No matter how fancy your modern data stack is, managers still use Spreadsheets!
 talk-data.com
talk-data.com
Topic
Modern Data Stack
298
tagged
Activity Trend
28
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
125
Databricks DATA + AI Summit 2023
16
dbt Coalesce 2022
16
O'Reilly Data Engineering Books
15
dbt Coalesce 2023
13
DataFramed
13
The Analytics Engineering Podcast
10
The Joe Reis Show
9
Data Council 2023
5
Making Data Simple
5
Modern Data Stack Conference 2023
5
Modern Data Stack Conference 2021
5
Summary
Databases and analytics architectures have gone through several generational shifts. A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. In this episode Tasso Argyros, CEO of ActionIQ, gives a summary of the major epochs in database technologies and how he is applying the capabilities of cloud data warehouses to the challenge of building more comprehensive experiences for end-users through a modern customer data platform (CDP).
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Data projects are notoriously complex. With multiple stakeholders to manage across varying backgrounds and toolchains even simple reports can become unwieldy to maintain. Miro is your single pane of glass where everyone can discover, track, and collaborate on your organization's data. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro. Your first three Miro boards are free when you sign up today at dataengineeringpodcast.com/miro. That’s three free boards at dataengineeringpodcast.com/miro. Your host is Tobias Macey and today I'm interviewing Tasso Argyros about the role of a customer data platform in the context of the modern data stack
Interview
Introduction How did you get involved in the area of data management? Can you describe what the role of the CDP is in the context of a businesses data ecosystem?
What are the core technical challenges associated with building and maintaining a CDP? What are the organizational/business factors that contribute to the complexity of these systems?
The early days of CDPs came with the promise of "Customer 360". Can you unpack that concept and how it has changed over the past ~5 years? Recent years have seen the adoption of reverse ETL, cloud data warehouses, and sophisticated product analytics suites. How has that changed the architectural approach to CDPs?
How have the architectural shifts changed the ways that organizations interact with their customer data?
How have the responsibilities shifted across different roles?
What are the governance policy and enforcement challenges that are added with the expansion of access and responsibility?
What are the most interesting, innovative, or unexpected ways that you have seen CDPs built/used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on CDPs? When is a CDP the wrong choice? What do you have planned for the future of ActionIQ?
Contact Info
LinkedIn @Tasso on Twitter
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being us
Summary
The "modern data stack" promised a scalable, composable data platform that gave everyone the flexibility to use the best tools for every job. The reality was that it left data teams in the position of spending all of their engineering effort on integrating systems that weren't designed with compatible user experiences. The team at 5X understand the pain involved and the barriers to productivity and set out to solve it by pre-integrating the best tools from each layer of the stack. In this episode founder Tarush Aggarwal explains how the realities of the modern data stack are impacting data teams and the work that they are doing to accelerate time to value.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm welcoming back Tarush Aggarwal to talk about what he and his team at 5x data are building to improve the user experience of the modern data stack.
Interview
Introduction How did you get involved in the area of data management? Can you describe what 5x is and the story behind it?
We last spoke in March of 2022. What are the notable changes in the 5x business and product?
What are the notable shifts in the data ecosystem that have influenced your adoption and product direction?
What trends are you most focused on tracking as you plan the continued evolution of your offerings?
What are the points of friction that teams run into when trying to build their data platform? Can you describe design of the system that you have built?
What are the strategies that you rely on to support adaptability and speed of onboarding for new integrations?
What are some of the types of edge cases that you have to deal with while integrating and operating the platform implementations that you design for your customers? What is your process for selection of vendors to support?
How would you characte
Summary
Software development involves an interesting balance of creativity and repetition of patterns. Generative AI has accelerated the ability of developer tools to provide useful suggestions that speed up the work of engineers. Tabnine is one of the main platforms offering an AI powered assistant for software engineers. In this episode Eran Yahav shares the journey that he has taken in building this product and the ways that it enhances the ability of humans to get their work done, and when the humans have to adapt to the tool.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Your host is Tobias Macey and today I'm interviewing Eran Yahav about building an AI powered developer assistant at Tabnine
Interview
Introduction How did you get involved in machine learning? Can you describe what Tabnine is and the story behind it? What are the individual and organizational motivations for using AI to generate code?
What are the real-world limitations of generative AI for creating software? (e.g. size/complexity of the outputs, naming conventions, etc.) What are the elements of skepticism/overs
Summary
Databases are the core of most applications, but they are often treated as inscrutable black boxes. When an application is slow, there is a good probability that the database needs some attention. In this episode Lukas Fittl shares some hard-won wisdom about the causes and solution of many performance bottlenecks and the work that he is doing to shine some light on PostgreSQL to make it easier to understand how to keep it running smoothly.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Your host is Tobias Macey and today I'm interviewing Lukas Fittl about optimizing your database performance and tips for tuning Postgres
Interview
Introduction How did you get involved in the area of data management? What are the different ways that database performance problems impact the business? What are the most common contributors to performance issues? What are the useful signals that indicate performance challenges in the database?
For a given symptom, what are the steps that you recommend for determining the proximate cause?
What are the potential negative impacts to be aware of when tu
Summary
Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. In this episode Tanya Bragin shares her experiences as a product manager for two major vendors and the lessons that she has learned about how teams should approach the process of tool selection.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Data projects are notoriously complex. With multiple stakeholders to manage across varying backgrounds and toolchains even simple reports can become unwieldy to maintain. Miro is your single pane of glass where everyone can discover, track, and collaborate on your organization's data. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro. Your first three Miro boards are free when you sign up today at dataengineeringpodcast.com/miro. That’s three free boards at dataengineeringpodcast.com/miro. Your host is Tobias Macey and today I'm interviewing Tanya Bragin about her views on the database products market
Interview
Introduction How did you get involved in the area of data management? What are the aspects of the database market that keep you interested as a VP of product?
How have your experiences at Elastic informed your current work at Clickhouse?
What are the main product categories for databases today?
What are the industry trends that have the most impact on the development and growth of different product categories? Which categories do you see growing the fastest?
When a team is selecting a database technology for a given task, what are the types of questions that they should be asking? Transactional engines like Postgres, SQL Server, Oracle, etc. were long used
Behind any good DataOps within a Modern Data Stack (MDS) architecture is a solid DevOps design! This is particularly pressing when building an MDS solution at scale, as reliability, quality and availability of data requires a very high degree of process automation while remaining fast, agile and resilient to change when addressing business needs.
While DevOps in Data Engineering is nothing new - for a broad-spectrum solution that includes data warehouse, BI, etc seemed either a bit out of reach due to overall complexity and cost - or simply overlooked due to perceived issues around scaling often attributed to the challenges of automation in CI/CD processes. However, this has been fast changing with tools such as dbt having super cool features which allow a very high degree of autonomy in the CI/CD processes with relative ease, with flexible and cutting edge features around pre-commits, Slim CI, etc.
In this session, Datatonic covers the challenges around building and deploying enterprise-grade MDS solutions for analytics at scale and how they have used dbt to address those - especially around near-complete autonomy to the CI/CD processes!
Speaker: Ash Sultan, Lead Data Architect, Datatonic
Register for Coalesce at https://coalesce.getdbt.com

