In this episode, Jason Foster talks to Jim Stevenson, an experienced data professional with over 20 years of helping companies grow. Join the conversation to explore the power of data products in driving business growth and learn how cross-functional collaboration and agile strategies can revolutionize your organization's data initiatives.
 talk-data.com
talk-data.com
Topic
Agile/Scrum
project_management
software_development
methodology
561
tagged
Activity Trend
163
peak/qtr
2020-Q1
2026-Q2
Top Events
AWS re:Invent 2024
341
O'Reilly Data Engineering Books
56
O'Reilly Data Science Books
22
Data Engineering Podcast
11
DataTalks.Club
10
Databricks DATA + AI Summit 2023
8
Big Data & AI Paris 2025
8
Data + AI Summit 2025
7
Big Data LDN 2025
6
Secrets of Data Analytics Leaders
6
gartner-data-analytics-apac-2025
5
Experiencing Data w/ Brian T. O’Neill (AI & data product management leadership—powered by UX design)
5

This comprehensive guide, "Data Modeling with Snowflake", is your go-to resource for mastering the art of efficient data modeling tailored to the capabilities of the Snowflake Data Cloud. In this book, you will learn how to design agile and scalable data solutions by effectively leveraging Snowflake's unique architecture and advanced features. What this Book will help me do Understand the core principles of data modeling and how they apply to Snowflake's cloud-native environment. Learn to use Snowflake's features, such as time travel and zero-copy cloning, to create efficient data solutions. Gain hands-on experience with SQL recipes that outline practical approaches to transforming and managing Snowflake data. Discover techniques for modeling structured and semi-structured data for real-world business needs. Learn to integrate universal modeling frameworks like Star Schema and Data Vault into Snowflake implementations for scalability and maintainability. Author(s) The author, Serge Gershkovich, is a seasoned expert in database design and Snowflake architecture. With years of experience in the data management field, Serge has dedicated himself to making complex technical subjects approachable to professionals at all levels. His insights in this book are informed by practical applications and real-world experience. Who is it for? This book is targeted at data professionals, ranging from newcomers to database design to seasoned SQL developers seeking to specialize in Snowflake. If you are looking to understand and apply data modeling practices effectively within Snowflake's architecture, this book is for you. Whether you're refining your modeling skills or getting started with Snowflake, it provides the practical knowledge you need to succeed.
We talked about:
Boyan's background What is data strategy? Due diligence and establishing a common goal Designing a data strategy Impact assessment, portfolio management, and DataOps Data products DataOps, Lean, and Agile Data Strategist vs Data Science Strategist The skills one needs to be a data strategist How does one become a data strategist? Data strategist as a translator Transitioning from a Data Strategist role to a CTO Using ChatGPT as a writing co-pilot Using ChatGPT as a starting point How ChatGPT can help in data strategy Pitching a data strategy to a stakeholder Setting baselines in a data strategy Boyan's book recommendations
Links:
LinkedIn: https://www.linkedin.com/in/angelovboyan/ Twitter: https://twitter.com/thinking_code Github: https://github.com/boyanangelov Website: https://boyanangelov.com/
Free MLOps course: https://github.com/DataTalksClub/mlops-zoomcamp Join DataTalks.Club: https://datatalks.club/slack.html Our events: https://datatalks.club/events.html
A zone-based data refinery creates an agile, adaptable data environment that supports new and unanticipated business requirements quickly. It turns a monolithic data warehouse into a flexible data environment that gracefully adapts to new and unanticipated business requirements while maximizing reuse and standards. Published at: https://www.eckerson.com/articles/how-zone-based-data-processing-turns-your-monolithic-data-warehouse-into-a-flexible-modern-data-architecture
Everybody knows our yellow vans, trucks and planes around the world. But do you know how data drives our business and how we leverage algorithms and technology in our core operations? We will share some “behind the scenes” insights on Deutsche Post DHL Group’s journey towards a Data-Driven Company. • Large-Scale Use Cases: Challenging and high impact Use Cases in all major areas of logistics, including Computer Vision and NLP • Fancy Algorithms: Deep-Neural Networks, TSP Solvers and the standard toolkit of a Data Scientist • Modern Tooling: Cloud Platforms, Kubernetes , Kubeflow, Auto ML • No rusty working mode: small, self-organized, agile project teams, combining state of the art Machine Learning with MLOps best practices • A young, motivated and international team – German skills are only “nice to have” But we have more to offer than slides filled with buzzwords. We will demonstrate our passion for our work, deep dive into our largest use cases that impact your everyday life and share our approach for a timeseries forecasting library - combining data science, software engineering and technology for efficient and easy to maintain machine learning projects..
