If Data Vault is a new term for you, it's a data modeling design pattern. We're joined by Brandon Taylor, a senior data architect at Guild, and Michael Olschimke, who is the CEO of Scalefree—the consulting firm whose co-founder Dan Lindstedt is credited as the designer of the data vault architecture. In this conversation with Tristan and Julia, Michael and Brandon explore the Data Vault approach among data warehouse design methodologies. They discuss Data Vault's adoption in Europe, its alignment with data mesh architecture, and the ongoing debate over Data Vault vs. Kimball methods. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
 talk-data.com
talk-data.com
Topic
Data Modelling
355
tagged
Activity Trend
Top Events
Many organizations abandoned data modeling as they embraced big data and NoSQL. Now they find that data modeling continues to be important, perhaps more important today than ever before. With a fresh look you’ll see that today’s data modeling is different from past practices – much more than physical design for relational data. Published at: https://www.eckerson.com/articles/a-fresh-look-at-data-modeling-part-1-the-what-and-why-of-data-modeling

Are you a reasonably competent Power BI user but still struggling to generate reports that truly tell the story of your data? Or do you simply want to extend your knowledge of Power BI by exploring more complex areas of visualizations, data modelling, DAX, and Power Query? If so, this book is for you. This book serves as a comprehensive resource for users to implement more challenging visuals, build better data models, use DAX with more confidence, and execute more complex queries so they can find and share important insights into their data. The contents of the chapters are in a question-and-answer format that explore everyday data analysis scenarios in Power BI. These questions have been generated from the author’s own client base and from commonly sought-for information from the Power BI community. They cover a wide and diverse range of topics that many Power BI users often struggle to get to grips with or don’t fully understand. Examples of suchquestions are: How can I generate dynamic titles for visuals? How can I control subtotals in a Matrix visual? Why do I need a date dimension? How can I show the previous N month’s sales in a column chart?Why do I need a Star Schema? Why aren't my totals correct? How can I bin measures into numeric ranges? Can I import a Word document? Can I dynamically append data from different source files? Solutions to these questions and many more are presented in non-technical and easy-to-follow explanations negating the requirement to perform tiresome and fruitless “google” searches. There are also companion Power BI Desktop files that set out the answers to each question so you can follow along with the examples given in the book.. After working through this book, you will have extended your knowledge of Power BI to an expert level, alleviating your existing frustrations and so enabling you to design Power BI reports where you are no longer limited by your lack of knowledge or experience. Who is This Book For: Power BI users who can build reports and now want to extend their knowledge of Power BI.

"Cracking the Data Engineering Interview" is your essential guide to mastering the data engineering interview process. This book offers practical insights and techniques to build your resume, refine your skills in Python, SQL, data modeling, and ETL, and confidently tackle over 100 mock interview questions. Gain the knowledge and confidence to land your dream role in data engineering. What this Book will help me do Craft a compelling data engineering portfolio to stand out to employers. Refresh and deepen understanding of essential topics like Python, SQL, and ETL. Master over 100 interview questions that cover both technical and behavioral aspects. Understand data engineering concepts such as data modeling, security, and CI/CD. Develop negotiation, networking, and personal branding skills crucial for job applications. Author(s) None Bryan and None Ransome are seasoned authors with a wealth of experience in data engineering and professional development. Drawing from their extensive industry backgrounds, they provide actionable strategies for aspiring data engineers. Their approachable writing style and real-world insights make complex topics accessible to readers. Who is it for? This book is ideal for aspiring data engineers looking to navigate the job application process effectively. Readers should be familiar with data engineering fundamentals, including Python, SQL, cloud data platforms, and ETL processes. It's tailored for professionals aiming to enhance their portfolios, tackle challenging interviews, and boost their chances of landing a data engineering role.

The team at nib Health has internal projects that contain standardized packages for running a dbt project, such as pipeline management, data testing, and data modeling macros. In this talk, they share how they utilized the yaml documentation files in dbt to create standardized tagging for both data security (PII), project tags, and product domain tags that get pushed into Snowflake, Immuta, and Select Star.
Speaker: Pip Sidaway, Data Product Manager, nib
Register for Coalesce at https://coalesce.getdbt.com

Learn about Watercare's journey in implementing a modern data stack with a focus on self serving analytics in the water industry. The session covers the reasons behind Watercare's decision to implement a modern data stack, the problem of data conformity, and the tools they used to accelerate their data modeling process. Diego also discusses the benefits of using dbt, Snowflake, and Azure DevOps in data modeling. There is also a parallel drawn between analytics and Diego’s connection with jazz music.
Speaker: Diego Morales, Civil Industrial Engineer, Watercare
Register for Coalesce at https://coalesce.getdbt.com