There’s a lot of decisions that need to be made throughout the initial deployment, migration to and scaling of the data stack. The decisions can be big or small, hard to reverse or trivial. When looking back at Zip’s modernization journey, there’s some things that the team nailed and others that they’d definitely do differently if they were to do it again. In this talk, the Zip team goes through the principles they used to make decisions when building out their stack, the challenges that they faced, the solutions that they landed on, and their learnings.
Speaker: Moss Pauly, Senior Manager Data Products, Zip
Register for Coalesce at https://coalesce.getdbt.com

As Joe Reis recently opined, if you want to know what’s next in data engineering, just look at the software engineer. The MDS-in-a-box pattern has been a game changer for applying software engineering principles to local data development– improving the ability to share data, collaborate on modeling work and data analysis the same way we build and share open source tooling.
This panel brings together experts in data engineering, data analytics and software engineering to explore the current state of the pattern, pieces that remain missing today and how emerging tools and data engineering testing capabilities can refine the transition from local development to production workflows.
Speakers: Matt Housley, CTO, Halfpipe Systems; Mehdi Ouazza, Developer Advocate, MotherDuck; Sung Won Chung, Solutions Engineer, Datafold; Louise de Leyritz, Host, The Data Couch podcast
Register for Coalesce at https://coalesce.getdbt.com