We talked about:
Shir’s background Debrief culture The responsibilities of a group manager Defining the success of a DS manager The three pillars of data science management Managing up Managing down Managing across Managing data science teams vs business teams Scrum teams, brainstorming, and sprints The most important skills and strategies for DS and ML managers Making sure proof of concepts get into production
Links:
The secret sauce of data science management: https://www.youtube.com/watch?v=tbBfVHIh-38 Lessons learned leading AI teams: https://blogs.intuit.com/2020/06/23/lessons-learned-leading-ai-teams/ How to avoid conflicts and delays in the AI development process (Part I): https://blogs.intuit.com/2020/12/08/how-to-avoid-conflicts-and-delays-in-the-ai-development-process-part-i/ How to avoid conflicts and delays in the AI development process (Part II): https://blogs.intuit.com/2021/01/06/how-to-avoid-conflicts-and-delays-in-the-ai-development-process-part-ii/ Leading AI teams deck: https://drive.google.com/drive/folders/1_CnqjugtsEbkIyOUKFHe48BeRttX0uJG Leading AI teams video: https://www.youtube.com/watch?app=desktop&v=tbBfVHIh-38
Free data engineering course: https://github.com/DataTalksClub/data-engineering-zoomcamp
Join DataTalks.Club: https://datatalks.club/slack.html
Our events: https://datatalks.club/events.html
by
Nadia Nahar
We talked about:
Nadia’s background Academic research in software engineering Design patterns Software engineering for ML systems Problems that people in industry have with software engineering and ML Communication issues and setting requirements Artifact research in open source products Product vs model Nadia’s open source product dataset Failure points in machine learning projects Finding solutions to issues using Nadia’s dataset and experience The problem of siloing data scientists and other structure issues The importance of documentation and checklists Responsible AI How data scientists and software engineers can work in an Agile way
Links:
Model Card: https://arxiv.org/abs/1810.03993 Datasheets: https://arxiv.org/abs/1803.09010 Factsheets: https://arxiv.org/abs/1808.07261 Research Paper: https://www.cs.cmu.edu/~ckaestne/pdf/icse22_seai.pdf Arxiv version: https://arxiv.org/pdf/2110.
Free data engineering course: https://github.com/DataTalksClub/data-engineering-zoomcamp
Join DataTalks.Club: https://datatalks.club/slack.html
Our events: https://datatalks.club/events.html
Data leaders play a critical role in driving innovation and growth in various industries, and this is particularly true in highly regulated industries such as aviation. In such industries, data leaders face unique challenges and opportunities, working to balance the need for innovation with strict regulatory requirements. This week’s guest is Derek Cedillo, who has 27 years of experience working in Data and Analytics at GE Aerospace. Derek currently works as a Senior Manager for GE Aerospace’s Remote Monitoring and Diagnostics division, having previously worked as the Senior Director for Data Science and Analytics. In the episode, Derek shares the key components to successfully managing a Data Science program within a large and highly regulated organization. He also shares his insights on how to standardize data science planning across various projects and how to get a Data Scientists to think and work in an agile manner. We hear about ideal data team structures, how to approach hiring, and what skills to look for in new hires. The conversation also touches on what responsibility Data Leaders have within organizations, championing data-driven decisions and strategy, as well as the complexity Data Leaders face in highly regulated industries. When it comes to solving problems that provide value for the business, engagement and transparency are key aspects. Derek shares how to ensure that expectations are met through clear and frank conversations with executives that try to align expectations between management and Data Science teams.
Finally, you'll learn about validation frameworks, best practices for teams in less regulated industries, what trends to look out for in 2023 and how ChatGPT is changing how executives define their expectations from Data Science teams.
