic layers in the era of AIInterview IntroductionHow did you get involved in the area of data management?Semantic modeling gained a lot of attention ~4-5 years ago in the context of the "modern data stack". What is your motivation for revisiting that topic today?There are several overlapping concepts – "semantic layer," "metrics layer," "headless BI." How do you define these terms, and what are the key distinctions and overlaps?Do you see these concepts converging, or do they serve distinct long-term purposes?Data warehousing and business intelligence have been around for decades now. What new value does semantic modeling beyond practices like star schemas, OLAP cubes, etc.?What benefits does a semantic model provide when integrating your data platform into AI use cases?How is it different between using AI as an interface to your analytical use cases vs. powering customer facing AI applications with your data?Putting in the effort to create and maintain a set of semantic models is non-zero. What role can LLMs play in helping to propose and construct those models?For teams who have already invested in building this capability, what additional context and metadata is necessary to provide guidance to LLMs when working with their models?What's the most effective way to create a semantic layer without turning it into a massive project? There are several technologies available for building and serving these models. What are the selection criteria that you recommend for teams who are starting down this path?What are the most interesting, innovative, or unexpected ways that you have seen semantic models used?What are the most interesting, unexpected, or challenging lessons that you have learned while working with semantic modeling?When is semantic modeling the wrong choice?What do you predict for the future of semantic modeling?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links SelectStarSun MicrosystemsMarkov Chain Monte CarloSemantic ModelingSemantic LayerMetrics LayerHeadless BICubePodcast EpisodeAtScaleStar SchemaData VaultOLAP CubeRAG == Retrieval Augmented GenerationAI Engineering Podcast EpisodeKNN == K-Nearest NeighbersHNSW == Hierarchical Navigable Small Worlddbt Metrics LayerSoda DataLookMLHexPowerBITableauSemantic View (Snowflake)Databricks GenieSnowflake Cortex AnalystMalloyThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
AI initiatives often stall when data teams can’t keep up with business demand for fast, self-service data. Whether it’s AI agents, BI tools, or business users—everyone needs data, but the pipeline-centric modern data stack wasn’t built for this kind of agility. In this session, learn about how an Instant Data Fabric enables data teams for self-service at AI scale by instantly generating contextual Data Answers from distributed enterprise data for consumption by business teams. Discover how leading organizations are using this new data architecture to accelerate AI adoption without comprising governance and control.

In this podcast episode, we talked with Adrian Brudaru about the past, present and future of data engineering.
About the speaker: Adrian Brudaru studied economics in Romania but soon got bored with how creative the industry was, and chose to go instead for the more factual side. He ended up in Berlin at the age of 25 and started a role as a business analyst. At the age of 30, he had enough of startups and decided to join a corporation, but quickly found out that it did not provide the challenge he wanted. As going back to startups was not a desirable option either, he decided to postpone his decision by taking freelance work and has never looked back since. Five years later, he co-founded a company in the data space to try new things. This company is also looking to release open source tools to help democratize data engineering.
0:00 Introduction to DataTalks.Club 1:05 Discussing trends in data engineering with Adrian 2:03 Adrian's background and journey into data engineering 5:04 Growth and updates on Adrian's company, DLT Hub 9:05 Challenges and specialization in data engineering today 13:00 Opportunities for data engineers entering the field 15:00 The "Modern Data Stack" and its evolution 17:25 Emerging trends: AI integration and Iceberg technology 27:40 DuckDB and the emergence of portable, cost-effective data stacks 32:14 The rise and impact of dbt in data engineering 34:08 Alternatives to dbt: SQLMesh and others 35:25 Workflow orchestration tools: Airflow, Dagster, Prefect, and GitHub Actions 37:20 Audience questions: Career focus in data roles and AI engineering overlaps 39:00 The role of semantics in data and AI workflows 41:11 Focusing on learning concepts over tools when entering the field 45:15 Transitioning from backend to data engineering: challenges and opportunities 47:48 Current state of the data engineering job market in Europe and beyond 49:05 Introduction to Apache Iceberg, Delta, and Hudi file formats 50:40 Suitability of these formats for batch and streaming workloads 52:29 Tools for streaming: Kafka, SQS, and related trends 58:07 Building AI agents and enabling intelligent data applications 59:09Closing discussion on the place of tools like DBT in the ecosystem
🔗 CONNECT WITH ADRIAN BRUDARU Linkedin - / data-team Website - https://adrian.brudaru.com/ 🔗 CONNECT WITH DataTalksClub Join the community - https://datatalks.club/slack.html Subscribe to our Google calendar to have all our events in your calendar - https://calendar.google.com/calendar/... Check other upcoming events - https://lu.ma/dtc-events LinkedIn - /datatalks-club Twitter - /datatalksclub Website - https://datatalks.club/
