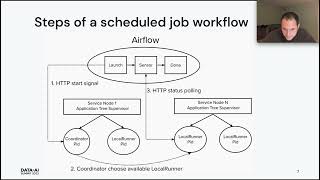
Explore the latest advancements in AWS Analytics designed to transform your data processing landscape. This session unveils powerful new capabilities across key services, including Amazon EMR for scalable big data processing, AWS Glue for seamless data integration, Amazon Athena for optimized querying, and Amazon Managed Workflows for Apache Airflow (MWAA) for workflow orchestration. Discover how these innovations can supercharge performance, optimize costs, and streamline your data ecosystem. Whether you're looking to enhance scalability, improve data integration, accelerate queries, or refine workflow management, join us to gain actionable insights that will position your organization at the forefront of data processing innovation.
Learn more: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.