Links to mentioned in the show: The Checklist Manifesto by Atul Gawande Team of Teams by General Stanley McChrystal The Harvard Data Science Review Podcast
Relevant Links from DataCamp: Article: Storytelling for More Impactful Data Science Course: Data Communication Concepts Course: Data-Driven Decision-Making for Business
In this episode, Jason Foster talks to Ben Steele, Head of Data and Analytics at BMS Group, a fast-growing, global insurance and reinsurance broker. They discuss the importance of predicting value and the key factors organisations should focus on to become more agile, better equipped to respond to new challenges and opportunities, and ultimately deliver more value to their stakeholders.
Today I’m chatting with Dr. Sebastian Klapdor, Chief Data Officer for Vista. Sebastian has developed and grown a successful Data Product Management team at Vista, and it all began with selling his vision to the rest of the executive leadership. In this episode, Sebastian explains what that process was like and what he learned. Sebastian shares valuable insights on how he implemented a data product orientation at Vista, what makes a good data product manager, and why technology usage isn’t the only metric that matters when measuring success. He also shares what he would do differently if he had to do it all over again.
Highlights/ Skip to:
How Sebastian defines a data product (01:48) Brian asks Sebastian about the change management process in leadership when implementing a data product approach (07:40) The three dimensions that Sebastian and his team measure to determine adoption success (10:22) Sebastian shares the financial results of Vista adopting a data product approach (12:56) The size and scale of the data team at Vista, and how their different roles ensure success (14:30) Sebastian explains how Vista created and grew a team of 35 data product managers (16:47) The skills Sebastian feels data product managers need to be successful at Vista (22:02) Sebastian describes what he would do differently if he had to implement a data product approach at a company again (29:46)
Quotes from Today’s Episode “You need to establish a culture, and that’s often the hardest part that takes the longest - to treat data as an asset, and not to treat it as a byproduct, but to treat it as a product and treat it as a valuable thing.” – Sebastian Klapdor (07:56)
“One source of data product managers is taking data professionals. So, you take data engineers, data scientists, or former analysts, and develop them into the role by coaching them [through] the product management skills from the software industry.” – Sebastian Klapdor (17:39)
“We went out there and we were hiring people in the market who were experienced [Product Managers]. But we also see internal people, actually grooming and growing into all of these roles, both from these 80 folks who have been around before, but also from other areas of Vista.” – Sebastian Klapdor (20:28)
“[Being a good Product Manager] comes back to the good old classics of collaborating, of being empathetic to where other people are at, their priorities, and understanding where [our] priorities fit into their bigger piece, and jointly aligning on what is valuable for Vista.” – Sebastian Klapdor (22:27)
“I think there’s nothing more detrimental than saying, ‘Yeah, sure, we can deliver things, and with data, it can do everything.’ And then you disappoint people and you don’t stick to your promises. … If you don’t stick to your promise, it will hurt you.” – Sebastian Klapdor (23:04)
“You don’t do the typical waterfall approach of solving business problems with data. You don’t do the approach that a data scientist tries to get some data, builds a model, and hands it over to data engineer who should productionize that. And then the data engineer gets back and says certain features can’t be productionized because it’s very complex to get the data on a daily basis, or in real time. By doing [this work] in a data product team, you can work actually in Agile and you’re super fast building what we call a minimum lovable product.” – Sebastian Klapdor (26:15)
“That was the biggest learning … whom do we staff as data product managers? And what do we expect of a good data product manager? How does a career path look like? That took us a really long time to figure out.” – Sebastian Klapdor (30:18)
“We have a big, big, big commitment that we want to start stuffing UX designers onto our [data] product teams.” - Sebastian Klapdor (21:12)
Links Vista: https://vista.io LinkedIn: https://www.linkedin.com/in/sebastianklapdor/ Vista Blog: https://vista.io/blog

ADVANCES IN BUSINESS STATISTICS, METHODS AND DATA COLLECTION Advances in Business Statistics, Methods and Data Collection delivers insights into the latest state of play in producing establishment statistics, obtained from businesses, farms and institutions. Presenting materials and reflecting discussions from the 6 th International Conference on Establishment Statistics (ICES-VI), this edited volume provides a broad overview of methodology underlying current establishment statistics from every aspect of the production life cycle while spotlighting innovative and impactful advancements in the development, conduct, and evaluation of modern establishment statistics programs. Highlights include: Practical discussions on agile, timely, and accurate measurement of rapidly evolving economic phenomena such as globalization, new computer technologies, and the informal sector. Comprehensive explorations of administrative and new data sources and technologies, covering big (organic) data sources and methods for data integration, linking, machine learning and visualization. Detailed compilations of statistical programs’ responses to wide-ranging data collection and production challenges, among others caused by the Covid-19 pandemic. In-depth examinations of business survey questionnaire design, computerization, pretesting methods, experimentation, and paradata. Methodical presentations of conventional and emerging procedures in survey statistics techniques for establishment statistics, encompassing probability sampling designs and sample coordination, non-probability sampling, missing data treatments, small area estimation and Bayesian methods. Providing a broad overview of most up-to-date science, this book challenges the status quo and prepares researchers for current and future challenges in establishment statistics and methods. Perfect for survey researchers, government statisticians, National Bank employees, economists, and undergraduate and graduate students in survey research and economics, Advances in Business Statistics, Methods and Data Collection will also earn a place in the toolkit of researchers working –with data– in industries across a variety of fields.
