Data Dynamics: Navigating the Role of Data Product Managers The Data Product Management In Action podcast, brought to you by Soda and executive producer Scott Hirleman, is a platform for data product management practitioners to share insights and experiences. In Episode 22 of Data Product Management in Action, we welcome back our host Michael Toland as he chats with guest Chandan Gadodia. Listen along as they explore the vital role of data product managers. Discover the distinctions between data, IT, and functional product managers and their contributions to product success. Learn more about key focus areas like data pipelines, quality, and standards, as well as the role of AI in enhancing data quality. Join us for an enlightening discussion on the evolving landscape of data management! About our host Michael Toland: Toland is a Product Management Coach and Consultant with Pathfinder Product, aTest Double Operation. He has worked in product officially since 2016, where he worked at Verizon on large scale system modernizations and migration initiatives for reference data and decision platforms. Outside of his professional career, Michael serves as the Treasurer for the New Leaders Council, mentors fellows with Venture for America, sings in the Columbus Symphony, writes satire posts for his blog Dignified Productor Test Double, depending on the topic, and is excited to be chatting with folks on Data Product Management. Connect with Michael on LinkedIn. About our guest Chadan Gadodia: With over a decade serving in data and analytics, Chandan Gadodia, a seasoned Data Product Manager, has held several roles within the industry. From managing internal data assets to overseeing global data products, Chandan's passion for learning from diverse perspectives, connecting with global colleagues, and contributing to growth for himself and his organization has been constant. He is a big advocate for data literacy and strongly believes in data driven business outcomes. Connect with Chadan on LinkedIn. All views and opinions expressed are those of the individuals and do not necessarily reflect their employers or anyone else. Join the conversation on LinkedIn. Apply to be a guest or nominate someone that you know. Do you love what you're listening to? Please rate and review the podcast, and share it with fellow practitioners you know. Your support helps us reach more listeners and continue providing valuable insights!
 talk-data.com
talk-data.com
Topic
Data Management
1097
tagged
Activity Trend
Top Events
Summary The challenges of integrating all of the tools in the modern data stack has led to a new generation of tools that focus on a fully integrated workflow. At the same time, there have been many approaches to how much of the workflow is driven by code vs. not. Burak Karakan is of the opinion that a fully integrated workflow that is driven entirely by code offers a beneficial and productive means of generating useful analytical outcomes. In this episode he shares how Bruin builds on those opinions and how you can use it to build your own analytics without having to cobble together a suite of tools with conflicting abstractions.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Burak Karakan about the benefits of building code-only data systemsInterview IntroductionHow did you get involved in the area of data management?Can you describe what Bruin is and the story behind it?Who is your target audience?There are numerous tools that address the ETL workflow for analytical data. What are the pain points that you are focused on for your target users?How does a code-only approach to data pipelines help in addressing the pain points of analytical workflows?How might it act as a limiting factor for organizational involvement?Can you describe how Bruin is designed?How have the design and scope of Bruin evolved since you first started working on it?You call out the ability to mix SQL and Python for transformation pipelines. What are the components that allow for that functionality?What are some of the ways that the combination of Python and SQL improves ergonomics of transformation workflows?What are the key features of Bruin that help to streamline the efforts of organizations building analytical systems?Can you describe the workflow of someone going from source data to warehouse and dashboard using Bruin and Ingestr?What are the opportunities for contributions to Bruin and Ingestr to expand their capabilities?What are the most interesting, innovative, or unexpected ways that you have seen Bruin and Ingestr used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on Bruin?When is Bruin the wrong choice?What do you have planned for the future of Bruin?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links BruinFivetranStitchIngestrBruin CLIMeltanoSQLGlotdbtSQLMeshPodcast EpisodeSDFPodcast EpisodeAirflowDagsterSnowparkAtlanEvidenceThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