Summary In this episode of the Data Engineering Podcast Gleb Mezhanskiy, CEO and co-founder of DataFold, talks about the intersection of AI and data engineering. He discusses the challenges and opportunities of integrating AI into data engineering, particularly using large language models (LLMs) to enhance productivity and reduce manual toil. The conversation covers the potential of AI to transform data engineering tasks, such as text-to-SQL interfaces and creating semantic graphs to improve data accessibility, and explores practical applications of LLMs in automating code reviews, testing, and understanding data lineage.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details. Your host is Tobias Macey and today I'm interviewing Gleb Mezhanskiy about Interview IntroductionHow did you get involved in the area of data management?modern data stack is deadwhere is AI in the data stack?"buy our tool to ship AI"opportunities for LLM in DE workflowContact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links DatafoldCopilotCursor IDEAI AgentsDataChatAI Engineering Podcast EpisodeMetrics LayerEmacsLangChainLangGraphCrewAIThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Bogdan Banu, Data Engineering Manager at Veed.io, joined Yuliia to share his journey of building a data platform from scratch at a fast-growing startup. As Veed's first data hire, Bogdan discusses how he established a modern data stack while maintaining strong governance principles and cost consciousness. Bogdan covered insights on implementing consent-based video data processing for AI initiatives, approaches to data democratization, and how his data team balancs velocity with security. Bogdan shared his perspectives on making strategic vendor choices, measuring business value, and fostering a culture of intelligent experimentation in startup environments.Bogdan's Linkedin - https://www.linkedin.com/in/bogdan-banu-a68a237/
This morning, a great article came across my feed that gave me PTSD, asking if Iceberg is the Hadoop of the Modern Data Stack?
In this rant, I bring the discussion back to a central question you should ask with any hot technology - do you need it at all? Do you need a tool built for the top 1% of companies at a sufficient data scale? Or is a spreadsheet good enough?
Link: https://blog.det.life/apache-iceberg-the-hadoop-of-the-modern-data-stack-c83f63a4ebb9
❤️ If you like my podcasts, please like and rate it on your favorite podcast platform.
🤓 My works:
📕Fundamentals of Data Engineering: https://www.oreilly.com/library/view/fundamentals-of-data/9781098108298/
🎥 Deeplearning.ai Data Engineering Certificate: https://www.coursera.org/professional-certificates/data-engineering
🔥Practical Data Modeling: https://practicaldatamodeling.substack.com/
🤓 My SubStack: https://joereis.substack.com/

🌟 Session Overview 🌟
Session Name: Open Source Entity Resolution - Needs and Challenges Speaker: Sonal Goyal Session Description: Real world data contains multiple records belonging to the same customer. These records can be in single or multiple systems and they have variations across fields, which makes it hard to combine them together, especially with growing data volumes. This hurts customer analytics - establishing lifetime value, loyalty programs, or marketing channels is impossible when the base data is not linked. No AI algorithm for segmentation can produce the right results when there are multiple copies of the same customer lurking in the data. No warehouse can live up to its promise if the dimension tables have duplicates.
With a modern data stack and DataOps, we have established patterns for E and L in ELT for building data warehouses, datalakes and deltalakes. However, the T - getting data ready for analytics still needs a lot of effort. Modern tools like dbt are actively and successfully addressing this. What is also needed is a quick and scalable way to resolve entities to build the single source of truth of core business entities post Extraction and pre or post Loading.
This session would cover the problem of Entity Resolution, its practical applications and challenges in building an entity resolution system. It will also cover Zingg - an Open Source Framework for building Entity Resolution systems. (https://github.com/zinggAI/zingg/) 🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape. Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀 Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts. Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀 🔗 Find Other Years' Videos: 2023 Big Data Conference Europe https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g 2022 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT 2021 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/ 👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/ 🐦 Twitter: @BigDataConfEU, @europe_rpa 🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/ 🎥 YouTube: http://www.youtube.com/@DATAMINERLT

As a Head of Data or a one-person data team, keeping the lights on for the business while running all things data-related as efficiently as possible is no small feat. This talk will focus on tactics and strategies to manage within and around constraints, including monetary costs, time and resources, and data volumes.