On today’s episode, we’re talking to Dylan Barrell, Chief Technology Officer at Deque Systems, Inc, a web accessibility software and services company aimed at giving everyone, regardless of ability, equal access to information, services and applications on the web.
We talk about:
- Dylan’s background and what Deque does.
- The importance of accessibility in software.
- Dylan’s book, “Agile Accessibility Handbook,” and why he wrote it.
- Are there any particular tools to identify accessibility issues in software?
- Countries that are leading the way around SaaS accessibility.
- Advice for smaller, newer SaaS companies to prioritize accessibility.
- How tech trends like AI, the IoT and algorithms have impacted accessibility.
Dylan Barrell - https://www.linkedin.com/in/dylanbarrell/ Deque Systems - https://www.linkedin.com/company/deque-systems-inc/
This episode is brought to you by Qrvey
The tools you need to take action with your data, on a platform built for maximum scalability, security, and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com.
Qrvey, the modern no-code analytics solution for SaaS companies on AWS.
saas #analytics #AWS #BI
Summary Building data products is an undertaking that has historically required substantial investments of time and talent. With the rise in cloud platforms and self-serve data technologies the barrier of entry is dropping. Shane Gibson co-founded AgileData to make analytics accessible to companies of all sizes. In this episode he explains the design of the platform and how it builds on agile development principles to help you focus on delivering value.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Prefect is the modern Dataflow Automation platform for the modern data stack, empowering data practitioners to build, run and monitor robust pipelines at scale. Guided by the principle that the orchestrator shouldn’t get in your way, Prefect is the only tool of its kind to offer the flexibility to write code as workflows. Prefect specializes in glueing together the disparate pieces of a pipeline, and integrating with modern distributed compute libraries to bring power where you need it, when you need it. Trusted by thousands of organizations and supported by over 20,000 community members, Prefect powers over 100MM business critical tasks a month. For more information on Prefect, visit dataengineeringpodcast.com/prefect. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc., are already available as plug-and-play connectors with reliable, intuitive SaaS solutions. Hevo Data is a highly reliable and intuitive data pipeline platform used by data engineers from 40+ countries to set up and run low-latency ELT pipelines with zero maintenance. Boasting more than 150 out-of-the-box connectors that can be set up in minutes, Hevo also allows you to monitor and control your pipelines. You get: real-time data flow visibility, fail-safe mechanisms, and alerts if anything breaks; preload transformations and auto-schema mapping precisely control how data lands in your destination; models and workflows to transform data for analytics; and reverse-ETL capability to move the transformed data back to your business software to inspire timely action. All of this, plus its transparent pricing and 24*7 live support, makes it consistently voted by users as the Leader in the Data Pipeline category on review platforms like G2. Go to dataengineeringpodcast.com/hevodata and sign up for a free 14-day trial that also comes with 24×7 support. Your host is Tobias Macey and today I’m interviewing Shane Gibson about AgileData
Summary Agile methodologies have been adopted by a majority of teams for building software applications. Applying those same practices to data can prove challenging due to the number of systems that need to be included to implement a complete feature. In this episode Shane Gibson shares practical advice and insights from his years of experience as a consultant and engineer working in data about how to adopt agile principles in your data work so that you can move faster and provide more value to the business, while building systems that are maintainable and adaptable.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Prefect is the modern Dataflow Automation platform for the modern data stack, empowering data practitioners to build, run and monitor robust pipelines at scale. Guided by the principle that the orchestrator shouldn’t get in your way, Prefect is the only tool of its kind to offer the flexibility to write code as workflows. Prefect specializes in glueing together the disparate pieces of a pipeline, and integrating with modern distributed compute libraries to bring power where you need it, when you need it. Trusted by thousands of organizations and supported by over 20,000 community members, Prefect powers over 100MM business critical tasks a month. For more information on Prefect, visit dataengineeringpodcast.com/prefect. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc., are already available as plug-and-play connectors with reliable, intuitive SaaS solutions. Hevo Data is a highly reliable and intuitive data pipeline platform used by data engineers from 40+ countries to set up and run low-latency ELT pipelines with zero maintenance. Boasting more than 150 out-of-the-box connectors that can be set up in minutes, Hevo also allows you to monitor and control your pipelines. You get: real-time data flow visibility, fail-safe mechanisms, and alerts if anything breaks; preload transformations and auto-schema mapping precisely control how data lands in your destination; models and workflows to transform data for analytics; and reverse-ETL capability to move the transformed data back to your business software to inspire timely action. All of this, plus its transparent pricing and 24*7 live support, makes it consistently voted by users as the Leader in the Data Pipeline category on review platforms like G2. Go to dataengineeringpodcast.com/hevodata and sign up for a free 14-day trial that also comes with 24×7 support. Your host is Tobias Macey and today I’m interviewing Shane Gibson about how to bring Agile practices to your data management workflows
Interview
Introduction How did you get involved in the area of data management? Can you describe what AgileData is and the story behind it? What are the main industries and/or use cases that you are focused on supporting? The data ecosystem has been trying on different paradigms from software development for some time now (e.g. DataOps, version control, etc.). What are the aspects of Agile that do and don’t map well to data engineering/analysis? One of the perennial challenges of data analysis is how to approach data modeling. How do you balance the need to provide value with the long-term impacts of incomplete or underinformed modeling decisions made in haste at the beginning of a project?
How do you design in affordances for refactoring of the data models without breaking downstream assets?
Another aspect of implementing data products/platforms is how to manage permissions and governance. What are the incremental ways that those principles can be incorporated early and evolved along with the overall analytical products? What are some of the organizational design strategies that you find most helpful when establishing or training a team who is working on data products? In order to have a useful target to work toward it’s necessary to understand what the data consumers are hoping to achieve. What are some of the challenges of doing requirements gathering for data products? (e.g. not knowing what information is available, consumers not understanding what’s hard vs. easy, etc.)
How do you work with the "customers" to help them understand what a reasonable scope is and translate that to the actual project stages for the engineers?
What are some of the perennial questions or points of confusion that you have had to address with your clients on how to design and implement analytical assets? What are the most interesting, innovative, or unexpected ways that you have seen agile principles used for data? What are the most interesting, unexpected, or challenging lessons that you have learned while working on AgileData? When is agile the wrong choice for a data project? What do you have planned for the future of AgileData?
Contact Info
LinkedIn @shagility on Twitter
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don’t forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you’ve learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
AgileData OptimalBI How To Make Toast Data Mesh Information Product Canvas DataKitchen
Podcast Episode
Great Expectations
Podcast Episode
Soda Data
Podcast Episode
Google DataStore Unfix.work Activity Schema
Podcast Episode
Data Vault
Podcast Episode
Star Schema Lean Methodology Scrum Kanban
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Atlan: 
Have you ever woken up to a crisis because a number on a dashboard is broken and no one knows why? Or sent out frustrating slack messages trying to find the right data set? Or tried to understand what a column name means?
Our friends at Atlan started out as a data team themselves and faced all this collaboration chaos themselves, and started building Atlan as an internal tool for themselves. Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. By acting as a virtual hub for data assets ranging from tables and dashboards to SQL snippets & code, Atlan enables teams to create a single source of truth for all their data assets, and collaborate across the modern data stack through deep integrations with tools like Snowflake, Slack, Looker and more.