We’re improving DataFramed, and we need your help! We want to hear what you have to say about the show, and how we can make it more enjoyable for you—find out more here. Understanding where the data you use comes from, how to use it responsibly, and how to maximize its value has become essential. But as data sources multiply, so do the complexities around data privacy, customization, and ownership. How can companies capture and leverage the right data to create meaningful customer experiences while respecting privacy? And as data drives more personalized interactions, what steps can businesses take to protect sensitive information and navigate the increasingly complex regulatory picture? Jonathan Bloch is CEO at Exchange Data International (EDI) and a seasoned businessman with 40 years experience in information provision. He started work in the newsletter industry and ran the US subsidiary of a UK public company before joining its main board as head of its publishing division. He has been a director and/or chair of several companies and is currently a non executive director of an FCA registered investment bank. In 1994 he founded Exchange Data International (EDI) a London based financial data provider. EDI now has over 450 clients across three continents and is based in the UK, USA, India and Morocco employing 500 people. Scott Voigt is CEO and co-founder at Fullstory. Scott has enjoyed helping early-stage software businesses grow since the mid 90s, when he helped launch and take public nFront—one of the world's first Internet banking service providers. Prior to co-founding Fullstory, Voigt led marketing at Silverpop before the company was acquired by IBM. Previously, he worked at Noro-Moseley Partners, the Southeast's largest Venture firm, and also served as COO at Innuvo, which was acquired by Google. Scott teamed up with two former Innuvo colleagues, and the group developed the earliest iterations of Fullstory to understand how an existing product was performing. It was quickly apparent that this new platform provided the greatest value—and the rest is history. In the episode, Richie, Jonathan and Scott explore first-party vs third-party data, protecting corporate data, behavioral data, personalization, data sourcing strategies, platforms for storage and sourcing, data privacy, synthetic data, regulations and compliance, the future of data collection and storage, and much more. Links Mentioned in the Show: FullstoryExchange Data InternationalConnect with Jonathan and ScottCourse: Understanding GDPRRelated Episode: How Data and AI are Changing Data Management with Jamie Lerner, CEO, President, and Chairman at QuantumSign up to RADAR: Forward Edition New to DataCamp? Learn on the go using the DataCamp mobile...
Summary In this episode of the Data Engineering Podcast, the creators of Feldera talk about their incremental compute engine designed for continuous computation of data, machine learning, and AI workloads. The discussion covers the concept of incremental computation, the origins of Feldera, and its unique ability to handle both streaming and batch data seamlessly. The guests explore Feldera's architecture, applications in real-time machine learning and AI, and challenges in educating users about incremental computation. They also discuss the balance between open-source and enterprise offerings, and the broader implications of incremental computation for the future of data management, predicting a shift towards unified systems that handle both batch and streaming data efficiently.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!As a listener of the Data Engineering Podcast you clearly care about data and how it affects your organization and the world. For even more perspective on the ways that data impacts everything around us you should listen to Data Citizens® Dialogues, the forward-thinking podcast from the folks at Collibra. You'll get further insights from industry leaders, innovators, and executives in the world's largest companies on the topics that are top of mind for everyone. They address questions around AI governance, data sharing, and working at global scale. In particular I appreciate the ability to hear about the challenges that enterprise