We’re improving DataFramed, and we need your help! We want to hear what you have to say about the show, and how we can make it more enjoyable for you—find out more here. We’re often caught chasing the dream of “self-serve” data—a place where data empowers stakeholders to answer their questions without a data expert at every turn. But what does it take to reach that point? How do you shape tools that empower teams to explore and act on data without the usual bottlenecks? And with the growing presence of natural language tools and AI, is true self-service within reach, or is there still more to the journey? Sameer Al-Sakran is the CEO at Metabase, a low-code self-service analytics company. Sameer has a background in both data science and data engineering so he's got a practitioner's perspective as well as executive insight. Previously, he was CTO at Expa and Blackjet, and the founder of SimpleHadoop and Adopilot. In the episode, Richie and Sameer explore self-serve analytics, the evolution of data tools, GenAI vs AI agents, semantic layers, the challenges of implementing self-serve analytics, the problem with data-driven culture, encouraging efficiency in data teams, the parallels between UX and data projects, exciting trends in analytics, and much more. Links Mentioned in the Show: MetabaseConnect with SameerArticles from Metabase on jargon, information budgets, analytics mistakes, and data model mistakesCourse: Introduction to Data CultureRelated Episode: Towards Self-Service Data Engineering with Taylor Brown, Co-Founder and COO at FivetranRewatch Sessions from RADAR: Forward Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
 talk-data.com
talk-data.com
Topic
Data Modelling
355
tagged
Activity Trend
Top Events
People often ask me for career advice. In a tough job market where people are sending out thousands of resumes and hearing nothing back, I notice a lot of people have weak networks and are unknown to the companies they're applying to. This results in lots of frustration and disappointment for job seekers.
Is there a better way? Yes. People need to know who you are. Obscurity is your enemy.
Also, the name of the Friday show changed because I can't seem to keep things to five minutes ;)
My works:
📕Fundamentals of Data Engineering: https://www.oreilly.com/library/view/fundamentals-of-data/9781098108298/
🎥 Deeplearning.ai Data Engineering Certificate: https://www.coursera.org/professional-certificates/data-engineering
🔥Practical Data Modeling: https://practicaldatamodeling.substack.com/
🤓 My SubStack: https://joereis.substack.com/
Let's do things the right way, not just the fast way.
My works:
📕Fundamentals of Data Engineering: https://www.oreilly.com/library/view/fundamentals-of-data/9781098108298/
🎥 Deeplearning.ai Data Engineering Certificate: https://www.coursera.org/professional-certificates/data-engineering
🔥Practical Data Modeling: https://practicaldatamodeling.substack.com/
🤓 My SubStack: https://joereis.substack.com/
I speak at a lot of conferences, and I've lost track of how many questions I've answered. Since conferences are top of mind for me right now, here are some tips for asking good (and bad) questions of speakers.
My works:
📕Fundamentals of Data Engineering: https://www.oreilly.com/library/view/fundamentals-of-data/9781098108298/
🎥 Deeplearning.ai Data Engineering Certificate: https://www.coursera.org/professional-certificates/data-engineering
🔥Practical Data Modeling: https://practicaldatamodeling.substack.com/
🤓 My SubStack: https://joereis.substack.com/
I've seen a TON of horror stories with tech debt and code migrations. It's estimated that 15% to 60% of every dollar in IT spend goes toward tech debt (that's a big range, I know). Regardless, most of this tech debt will not be paid down without a radical change in how we do things. Might AI be the Hail Mary we need to pay down tech debt? I don't see why not...
My works:
📕Fundamentals of Data Engineering: https://www.oreilly.com/library/view/fundamentals-of-data/9781098108298/
🎥 Deeplearning.ai Data Engineering Certificate: https://www.coursera.org/professional-certificates/data-engineering
🔥Practical Data Modeling: https://practicaldatamodeling.substack.com/
🤓 My SubStack: https://joereis.substack.com/