Go to dataengineeringpodcast.com/atlan and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription.Prefect: 
Prefect is the modern Dataflow Automation platform for the modern data stack, empowering data practitioners to build, run and monitor robust pipelines at scale. Guided by the principle that the orchestrator shouldn’t get in your way, Prefect is the only tool of its kind to offer the flexibility to write code as workflows. Prefect specializes in glueing together the disparate pieces of a pipeline, and integrating with modern distributed compute libraries to bring power where you need it, when you need it. Trusted by thousands of organizations and supported by over 20,000 community members, Prefect powers over 100MM business critical tasks a month. For more information on Prefect, visit…

Does digital transformation ever stop? The answer is a resounding “no" and this book guides you in developing an SAP enterprise architecture that prepares you for constant technology changes. The book introduces enterprise architecture, the role it plays in executing successful business strategy, and its application in SAP. A detailed step-by-step guide teaches you how to utilize SAP Enterprise Architecture Designer to model the four key areas: business, data, landscape, and requirements. Executives will gain insight into the considerations that will aid them in building their digital transformation road map while remaining agile to adapt to unforeseen circumstances. and adapting to the new normal. SAP partners and consultants will find their place in SAP’s future. By the end of this book, you will learn what SAP enterprise architecture is and how to develop it along with its best practices. You Will Understand Thefundamentals of enterprise architecture SAP enterprise architecture How SAP Enterprise Architecture Designer helps your enterprise Business, information, and infrastructure architecture Enterprise architecture best practices How enterprise architecture can prepare your business for the future Who This Book Is For Executives who currently run SAP implementations or are considering SAP implementations, SAP partners and consultants along with aspiring SAP consultants, and technology enthusiasts interested in understanding and articulating IT and business alignment through enterprise architecture
In this episode, we’re talking to Kaj van de Loo, Chief Technology Officer at UserTesting. We talk about the company’s history and the problems it solves, the way Agile development methodologies have evolved, the different types of Agile development, and the differences between B2B and B2C software. Kaj talks about some of the best ways for companies to understand users and how to analyze data like web traffic, the growing importance of personalization in user experience, the best time to add product management to a team, and more. Finally, we talk about the ideal ratio of QAs to developers and whether being a CTO makes someone a better CEO.
This episode is brought to you by Qrvey The tools you need to take action with your data, on a platform built for maximum scalability, security, and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com. Qrvey, the modern no-code analytics solution for SaaS companies on AWS.

Cybersecurity is the most important arm of defense against cyberattacks. With the recent increase in cyberattacks, corporations must focus on how they are combating these new high-tech threats. When establishing best practices, a corporation must focus on employees' access to specific workspaces and information. IBM Z® focuses on allowing high processing virtual environments while maintaining a high level of security in each workspace. Organizations not only need to adjust their approach to security, but also their approach to IT environments. To meet new customer needs and expectations, organizations must take a more agile approach to their business. IBM® Z allows companies to work with hybrid and multi-cloud environments that allows more ease of use for the user and efficiency overall. Working with IBM Z, organizations can also work with many databases that are included in IBM Cloud Pak® for Data. IBM Cloud Pak for Data allows organizations to make more informed decisions with improved data usage. Along with the improved data usage, organizations can see the effects from working in a Red Hat OpenShift environment. Red Hat OpenShift is compatible across many hardware services and allows the user to run applications in the most efficient manner. The purpose of this IBM Redbooks® publication is to: Introduce IBM Z and LinuxONE platforms and how they work with the Red Hat OpenShift environment and IBMCloud Pak for Data Provide examples and the uses of IBM Z with Cloud Paks for Data that show data gravity, consistent development experience, and consolidation and business resiliency The target audience for this book is IBM Z Technical Specialists, IT Architects, and System Administrators.