scale businesses are tackling in this fast-moving field. While data is shaping our world, Data Citizens Dialogues is shaping the conversation. Subscribe to Data Citizens Dialogues on Apple, Spotify, Youtube, or wherever you get your podcasts.Your host is Tobias Macey and today I'm interviewing Leonid Ryzhyk, Lalith Suresh, and Mihai Budiu about Feldera, an incremental compute engine for continous computation of data, ML, and AI workloadsInterview IntroductionCan you describe what Feldera is and the story behind it?DBSP (the theory behind Feldera) has won multiple awards from the database research community. Can you explain what it is and how it solves the incremental computation problem?Depending on which angle you look at it, Feldera has attributes of data warehouses, federated query engines, and stream processors. What are the unique use cases that Feldera is designed to address?In what situations would you replace another technology with Feldera?When is it an additive technology?Can you describe the architecture of Feldera?How have the design and scope evolved since you first started working on it?What are the state storage interfaces available in Feldera?What are the opportunities for integrating with or building on top of open table formats like Iceberg, Lance, Hudi, etc.?Can you describe a typical workflow for an engineer building with Feldera?You advertise Feldera's utility in ML and AI use cases in addition to data management. What are the features that make it conducive to those applications?What is your philosophy toward the community growth and engagement with the open source aspects of Feldera and how you're balancing that with sustainability of the project and business?What are the most interesting, innovative, or unexpected ways that you have seen Feldera used?What are the most interesting, unexpected, or challenging lessons that
In this special Halloween episode, Jason Foster talks to James Lupton, CTO at Cynozure, and Keith Goldthorpe, Director of Solution Architecture at Cynozure. Reflecting on their conversation from last year, the group revisit some of their predictions and discuss the most significant developments in the realms of data and AI. They also engage in a game of 'AI Spell or Human Skill,' where they debate whether humans or AI tools would outperform one another in a series of spellbinding scenarios. ***** Cynozure is a leading data, analytics and AI company that helps organisations to reach their data potential. It works with clients on data and AI strategy, data management, data architecture and engineering, analytics and AI, data culture and literacy, and data leadership. The company was named one of The Sunday Times' fastest-growing private companies in both 2022 and 2023, and recognised as The Best Place to Work in Data by DataIQ in 2023 and 2024.

Microsoft Power Apps Cookbook is a comprehensive guide to harnessing the full potential of Microsoft Power Apps, a powerful low-code platform for building business applications. Packed with practical recipes, this book details how to develop scalable, efficient apps, automate workflows with RPA, and utilize new capabilities like AI-powered Microsoft Copilot and the Power Apps Component Framework. What this Book will help me do Create and deploy scalable canvas and model-driven apps using Microsoft Power Apps. Utilize AI-powered features like Copilot to speed up app creation and development. Implement robust data management strategies with Microsoft Dataverse. Extend app functionalities using the Power Apps Component Framework for custom components. Design and build secure external-facing websites with Microsoft Power Pages. Author(s) Eickhel Mendoza is an experienced Microsoft Power Platform developer and educator who has helped numerous organizations enhance their capabilities through low-code app development. Authoring from extensive hands-on experience, their teaching style bridges technical theory and practical application. Eickhel is passionate about empowering users to achieve more with modern app development tools. Who is it for? This book is ideal for information workers and developers looking to streamline their application development processes with Microsoft's low-code solutions. It is particularly targeted toward users with a foundational understanding of the Power Platform looking to deepen their knowledge. Readers will benefit most if they are eager to learn how to create innovative solutions efficiently. Traditional developers aiming to explore a new paradigm of rapid application development will also find it highly beneficial.