Adopting dbt marks a significant leap towards governed data transformations. But with every game-changer, big questions arise: Where do data transformations end? Should they touch the BI layer? What roles do data engineers, analytics engineers, and business analysts play in data modeling? And, is centralizing metrics truly beneficial? Spoiler: It's about finding the balance between freedom and governance.
Our expert panelists will share best practices for scaling dbt to handle transformations and metrics without stifling analyst freedom or causing team burnout. You'll learn how to build a robust metrics layer in dbt and manage business logic as your data operation grows, all by establishing a solid foundation with dbt.
Speakers: Mark Nelson, Silja Mardla, Patrick Vinton, Sarah Levy
Learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
Summary The rapid growth of generative AI applications has prompted a surge of investment in vector databases. While there are numerous engines available now, Lance is designed to integrate with data lake and lakehouse architectures. In this episode Weston Pace explains the inner workings of the Lance format for table definitions and file storage, and the optimizations that they have made to allow for fast random access and efficient schema evolution. In addition to integrating well with data lakes, Lance is also a first-class participant in the Arrow ecosystem, making it easy to use with your existing ML and AI toolchains. This is a fascinating conversation about a technology that is focused on expanding the range of options for working with vector data. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Weston Pace about the Lance file and table format for column-oriented vector storageInterview IntroductionHow did you get involved in the area of data management?Can you describe what Lance is and the story behind it?What are the core problems that Lance is designed to solve?What is explicitly out of scope?The README mentions that it is straightforward to convert to Lance from Parquet. What is the motivation for this compatibility/conversion support?What formats does Lance replace or obviate?In terms of data modeling Lance obviously adds a vector type, what are the features and constraints that engineers should be aware of when modeling their embeddings or arbitrary vectors?Are there any practical or hard limitations on vector dimensionality?When generating Lance files/datasets, what are some considerations to be aware of for balancing file/chunk sizes for I/O efficiency and random access in cloud storage?I noticed that the file specification has space for feature flags. How has that aided in enabling experimentation in new capabilities and optimizations?What are some of the engineering and design decisions that were most challenging and/or had the biggest impact on the performance and utility of Lance?The most obvious interface for reading and writing Lance files is through LanceDB. Can you describe the use cases that it focuses on and its notable features?What are the other main integrations for Lance?What are the opportunities or roadblocks in adding support for Lance and vector storage/indexes in e.g. Iceberg or Delta to enable its use in data lake environments?What are the most interesting, innovative, or unexpected ways that you have seen Lance used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on the Lance format?When is Lance the wrong choice?What do you have planned for the future of Lance?Contact Info LinkedInGitHubParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links Lance FormatLanceDBSubstraitPyArrowFAISSPineconePodcast EpisodeParquetIcebergPodcast EpisodeDelta LakePodcast EpisodePyLanceHilbert CurvesSIFT VectorsS3 ExpressWekaDataFusionRay DataTorch Data LoaderHNSW == Hierarchical Navigable Small Worlds vector indexIVFPQ vector indexGeoJSONPolarsThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA

Dive into the technical evolution of Bilt’s data infrastructure as they moved from fragmented, slow, and costly analytics to a streamlined, scalable, and holistic solution with dbt Cloud. In this session, the Bilt team will share how they implemented data modeling practices, established a robust CI/CD pipeline, and leveraged dbt’s Semantic Layer to enable a more efficient and trusted analytics environment. Attendees will gain a deep understanding of Bilt’s approach to data including: cost optimization, enhancing data accessibility and reliability, and most importantly, supporting scale and growth.
Speakers: Ben Kramer Director, Data & Analytics Bilt Rewards
James Dorado VP, Data Analytics Bilt Rewards
Nick Heron Senior Manager, Data Analytics Bilt Rewards
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
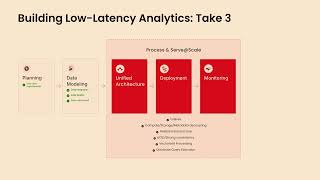
In this session Connor will dive into optimizing compute resources, accelerating query performance, and simplifying data transformations with dbt and cover in detail: - SQL-based data transformation, and why is it gaining traction as the preferred language with data engineers - Life cycle management for native objects like fact tables, dimension tables, primary indexes, aggregating indexes, join indexes, and others. - Declarative, version-controlled data modeling - Auto-generated data lineage and documentation
Learn about incremental models, custom materializations, and column-level lineage. Discover practical examples and real-world use cases how Firebolt enables data engineers to efficiently manage complex tasks and optimize data operations while achieving high efficiency and low latency on their data warehouse workloads.
Speaker: Connor Carreras Solutions Architect Firebolt
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