Summary Data mesh is a frequent topic of conversation in the data community, with many debates about how and when to employ this architectural pattern. The team at AgileLab have first-hand experience helping large enterprise organizations evaluate and implement their own data mesh strategies. In this episode Paolo Platter shares the lessons they have learned in that process, the Data Mesh Boost platform that they have built to reduce some of the boilerplate required to make it successful, and some of the considerations to make when deciding if a data mesh is the right choice for you.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Prefect is the modern Dataflow Automation platform for the modern data stack, empowering data practitioners to build, run and monitor robust pipelines at scale. Guided by the principle that the orchestrator shouldn’t get in your way, Prefect is the only tool of its kind to offer the flexibility to write code as workflows. Prefect specializes in glueing together the disparate pieces of a pipeline, and integrating with modern distributed compute libraries to bring power where you need it, when you need it. Trusted by thousands of organizations and supported by over 20,000 community members, Prefect powers over 100MM business critical tasks a month. For more information on Prefect, visit dataengineeringpodcast.com/prefect. The only thing worse than having bad data is not knowing that you have it. With Bigeye’s data observability platform, if there is an issue with your data or data pipelines you’ll know right away and can get it fixed before the business is impacted. Bigeye let’s data teams measure, improve, and communicate the quality of your data to company stakeholders. With complete API access, a user-friendly interface, and automated yet flexible alerting, you’ve got everything you need to establish and maintain trust in your data. Go to dataengineeringpodcast.com/bigeye today to sign up and start trusting your analyses. Your host is Tobias Macey and today I’m interviewing Paolo Platter about Agile Lab’s lessons learned through helping large enterprises establish their own data mesh
Interview
Introduction How did you get involved in the area of data management? Can you share your experiences working with data mesh implementations? What were the stated goals of project engagements that led to data mesh implementations? What are some examples of projects where you explored data mesh as an option and decided that it was a poor fit? What are some of the technical and process investments that are necessary to support a mesh str

With businesses competing to deliver value while growing rapidly and adapting to changing markets, it is more important than ever for data teams to support faster and reliable insights. We need to fail fast, learn, adapt, release and repeat. For us, Trusted and unified data infrastructure with standardized practices is at the crux of it all
In this talk: we'll go over Atlassian's data engineering team organization, infrastructure and development practices
- Team organization and roles
- Overview of our data engineering technical stack
- Code repositories and CICD setup
- Testing framework
- Development walkthrough
- Production data quality & integrity
- Alerting & Monitoring
- Tracking operational metrics (SLI/SLO, Cost)
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
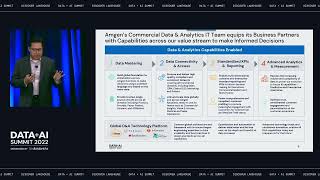
Serving patients in over 100 countries, Amgen is a leading global biotech company focused on developing therapies that have the power to save lives. Delivering on this mission requires our commercial teams to regularly meet with healthcare providers to discuss new treatments that can help patients in need. With the onset of the pandemic, where face-to-face interactions with doctors and other Healthcare Providers (HCPs) were severely impacted, Amgen had to rethink these interactions. With that in mind, the Amgen Commercial Data and Analytics team leveraged a modern data and AI architecture built on the Databricks Lakehouse to help accelerate its digital and data insights capabilities. This foundation enabled Amgen’s teams to develop a comprehensive, customer-centric view to support flexible go-to-market models and provide personalized experiences to our customers. In this presentation, we will share our recent journey of how we took an agile approach to bringing together over 2.2 petabytes of internally generated and externally sourced vendor data , and onboard into our AWS Cloud and Databricks environments to enable a standardized, scalable and robust capabilities to meet the business requirements in our fast-changing life sciences environment. We will share use cases of how we harmonized and managed our diverse sets of data to deliver efficiency, simplification, and performance outcomes for the business. We will cover the following aspects of our journey along with best practices we learned over time: • Our architecture to support Amgen’s Commercial Data & Analytics constant processing around the globe • Engineering best practices for building large scale Data Lakes and Analytics platforms such as Team organization, Data Ingestion and Data Quality Frameworks, DevOps Toolkit and Maturity Frameworks, and more • Databricks capabilities adopted such as Delta Lake, Workspace policies, SQL workspace endpoints, and MLflow for model registry and deployment. Also, various tools were built for Databricks workspace administration • Databricks capabilities being explored for future, such as Multi-task Orchestration, Container-based Apache Spark Processing, Feature Store, Repos for Git integration, etc. • The types of commercial analytics use cases we are building on the Databricks Lakehouse platform Attendees building global and Enterprise scale data engineering solutions to meet diverse sets of business requirements will benefit from learning about our journey. Technologists will learn how we addressed specific Business problems via reusable capabilities built to maximize value.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/