Summary Gleb Mezhanskiy, CEO and co-founder of DataFold, joins Tobias Macey to discuss the challenges and innovations in data migrations. Gleb shares his experiences building and scaling data platforms at companies like Autodesk and Lyft, and how these experiences inspired the creation of DataFold to address data quality issues across teams. He outlines the complexities of data migrations, including common pitfalls such as technical debt and the importance of achieving parity between old and new systems. Gleb also discusses DataFold's innovative use of AI and large language models (LLMs) to automate translation and reconciliation processes in data migrations, reducing time and effort required for migrations. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm welcoming back Gleb Mezhanskiy to talk about Datafold's experience bringing AI to bear on the problem of migrating your data stackInterview IntroductionHow did you get involved in the area of data management?Can you describe what the Data Migration Agent is and the story behind it?What is the core problem that you are targeting with the agent?What are the biggest time sinks in the process of database and tooling migration that teams run into?Can you describe the architecture of your agent?What was your selection and evaluation process for the LLM that you are using?What were some of the main unknowns that you had to discover going into the project?What are some of the evolutions in the ecosystem that occurred either during the development process or since your initial launch that have caused you to second-guess elements of the design?In terms of SQL translation there are libraries such as SQLGlot and the work being done with SDF that aim to address that through AST parsing and subsequent dialect generation. What are the ways that approach is insufficient in the context of a platform migration?How does the approach you are taking with the combination of data-diffing and automated translation help build confidence in the migration target?What are the most interesting, innovative, or unexpected ways that you have seen the Data Migration Agent used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on building an AI powered migration assistant?When is the data migration agent the wrong choice?What do you have planned for the future of applications of AI at Datafold?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links DatafoldDatafold Migration AgentDatafold data-diffDatafold Reconciliation Podcast EpisodeSQLGlotLark parserClaude 3.5 SonnetLookerPodcast EpisodeThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
The Data Product Management In Action podcast, brought to you by Soda and executive producer Scott Hirleman, is a platform for data product management practitioners to share insights and experiences. In Episode 21 of Data Product Management in Action, Frannie Helforoush interviews Lucca Kazan, a senior AI product manager about Navigating AI in Data Product Management. Luca shares insights from his work on innovative data products. He shares insights about search and personalization engines, facial recognition systems, and anti-fraud solutions. He’ll explore the relationship between AI and data product management and challenges in the discovery phase and the importance of stakeholder management. Tune in to discover how understanding AI technology can enhance user-focused product development! About our host Frannie Helforoush: Frannie's journey began as a software engineer and evolved into a strategic product manager. Now, as a data product manager, she leverages her expertise in both fields to create impactful solutions. Frannie thrives on making data accessible and actionable, driving product innovation, and ensuring product thinking is integral to data management. Connect with Frannie on LinkedIn. About our guest Lucca Kazan: Seasoned Artificial Intelligence Product Manager, with over 9 years of experience in product strategy and 5 years in AI development. By leveraging AI aligned with business goals Lucca has been able to increase EBITDA by 7 digits (USD/ year) for the biggest food delivery app in Latin America, reduce user drop-off by 83% for the biggest facial recognition company in Brazil and reduced frau by 87% (8 digits in monthly savings) for the biggest food delivery app in Brazil! Connect with Lucca on LinkedIn. All views and opinions expressed are those of the individuals and do not necessarily reflect their employers or anyone else. Join the conversation on LinkedIn. Apply to be a guest or nominate someone that you know. Do you love what you're listening to? Please rate and review the podcast, and share it with fellow practitioners you know. Your support helps us reach more listeners and continue providing valuable insights!