📓 Resources Big Data is Dead: https://motherduck.com/blog/big-data-... Small Data Manifesto: https://motherduck.com/blog/small-dat... Why Small Data?: https://benn.substack.com/p/is-excel-... Small Data SF: https://www.smalldatasf.com/
➡️ Follow Us
LinkedIn: / motherduck
X/Twitter : / motherduck
Blog: https://motherduck.com/blog/
Learn how your data team can drive innovation and maximize ROI by embracing constraints, drawing inspiration from SpaceX's revolutionary cost-effective approach. This video challenges the "abundance mindset" prevalent in the modern data stack, where easily scalable cloud data warehouses and a surplus of tools often lead to unmanageable data models and underutilized dashboards. We explore a focused data strategy for extracting maximum value from small data, shifting the paradigm from "more data" to more impact.
To maximize value, data teams must move beyond being order-takers and practice strategic stakeholder management. Discover how to use frameworks like the stakeholder engagement matrix to prioritize high-impact business leaders and align your work with core business goals. This involves speaking the language of business growth models, not technical jargon about data pipelines or orchestration, ensuring your data engineering efforts resonate with key decision-makers and directly contribute to revenue-generating activities.
Embracing constraints is key to innovation and effective data project management. We introduce the Iron Triangle—a fundamental engineering concept balancing scope, cost, and time—as a powerful tool for planning data projects and having transparent conversations with the business. By treating constraints not as limitations but as opportunities, data engineers and analysts can deliver higher-quality data products without succumbing to scope creep or uncontrolled costs.
A critical component of this strategy is understanding the Total Cost of Ownership (TCO), which goes far beyond initial compute costs to include ongoing maintenance, downtime, and the risk of vendor pricing changes. Learn how modern, efficient tools like DuckDB and MotherDuck are designed for cost containment from the ground up, enabling teams to build scalable, cost-effective data platforms. By making the true cost of data requests visible, you can foster accountability and make smarter architectural choices. Ultimately, this guide provides a blueprint for resisting data stack bloat and turning cost and constraints into your greatest assets for innovation.

This is a talk about how we thought we had Big Data, and we built everything planning for Big Data, but then it turns out we didn't have Big Data, and while that's nice and fun and seems more chill, it's actually ruining everything, and I am here asking you to please help us figure out what we are supposed to do now.
📓 Resources Big Data is Dead: https://motherduck.com/blog/big-data-... Small Data Manifesto: https://motherduck.com/blog/small-dat... Is Excel Immortal?: https://benn.substack.com/p/is-excel-immortal Small Data SF: https://www.smalldatasf.com/
➡️ Follow Us
LinkedIn: / motherduck
X/Twitter : / motherduck
Blog: https://motherduck.com/blog/
Mode founder David Wheeler challenges the data industry's obsession with "big data," arguing that most companies are actually working with "small data," and our tools are failing us. This talk deconstructs the common sales narrative for BI tools, exposing why the promise of finding game-changing insights through data exploration often falls flat. If you've ever built dashboards nobody uses or wondered why your analytics platform doesn't deliver on its promises, this is a must-watch reality check on the modern data stack.
We explore the standard BI demo, where an analyst uncovers a critical insight by drilling into event data. This story sells tools like Tableau and Power BI, but it rarely reflects reality, leading to a "revolving door of BI" as companies swap tools every few years. Discover why the narrative of the intrepid analyst finding a needle in the haystack only works in movies and how this disconnect creates a cycle of failed data initiatives and unused "trashboards."
The presentation traces our belief that "data is the new oil" back to the early 2010s, with examples from Target's predictive analytics and Facebook's growth hacking. However, these successes were built on truly massive datasets. For most businesses, analyzing small data results in noisy charts that offer vague "directional vibes" rather than clear, actionable insights. We contrast the promise of big data analytics with the practical challenges of small data interpretation.
Finally, learn actionable strategies for extracting real value from the data you actually have. We argue that BI tools should shift focus from data exploration to data interpretation, helping users understand what their charts actually mean. Learn why "doing things that don't scale," like manually analyzing individual customer journeys, can be more effective than complex models for small datasets. This talk offers a new perspective for data scientists, analysts, and developers looking for better data analysis techniques beyond the big data hype.