Learn about Watercare's journey in implementing a modern data stack with a focus on self serving analytics in the water industry. The session covers the reasons behind Watercare's decision to implement a modern data stack, the problem of data conformity, and the tools they used to accelerate their data modeling process. Diego also discusses the benefits of using dbt, Snowflake, and Azure DevOps in data modeling. There is also a parallel drawn between analytics and Diego’s connection with jazz music.
Speaker: Diego Morales, Civil Industrial Engineer, Watercare
Register for Coalesce at https://coalesce.getdbt.com
In this presentation, Sarah and Darren discuss RMIT University's journey to implementing the modern data stack with dbt. They bring tales of their musical successes and misadventures, lessons learned with both music and data engineering, and how these seemingly disparate worlds overlap.
Speakers: Darren Ware, Senior Data Engineer, RMIT University; Sarah Taylor, Lead Data Engineer, RMIT University
Register for Coalesce at https://coalesce.getdbt.com

Florence is in the business of healthcare staffing. It is an incredibly outdated industry but with the help of the modern data stack, Florence has been able to make people's lives easier. Here is an overview on the challenges and tactics on how the team at Florence overcame them.
Speakers: Monica Youn, Chief Analytics Officer, Florence; Daniel Ferguson, Data Engineer, Florence
Register for Coalesce at https://coalesce.getdbt.com
With dbt and the modern data stack, onboarding and surfacing data has never been more manageable for analytics engineers. Still, 85% of data products never make it into production. Why do data practitioners struggle to create data products that engage the people who actually use them?
Join Jake and Nate as they discuss how integration and collaboration can drive user engagement, ultimately leading to increased adoption. They’ll present guiding principles and three real world examples of data products designed to center and empower business users to: - Replace the need for seeds using materialized Sigma input tables - Create and manage HubSpot contacts and segments using Sigma’s HubSpot template - Sync insights from Sigma directly to downstream systems using the Hightouch integration.
The lessons learned from building a data platform at Sigma will provide everyone a framework for fostering collaboration between data teams and business users so they can raid insights, move up the leaderboard, and level up their gameplay no matter what data stack they use.
Speakers: Nate Meinzer, Director of Partner Engineering, Sigma Computing; Jake Hannan, Senior Manager, Data Platform, Sigma Computing
Register for Coalesce at https://coalesce.getdbt.com
During the data team's short tenure (2.5 years) at ClickUp, they have built and scaled a fully modern data stack and implemented a warehouse-first data strategy. ClickUp's data is comprised of thousands of dbt models and upstream/downstream integrations with nearly every software at ClickUp. ClickUp uses dbt Cloud and Snowflake to power dozens of downstream systems with audience creation, marketing optimization, predictive customer lifecycle ML, a PLG/PLS motion, and much more. This session covers the foundational principles ClickUp follows and how warehouse-first thinking has unlocked tremendous value for ClickUp.
Speakers: Marc Stone, Head of Data, ClickUp
Register for Coalesce at https://coalesce.getdbt.com

In this session, gain strategic guidance on how to deploy dbt Cloud seamlessly to a team of 5-85 people. You'll learn best practices across development and automation that will ensure stability and high standards as you scale the number of developers using dbt Cloud and the number of models built up to the low thousands.
This session is a great fit for folks with beginner through intermediate levels of experience with dbt. In basketball terms, this talk covers mid-range shooting skills, but does not go into detail about 3-pointers, let alone half court shots. Likewise, this talk is not for people who are brand new to dbt and aren't familiar with the basic architecture of dbt and the modern data stack.
Speakers: Chris Davis, Senior Staff Engineer, Udemy, Inc.
Register for Coalesce at https://coalesce.getdbt.com