Summary The rapid growth of generative AI applications has prompted a surge of investment in vector databases. While there are numerous engines available now, Lance is designed to integrate with data lake and lakehouse architectures. In this episode Weston Pace explains the inner workings of the Lance format for table definitions and file storage, and the optimizations that they have made to allow for fast random access and efficient schema evolution. In addition to integrating well with data lakes, Lance is also a first-class participant in the Arrow ecosystem, making it easy to use with your existing ML and AI toolchains. This is a fascinating conversation about a technology that is focused on expanding the range of options for working with vector data. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Weston Pace about the Lance file and table format for column-oriented vector storageInterview IntroductionHow did you get involved in the area of data management?Can you describe what Lance is and the story behind it?What are the core problems that Lance is designed to solve?What is explicitly out of scope?The README mentions that it is straightforward to convert to Lance from Parquet. What is the motivation for this compatibility/conversion support?What formats does Lance replace or obviate?In terms of data modeling Lance obviously adds a vector type, what are the features and constraints that engineers should be aware of when modeling their embeddings or arbitrary vectors?Are there any practical or hard limitations on vector dimensionality?When generating Lance files/datasets, what are some considerations to be aware of for balancing file/chunk sizes for I/O efficiency and random access in cloud storage?I noticed that the file specification has space for feature flags. How has that aided in enabling experimentation in new capabilities and optimizations?What are some of the engineering and design decisions that were most challenging and/or had the biggest impact on the performance and utility of Lance?The most obvious interface for reading and writing Lance files is through LanceDB. Can you describe the use cases that it focuses on and its notable features?What are the other main integrations for Lance?What are the opportunities or roadblocks in adding support for Lance and vector storage/indexes in e.g. Iceberg or Delta to enable its use in data lake environments?What are the most interesting, innovative, or unexpected ways that you have seen Lance used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on the Lance format?When is Lance the wrong choice?What do you have planned for the future of Lance?Contact Info LinkedInGitHubParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links Lance FormatLanceDBSubstraitPyArrowFAISSPineconePodcast EpisodeParquetIcebergPodcast EpisodeDelta LakePodcast EpisodePyLanceHilbert CurvesSIFT VectorsS3 ExpressWekaDataFusionRay DataTorch Data LoaderHNSW == Hierarchical Navigable Small Worlds vector indexIVFPQ vector indexGeoJSONPolarsThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
In this episode, host Jason Foster sits down with Cassandra Vukorep, Chief Data Officer at Lloyds of London. The discussion delves into the critical role of data literacy and how fostering a culture of data engagement can benefit a diverse range of organisations across various industries. They also explore Cassandra's current role at Lloyds and the exciting data opportunities that can be applied to the insurance industry. ***** Cynozure is a leading data, analytics and AI company that helps organisations to reach their data potential. It works with clients on data and AI strategy, data management, data architecture and engineering, analytics and AI, data culture and literacy, and data leadership. The company was named one of The Sunday Times' fastest-growing private companies in both 2022 and 2023, and recognised as The Best Place to Work in Data by DataIQ in 2023 and 2024.
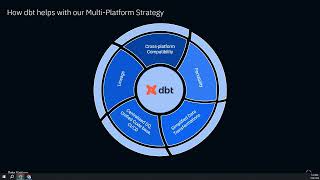
In the rapidly evolving landscape of data management, a multi-data platform strategy is essential for organizations seeking to harness the full potential of their diverse data sources. Learn how Fox uses dbt Cloud as a pivotal technology in orchestrating this strategy, enabling seamless integration, transformation, and analysis across multiple data platforms.
Speaker: Ramesh Madepalli Sr. Director, Architecture and Strategy Fox Corporation
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
Summary In this episode of the Data Engineering Podcast, Adrian Broderieux and Marcin Rudolph, co-founders of DLT Hub, delve into the principles guiding DLT's development, emphasizing its role as a library rather than a platform, and its integration with lakehouse architectures and AI application frameworks. The episode explores the impact of the Python ecosystem's growth on DLT, highlighting integrations with high-performance libraries and the benefits of Arrow and DuckDB. The episode concludes with a discussion on the future of DLT, including plans for a portable data lake and the importance of interoperability in data management tools. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Adrian Brudaru and Marcin Rudolf, cofounders at dltHub, about the growth of dlt and the numerous ways that you can use it to address the complexities of data integrationInterview IntroductionHow did you get involved in the area of data management?Can you describe what dlt is and how it has evolved since we last spoke (September 2023)?What are the core principles that guide your work on dlt and dlthub?You have taken a very opinionated stance against managed extract/load services. What are the shortcomings of those platforms, and when would you argue in their favor?The landscape of data movement has undergone some interesting changes over the past year. Most notably, the growth of PyAirbyte and the rapid shifts around the needs of generative AI stacks (vector stores, unstructured data processing, etc.). How has that informed your product development and positioning?The Python ecosystem, and in particular data-oriented Python, has also undergone substantial evolution. What are the developments in the libraries and frameworks that you have been able to benefit from?What are some of the notable investments that you have made in the developer experience for building dlt pipelines?How