Summary The challenges of integrating all of the tools in the modern data stack has led to a new generation of tools that focus on a fully integrated workflow. At the same time, there have been many approaches to how much of the workflow is driven by code vs. not. Burak Karakan is of the opinion that a fully integrated workflow that is driven entirely by code offers a beneficial and productive means of generating useful analytical outcomes. In this episode he shares how Bruin builds on those opinions and how you can use it to build your own analytics without having to cobble together a suite of tools with conflicting abstractions.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Burak Karakan about the benefits of building code-only data systemsInterview IntroductionHow did you get involved in the area of data management?Can you describe what Bruin is and the story behind it?Who is your target audience?There are numerous tools that address the ETL workflow for analytical data. What are the pain points that you are focused on for your target users?How does a code-only approach to data pipelines help in addressing the pain points of analytical workflows?How might it act as a limiting factor for organizational involvement?Can you describe how Bruin is designed?How have the design and scope of Bruin evolved since you first started working on it?You call out the ability to mix SQL and Python for transformation pipelines. What are the components that allow for that functionality?What are some of the ways that the combination of Python and SQL improves ergonomics of transformation workflows?What are the key features of Bruin that help to streamline the efforts of organizations building analytical systems?Can you describe the workflow of someone going from source data to warehouse and dashboard using Bruin and Ingestr?What are the opportunities for contributions to Bruin and Ingestr to expand their capabilities?What are the most interesting, innovative, or unexpected ways that you have seen Bruin and Ingestr used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on Bruin?When is Bruin the wrong choice?What do you have planned for the future of Bruin?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links BruinFivetranStitchIngestrBruin CLIMeltanoSQLGlotdbtSQLMeshPodcast EpisodeSDFPodcast EpisodeAirflowDagsterSnowparkAtlanEvidenceThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Martin Fiser, Field CTO at Keboola with 8 years at Google, joined Yuliia and Scott to challenge modern data stack complexity and costs. He advocates for all-in-one platforms over fragmented solutions, highlighting how companies waste up to 40% of time on tool integration. Martin shared insights on US-European cultural differences in data approaches and warned against "development by resume" culture where engineers prioritize trendy tools over business outcomes.

Riot Games, creator of hit titles like League of Legends and Valorant, is building an ultimate gaming experience by using data and AI to deliver the most optimal player journeys. In this session, you'll learn how Riot's data platform team paired with analytics engineering, machine learning, and insights teams to integrate Databricks Data Intelligence Platform and dbt Cloud to significantly mature its data capabilities. The outcome: a scalable, collaborative analytics environment that serves millions of players worldwide.
You’ll hear how Riot Games: - Centralized petabytes of game telemetry on Databricks for fast processing and analytics - Modernized their data platform by integrating dbt Cloud, unlocking governance for modular, version-controlled data transformations and testing for a diverse set of user personas - Uses Generative AI to automate the enforcement of good documentation and quality code and plans to use Databricks AI to further speed up its ability to unlock the value of data - Deployed machine learning models for personalized recommendations and player behavior analysis
You'll come away with practical insights on architecting a modern data stack that can handle massive scale while empowering teams across the organization. Whether you're in gaming or any data-intensive industry, you'll learn valuable lessons from Riot's journey to build a world-class data platform.
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
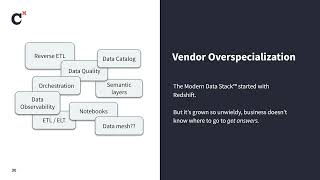
The modern data stack has improved the lives of data teams everywhere. But has it helped the rest of the business? In this talk, we’ll discuss the business teams’ perspective. Are they actually getting value from the modern data stack? How does help it them do their jobs better? And why do data teams keep questioning if we’re “adding value” with our powerful new tools? Attendees will gain perspective on their data ‘customers’ and learn ideas on how to deliver tangible business value.
Speaker: Paul Blankley CTO Zenlytic
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
Businesses are constantly racing to stay ahead by adopting the latest data tools and AI technologies. But with so many options and buzzwords, it’s easy to get lost in the excitement without knowing whether these tools truly serve your business. How can you ensure that your data stack is not only modern but sustainable and agile enough to adapt to changing needs? What does it take to build data products that deliver real value to your teams while driving innovation? Adrian Estala is VP, Field Chief Data Officer and the host of Starburst TV. With a background in leading Digital and IT Portfolio Transformations, he understands the value of creating executive frameworks that focus on material business outcomes. Skilled with getting the most out of data-driven investments, Adrian is your trusted adviser to navigating complex data environments and integrating a Data Mesh strategy in your organization. In the episode, Richie and Adrian explore the modern data stack, agility in data, collaboration between business and data teams, data products and differing ways of building them, data discovery and metadata, data quality, career skills for data practitioners and much more. Links Mentioned in the Show: StarburstConnect with AdrianCareer Track: Data Engineer in PythonRelated Episode: How this Accenture CDO is Navigating the AI RevolutionRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business