The workflow between dbt and BI is slowing us down. A simple change in dbt can require multiple teams to coordinate and hours of manual work to fix broken content. Valuable time is spent managing disconnected analytics tools that should work together seamlessly.
It’s time to tip the scales back toward speed — without compromising control. In this session, we’ll discuss how dbt and BI should work together. We’ll show you a workflow for moving fast in your BI tool, while still maintaining control of your data model in dbt.
Speaker: Chris Merrick Co-Founder & CTO Omni Analytics
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

For decades, siloed data modeling has been the norm: applications, analytics, and machine learning/AI. However, the emergence of AI, streaming data, and “shifting left" are changing data modeling, making siloed data approaches insufficient for the diverse world of data use cases. Today's practitioners must possess an end-to-end understanding of the myriad techniques for modeling data throughout the data lifecycle. This presentation covers "mixed model arts," which advocates converging various data modeling methods and the innovations of new ones.
Speaker: Joe Reis Author Nerd Herd
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
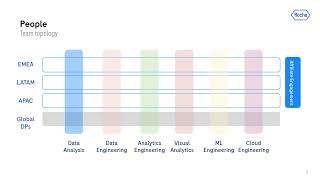
Centralize, harmonize, and streamline. That’s how Roche delivers self-service analytics to the thousands of people in its pharma commercial sector. Dbt is powering the backend solution that combines over 60 transactional systems into a harmonized simplified data model. By adopting a version-controlled approach and enabling end-to-end lineage tracking, we achieved significant reduction in duplication and accelerated time-to-insight for data-driven decision-making. The transition from a heterogeneous technology stack to standardized ways of working has fostered greater flexibility in allocating resources across the organization to address diverse use cases. Additionally, the scalable nature of this platform allows us to easily replicate successful data solutions globally. We further augmented our capabilities by integrating generative AI into our Redshift data warehouse, empowering the creation of innovative data products using dbt. This presentation will share practical lessons learned, architectural insights, and the tangible business impact realized from this data platform modernization.
Speaker: João Antunes Lead Engineer Hoffmann-La Roche
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Computational Intelligence in Sustainable Computing and Optimization: Trends and Applications focuses on developing and evolving advanced computational intelligence algorithms for the analysis of data involved in applications, such as agriculture, biomedical systems, bioinformatics, business intelligence, economics, disaster management, e-learning, education management, financial management, and environmental policies. The book presents research in sustainable computing and optimization, combining methods from engineering, mathematics, artificial intelligence, and computer science to optimize environmental resources Computational intelligence in the field of sustainable computing combines computer science and engineering in applications ranging from Internet of Things (IoT), information security systems, smart storage, cloud computing, intelligent transport management, cognitive and bio-inspired computing, and management science. In addition, data intelligence techniques play a critical role in sustainable computing. Recent advances in data management, data modeling, data analysis, and artificial intelligence are finding applications in energy networks and thus making our environment more sustainable. Presents computational, intelligence–based data analysis for sustainable computing applications such as pattern recognition, biomedical imaging, sustainable cities, sustainable transport, sustainable agriculture, and sustainable financial management Develops research in sustainable computing and optimization, combining methods from engineering, mathematics, and computer science to optimize environmental resources Includes three foundational chapters dedicated to providing an overview of computational intelligence and optimization techniques and their applications for sustainable computing
Is your data modelling limited by one person or a small team? Does the idea of scaling up the team sound too big of a challenge?
During this presentation, Simon will discuss the evolution of the data model, provide tips on what knowledge and resources are needed to build a data model, explore the common problems when scaling and discuss tooling, and what will help you work smarter, not harder.
This session will help you (or your team) to accelerate the creation of data models.
This talk will share lessons learned from building an internal data platform to support several Cybersecurity SaaS applications. At Tenable, we have put the data model at the centre of our platform. A centralised data model provides consistent data experience for your application builders and customers alike and provides a focus for discussion and standardisation.
The discussion will highlight the following key areas:
1. Choose cloud: Cloud will accelerate your rate of delivery and reduce cognitive load for your team
2. Get started: Platforms need users and their feedback should drive the evolution of the platform.
3. Maintaining a product mindset: Treat your data platform like a product by maintaining a backlog while working towards longer term vision.
4. Structure your team for success. Using lessons learned from Team Topologies, structure your team to reduce cognitive load and keep the team focussed on delivering value.
5. Making it easy for teams to onboard onto the platform.
For decades, data modeling has been fragmented by use cases: applications, analytics, and machine learning/AI. This leads to data siloing and “throwing data over the wall.”
With the emergence of AI, streaming data, and “shifting left" are changing data modeling, these siloed approaches are insufficient for the diverse world of data use cases. Today's practitioners must possess an end-to-end understanding of the myriad techniques for modeling data throughout the data lifecycle. This presentation covers "mixed model arts," which advocates converging various data modeling methods and the innovations of new ones.