have the interfaces for source/destination development improved?You recently published a post about the idea of a portable data lake. What are the missing pieces that would make that possible, and what are the developments/technologies that put that idea within reach?What is your strategy for building a sustainable product on top of dlt?How does that strategy help to form a "virtuous cycle" of improving the open source foundation?What are the most interesting, innovative, or unexpected ways that you have seen dlt used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on dlt?When is dlt the wrong choice?What do you have planned for the future of dlt/dlthub?Contact Info AdrianLinkedInMarcinLinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links dltPodcast EpisodePyArrowPolarsIbisDuckDBPodcast Episodedlt Data ContractsRAG == Retrieval Augmented GenerationAI Engineering Podcast EpisodePyAirbyteOpenAI o1 ModelLanceDBQDrant EmbeddedAirflowGitHub ActionsArrow DataFusionApache ArrowPyIcebergDelta-RSSCD2 == Slowly Changing DimensionsSQLAlchemySQLGlotFSSpecPydanticSpacyEntity RecognitionParquet File FormatPython DecoratorREST API ToolkitOpenAPI Connector GeneratorConnectorXPython no-GILDelta LakePodcast EpisodeSQLMeshPodcast EpisodeHamiltonTabularPostHogPodcast.init EpisodeAsyncIOCursor.AIData MeshPodcast EpisodeFastAPILangChainGraphRAGAI Engineering Podcast EpisodeProperty GraphPython uvThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA

Computational Intelligence in Sustainable Computing and Optimization: Trends and Applications focuses on developing and evolving advanced computational intelligence algorithms for the analysis of data involved in applications, such as agriculture, biomedical systems, bioinformatics, business intelligence, economics, disaster management, e-learning, education management, financial management, and environmental policies. The book presents research in sustainable computing and optimization, combining methods from engineering, mathematics, artificial intelligence, and computer science to optimize environmental resources Computational intelligence in the field of sustainable computing combines computer science and engineering in applications ranging from Internet of Things (IoT), information security systems, smart storage, cloud computing, intelligent transport management, cognitive and bio-inspired computing, and management science. In addition, data intelligence techniques play a critical role in sustainable computing. Recent advances in data management, data modeling, data analysis, and artificial intelligence are finding applications in energy networks and thus making our environment more sustainable. Presents computational, intelligence–based data analysis for sustainable computing applications such as pattern recognition, biomedical imaging, sustainable cities, sustainable transport, sustainable agriculture, and sustainable financial management Develops research in sustainable computing and optimization, combining methods from engineering, mathematics, and computer science to optimize environmental resources Includes three foundational chapters dedicated to providing an overview of computational intelligence and optimization techniques and their applications for sustainable computing
AI is becoming a key tool in industries far beyond just tech. From automating tasks in the movie industry to revolutionizing drug development in life sciences, AI is transforming how we work. But with this growth comes important questions: How is AI really impacting jobs? Are we just increasing efficiency, or are we replacing human roles? And how can companies effectively store and leverage the vast amounts of data being generated every day to gain a competitive advantage? Jamie Lerner is the President and CEO of Quantum, a company specializing in data storage, management, and protection. Since taking the helm in 2018, Lerner has steered Quantum towards innovative solutions for video and unstructured data. His leadership has been marked by strategic acquisitions and product launches that have significantly enhanced the company's market position. Before joining Quantum, Jamie worked at Cisco, Seagate, CITTIO, XUMA, and Platinum Technology. At Quantum, Lerner has been instrumental in shifting the company's focus towards data storage, management, and protection for video and unstructured data, driving innovation and strategic acquisitions to enhance its market position. In the episode, Richie and jamie explore AI in subtitling, translation, and the movie industry at large, AI in sports, AI in business and scientific research, AI ethics, infrastructure and data management, video and image data in business, challenges of working with AI in video, excitement vs fear in AI and much more. Links Mentioned in the Show: QuantumConnect with JamieCareer Track: Data Engineer in PythonRelated Episode: Seeing the Data Layer Through Spatial Computing with Cathy Hackl and Irena CroninRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