by
Keelan Smithers
(NBA)
,
Jesse McCabe
(Data Clymer)
,
Jared Chavez
(Pacers Sports & Entertainment)
,
Paimon Jaberi
(Seattle Seahawks)
This panel discussion led by Data Clymer brings together data leaders from some of the top professional sports organizations in the U.S. to explore how sports and similar mid-size businesses are leveraging data and analytics engineering best practices to fuel revenue growth, improve business efficiencies, and drive fan engagement.
Speakers: Jesse McCabe, Vice President Marketing, Data Clymer; Keelan Smithers, Data Product Manager, Analytics Engineering, NBA; Paimon Jaberi, Managing Director of Strategy and Analytics, Seattle Seahawks; Jared Chavez, Senior Data Engineer, Pacers Sports & Entertainment
Register for Coalesce at https://coalesce.getdbt.com
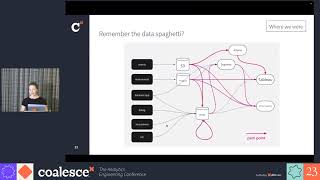
When a startup is in its early stages, the data infrastructure is typically built with the best intentions, but doesn’t necessarily scale, and often predates many modern data tools available today. Years later, you might find yourself juggling complexity and tech debt when providing insights. This talk shares the journey Unbounce embarked on to modernize their data stack, including approaches to the following hurdles: demonstrating value and ROI to leadership for buy-in; deciding which tools to adopt; coordinating with data engineers and data analysts to deliver the cross-team project; and ensuring there were no interruptions to stakeholders throughout the migration.
Speaker: Morgan Cabot, Analytics engineering technical lead, Unbounce
Register for Coalesce at https://coalesce.getdbt.com
In this session, you'll learn about Rebtel's migration journey from a legacy architecture to the modern data stack. Due to the challenges of Rebtel's stack, the data product value was decreasing in the company, it was time to migrate. Learn how the team is using dbt Cloud and Snowflake to achieve greater success in delivering value to the business. You'll leave with a richer understanding of how to plan and execute a legacy migration.
Speaker: Quentin Coviaux, Data Engineer, Rebtel
Register for Coalesce at https://coalesce.getdbt.com

Lauren Benezra has been volunteering with a local cat rescue since 2018. She recently took on the challenge of rebuilding their data stack from scratch, replacing a Jenga tower of incomprehensible Google Sheets with a more reliable system backed by the Modern Data Stack. By using Airtable, Airbyte, BigQuery, dbt Cloud and Census, her role as Foster Coordinator has transformed: instead of digging for buried information while wrangling cats, she now serves up accurate data with ease while... well... wrangling cats.
Viewers will learn that it's possible to run an extremely scalable and reliable stack on a shoestring budget, and will come away with actionable steps to put Lauren's hard-won lessons into practice in their own volunteering projects or as the first data hire in a tiny startup.
Speakers: Lauren Benezra, Senior Analytics Engineer, dbt Labs
Register for Coalesce at https://coalesce.getdbt.com/
Summary
The primary application of data has moved beyond analytics. With the broader audience comes the need to present data in a more approachable format. This has led to the broad adoption of data products being the delivery mechanism for information. In this episode Ranjith Raghunath shares his thoughts on how to build a strategy for the development, delivery, and evolution of data products.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! As more people start using AI for projects, two things are clear: It’s a rapidly advancing field, but it’s tough to navigate. How can you get the best results for your use case? Instead of being subjected to a bunch of buzzword bingo, hear directly from pioneers in the developer and data science space on how they use graph tech to build AI-powered apps. . Attend the dev and ML talks at NODES 2023, a free online conference on October 26 featuring some of the brightest minds in tech. Check out the agenda and register today at Neo4j.com/NODES. This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Your host is Tobias Macey and today I'm interviewing Ranjith Raghunath about tactical elements of a data product strategy
Interview
Introduction How did you get involved in the area of data management? Can you describe what is encompassed by the idea of a data product strategy?
Which roles in an organization need to be involved in the planning and implementation of that strategy?
order of operations:
strategy -> platform design -> implementation/adoption platform implementation -> product strategy -> interface development
managing grain of data in products team organization to support product development/deployment customer communications - what questions to ask? requirements gathering, helping to understand "the art of the possible" What are the most interesting, innovative, or unexpected ways that you have seen organizations approach data product strategies? What are the most interesting, unexpected, or challenging lessons that you have learned while working on