Microsoft Power BI Performance Best Practices is your comprehensive guide to designing, optimizing, and scaling Power BI solutions. By understanding data modeling, DAX formulation, and report design, you will be able to enhance the efficiency and performance of your Power BI systems, ensuring that they meet the demands of modern data-driven decision-making. What this Book will help me do Understand and apply techniques for high-efficient data modeling to enhance Power BI performance and manage large datasets. Identify and resolve performance bottlenecks in Power BI reports and dashboards using tools like DAX Studio and VertiPaq Analyzer. Implement governance and monitoring strategies for Power BI performance to ensure robust and scalable systems. Gain expertise in leveraging Power BI Premium and Azure for handling larger scale data and integrations. Adopt best practices for designing, implementing row-level security, and optimizing queries for efficient operations. Author(s) Thomas LeBlanc and Bhavik Merchant are experienced professionals in the field of Business Intelligence and Power BI. Thomas brings over 30 years of IT expertise as a Business Intelligence Architect, ensuring practical and effective solutions for BI challenges. Bhavik is a recognized expert in enterprise-grade Power BI implementation. Together, they share actionable insights and strategies to make Power BI solutions advanced and highly performant. Who is it for? This book is ideal for data analysts, BI developers, and data professionals seeking to elevate their Power BI implementations. If you are proficient with the essentials of Power BI and aim to excel in optimizing its performance and scalability, this book will guide you to achieve those goals efficiently and effectively.

Discover how to design and optimize modern databases efficiently using PostgreSQL and MySQL. This book guides you through database design for scalability and performance, covering data modeling, query optimization, and real-world application integration. What this Book will help me do Build efficient and scalable relational database schemas for real-world applications. Master data modeling with normalization and denormalization techniques. Understand query optimization strategies for better database performance. Learn database strategies such as sharding, replication, and backup management. Integrate relational databases with applications and explore future database trends. Author(s) Alkin Tezuysal and Ibrar Ahmed are seasoned database professionals with decades of experience. Alkin specializes in database scalability and performance, while Ibrar brings expertise in database systems and development. Together, they bring a hands-on approach, providing clear and insightful guidance for database professionals. Who is it for? This book is oriented towards software developers, database administrators, and IT professionals looking to enhance their knowledge in database design using PostgreSQL and MySQL. Beginners in database design will find its structured approach approachable. Advanced professionals will appreciate its depth on cutting-edge topics and practical optimizations.
It's not enough to know or peddle one data modeling technique these days. That's like fighting in the UFC knowing only thumb-wrestling. The world is very complicated with respect to data. To be a data practitioner, you need to be awesome in not just one, but MANY data modeling techniques. This is what I call Mixed Model Arts, which will be discussed further soon. Anyway, don't be 1-dimensional. Know a lot about a lot.

Speaker: Jide Ogunjobi (Founder & CTO at Context Data)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. As organizations accumulate ever-larger stores of data across disparate systems, efficiently querying and gaining insights from enterprise data remain ongoing challenges. To address this, we propose developing an intelligent agent that can automatically discover, map, and query all data within an enterprise. This “Enterprise Data Model/Architect Agent” employs generative AI techniques for autonomous enterprise data modeling and architecture.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.