Summary In this episode of the Data Engineering Podcast Lukas Schulte, co-founder and CEO of SDF, explores the development and capabilities of this fast and expressive SQL transformation tool. From its origins as a solution for addressing data privacy, governance, and quality concerns in modern data management, to its unique features like static analysis and type correctness, Lucas dives into what sets SDF apart from other tools like DBT and SQL Mesh. Tune in for insights on building a business around a developer tool, the importance of community and user experience in the data engineering ecosystem, and plans for future development, including supporting Python models and enhancing execution capabilities. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Lukas Schulte about SDF, a fast and expressive SQL transformation tool that understands your schemaInterview IntroductionHow did you get involved in the area of data management?Can you describe what SDF is and the story behind it?What's the story behind the name?What problem are you solving with SDF?dbt has been the dominant player for SQL-based transformations for several years, with other notable competition in the form of SQLMesh. Can you give an overview of the venn diagram for features and functionality across SDF, dbt and SQLMesh?Can you describe the design and implementation of SDF?How have the scope and goals of the project changed since you first started working on it?What does the development experience look like for a team working with SDF?How does that differ between the open and paid versions of the product?What are the features and functionality that SDF offers to address intra- and inter-team collaboration?One of the challenges for any second-mover technology with an established competitor is the adoption/migration path for teams who have already invested in the incumbent (dbt in this case). How are you addressing that barrier for SDF?Beyond the core migration path of the direct functionality of the incumbent product is the amount of tooling and communal knowledge that grows up around that product. How are you thinking about that aspect of the current landscape?What is your governing principle for what capabilities are in the open core and which go in the paid product?What are the most interesting, innovative, or unexpected ways that you have seen SDF used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on SDF?When is SDF the wrong choice?What do you have planned for the future of SDF?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links SDFSemantic Data Warehouseasdf-vmdbtSoftware Linting)SQLMeshPodcast EpisodeCoalescePodcast EpisodeApache IcebergPodcast EpisodeDuckDB Podcast Episode SDF Classifiersdbt Semantic Layerdbt expectationsApache DatafusionIbisThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
In this episode, host Jason Foster sits down with Manuel Heichlinger, inclusivity leader and Managing Director at Audeliss. The pair discuss the myths that often plague conversations around diversity and inclusion within the professional workforce and debunk these assumptions. They also explore some of the unexpected benefits of a diverse workforce, including increased productivity, competitive advantage and fostering a deeper connection with the consumer base.
Cynozure is a leading data, analytics and AI company that helps organisations to reach their data potential. It works with clients on data and AI strategy, data management, data architecture and engineering, analytics and AI, data culture and literacy, and data leadership. The company was named one of The Sunday Times' fastest-growing private companies in both 2022 and 2023, and recognised as The Best Place to Work in Data by DataIQ in 2023.
Show Notes The Data Product Management In Action podcast, brought to you by Soda and executive producer Scott Hirleman, is a platform for data product management practitioners to share insights and experiences. In Season 01, Episode 18, our host Frannie Helforoush is back again interviewing Katy Pusch about her extensive experience in data product management, particularly with decision-support data products. Katy shares her insights on incorporating machine learning and analytics to empower stakeholders in making informed decisions. They both explore team structure, the challenges encountered in product development, and the critical importance of validating products with users to ensure their effectiveness. About our host Frannie Helforoush: Frannie's journey began as a software engineer and evolved into a strategic product manager. Now, as a data product manager, she leverages her expertise in both fields to create impactful solutions. Frannie thrives on making data accessible and actionable, driving product innovation, and ensuring product thinking is integral to data management. Connect with Frannie on LinkedIn. About our guest Katy Pusch: Katy brings more than a decade of experience in product management and market strategy, driving market change and adoption of innovative technology solutions. She has successfully built and launched data products, IoT solutions, and SaaS platforms in multiple industries such as healthcare, education, and real estate. She is currently serving as a Sr.Product Line Director at Trintech. With a background in research, she brings data science and market intelligence to every aspect of her work. Katy is passionate about data privacy and tech-ethics, and is pursuing an MS in History and Sociology of Technology and Science at GeorgiaTech. When she’s not working with her team to deliver top solutions, Katy enjoys spending time with her husband, building Lego models, and pursuing a private pilot license. Connect with Katy on LinkedIn. All views and opinions expressed are those of the individuals and do not necessarily reflect their employers or anyone else. Join the conversation on LinkedIn. Apply to be a guest or nominate someone that you know. Do you love what you're listening to? Please rate and review the podcast, and share it with fellow practitioners you know. Your support helps us reach more listeners and continue providing valuable insights!
Summary Airbyte is one of the most prominent platforms for data movement. Over the past 4 years they have invested heavily in solutions for scaling the self-hosted and cloud operations, as well as the quality and stability of their connectors. As a result of that hard work, they have declared their commitment to the future of the platform with a 1.0 release. In this episode Michel Tricot shares the highlights of their journey and the exciting new capabilities that are coming next. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementYour host is Tobias Macey and today I'm interviewing Michel Tricot about the journey to the 1.0 launch of Airbyte and what that means for the projectInterview IntroductionHow did you get involved in the area of data management?Can you describe what Airbyte is and the story behind it?What are some of the notable milestones that you have traversed on your path to the 1.0 release?The ecosystem has gone through some significant shifts since you first launched Airbyte. How have trends such as generative AI, the rise and fall of the "modern data stack", and the shifts in investment impacted your overall product and business strategies?What are some of the hard-won lessons that you have learned about the realities of data movement and integration?What are some of the most interesting/challenging/surprising edge cases or performance bottlenecks that you have had to address?What are the core architectural decisions that have proven to be effective?How has the architecture had to change as you progressed to the 1.0 release?A 1.0 version signals a degree of stability and commitment. Can you describe the decision process that you went through in committing to a 1.0 version?What are the most interesting, innovative, or unexpected ways that you have seen Airbyte used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on Airbyte?When is Airbyte the wrong choice?What do you have planned for the future of Airbyte after the 1.0 launch?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links AirbytePodcast EpisodeAirbyte CloudAirbyte Connector BuilderSinger ProtocolAirbyte ProtocolAirbyte CDKModern Data StackELTVector DatabasedbtFivetranPodcast EpisodeMeltanoPodcast EpisodedltReverse ETLGraphRAGAI Engineering Podcast EpisodeThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Uncle Rico is a character in the movie Napoleon Dynamite, who is stuck in the past, reminiscing about his days as a high school football star. If only he'd won the game and went to the state championship. Some of the data industry reminds me of Uncle Rico.
During a recent panel, there was a question about whether AI can help with data management (governance, modeling, etc).
Some people were quick to dismiss this, saying that machines are no substitute for humans in their understanding and translating of "the business" to data.
Yet why are we still perpetually stuck in the mode of "80% of data projects fail"? Might AI/ML help data management move out of its rut? Or will it stay stuck in the past?
Also, please check out my new data engineering course on Coursera!
https://www.coursera.org/learn/intro-to-data-engineering
Join this unique interactive session blending the analog art of puppetry with digital data storytelling. Through video clips, behind-the-scenes anecdotes, special guests, and the world premiere of new content, follow the CDO (Chief Dog Officer) and the IT Bee as they battle legacy opposition, CAT-sultants, and ANT-alysts in their quest for a data-driven utopia. This entertaining and insightful presentation offers humor, creativity, and actionable takeaways to transform the way you think about data management and inspire you to tell better data stories at your organization.
Top Takeaways:
• Analog Meets Digital: Discover how puppetry can convey complex digital concepts in a relatable and engaging way.
• Entertaining and Educational: data narratives come to life through a unique storytelling approach.
• Real-World Reflections: puppet adventures reveal the challenges of modern data management.