Every data team knows the importance of partnering with stakeholders across the business. In this session, Deputy's director of data shares how his team improved data modeling speed and accuracy, which led to more effective growth marketing initiatives and better sales conversion rates—which were essential for sourcing and forecasting new business.
Speaker: Huss Afzal, Data Director, Deputy
Register for Coalesce at https://coalesce.getdbt.com
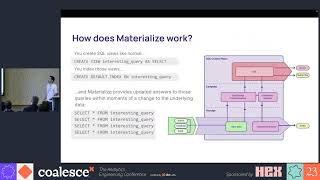
Traditional data warehouses excel at churning through terabytes of data for historical analysis. But for real-time, business-critical use cases, traditional data warehouses can’t produce results fast enough—and they still rack up a huge bill in the process.
So when Ramp’s data engineering team needed to serve complex analytics queries on the critical path of their production application, they knew they needed a new tool for the job. Enter Materialize, the first operational data warehouse. Like a traditional data warehouse, Materialize centralizes the data from all of a business’s production systems, from application databases to SaaS tools. But unlike a traditional data warehouse, Materialize enables taking immediate and automatic action when that data changes. Queries that once took hours or minutes to run are up-to-date in Materialize within seconds.
This talk presents how Ramp is unlocking new real-time use cases using Materialize as their operational data warehouse. The best part? The team still uses dbt for data modeling and deployment management, just like they are able to with their traditional batch workloads.
Speakers: Nikhil Benesch, CTO, Materialize; Ryan Delgado, Staff Software Engineer, Data Platform, Ramp
Register for Coalesce at https://coalesce.getdbt.com
As analytics engineers, we know that getting the data model right is crucial for successful data analytics. However, communicating requirements and needs can be a challenge, especially for junior data team members. After noticing too many post-PR revisions and missed requirements, Wellthy began developing a communication framework that has helped streamline and clarify the requirements gathering process for new models.
Their framework is designed to help analysts visualize and anticipate what they need from a dataset, resulting in a more efficient and effective data modeling process for the analytics engineer. In this talk, Kelly Pook shares Wellthy's experiences and best practices using these frameworks, as well as the benefits seen in terms of accuracy, efficiency, and time savings.
Speaker: Kelly Pook, Senior Analytics Engineer, Wellthy
Artyom Keydunov, Co-founder & CEO of Cube, discusses the future for the semantic layer, uniting BI tools, embedded analytics, and AI agents. This new approach brings together data, enabling data tools to introspect data model definitions and seamlessly interoperate within the data stack. By embracing this new approach—data practitioners will reap the benefits with enhanced user experiences, quicker data delivery, and streamlined workloads. See how a semantic layer can harmonize your data tools to drive maximum impact for yourself and end-users.
Speaker: Artyom Keydunov, Co-founder & CEO, Cube Dev
Register for Coalesce at https://coalesce.getdbt.com

Unlock the full potential of Microsoft Business Central by integrating it with the Power Platform through this practical and hands-on guide. With step-by-step tutorials, you'll learn how to combine the capabilities of tools like Power Apps, Power Automate, and Dataverse to build scalable and efficient business solutions. By the end of the book, you'll be equipped to streamline business processes and add significant value. What this Book will help me do Effectively deploy Power Platform functionalities for Microsoft Business Central projects. Seamlessly connect Business Central with cloud and on-premises services. Leverage Dataverse and virtual tables to enhance data modeling and accessibility. Build custom applications using Power Apps and automate workflows with Power Automate. Generate advanced visual reports with Power BI directly integrated with Business Central. Author(s) Kim Congleton and Shawn Sissenwein are industry professionals with extensive experience in ERP systems and Microsoft technologies. With a deep knowledge of Business Central and the Power Platform, they bring practical insights into maximizing business value through technological advancements. Their teaching approach focuses on hands-on learning, real-world application, and empowering readers with actionable skills. Who is it for? This book is ideal for Business Central users, consultants, and solution architects aiming to enhance Business Central's capabilities through the Power Platform. If you're familiar with Business Central's basics and seek to optimize and extend its functionality without requiring extensive programming knowledge, then this guide is tailored for you.

This talk was recorded at Crunch Conference 2022. Thomas from Tasman Analytics spoke about data modeling for startups.
"In this talk we will share our secrets on rapidly deploying analytics for our clients. As a business, we focus on setting up data infrastructure, data models and reporting, and do it as fast and as well as we can — but we also want to make sure that what we built is scaleable, and still relevant long after we leave."
The event was organized by Crafthub.
You can watch the rest of the conference talks on our channel.
If you are interested in more speakers, tickets and details of the conference, check out our website: https://crunchconf.com/ If you are interested in more events from our company: https://crafthub.events/
Is Kimball still relevant? Or should we just throw columnar storage and unlimited compute to solve our analytical needs?
Because I like to live on the edge, I respond to a comment online that I think highlights the rot in our industry as it relates to how we view data modeling today.
Data Modeling With Joe Reis - Understanding What Data Modeling Is And Where It's Going (Seattle Data Guy): https://www.youtube.com/watch?v=NKo02ThtAto
If you like this show, give it a 5-star rating on your favorite podcast platform.
Purchase Fundamentals of Data Engineering at your favorite bookseller.
Subscribe to my Substack: https://joereis.substack.com/
Imagine two extremes. On one end, data modeling is done perfectly and harmoniously across the data lifecycle. On the other end, data modeling is ignored and thrown into the dustbin of history. Along this spectrum, where do you think we are as a data industry?
I'm leaving this question open-ended right for now and would appreciate your thoughts.
If you like this show, give it a 5-star rating on your favorite podcast platform.
Purchase Fundamentals of Data Engineering at your favorite bookseller.
Subscribe to my Substack: https://joereis.substack.com/
Summary
For business analytics the way that you model the data in your warehouse has a lasting impact on what types of questions can be answered quickly and easily. The major strategies in use today were created decades ago when the software and hardware for warehouse databases were far more constrained. In this episode Maxime Beauchemin of Airflow and Superset fame shares his vision for the entity-centric data model and how you can incorporate it into your own warehouse design.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack Your host is Tobias Macey and today I'm interviewing Max Beauchemin about the concept of entity-centric data modeling for analytical use cases
Interview
Introduction How did you get involved in the area of data management? Can you describe what entity-centric modeling (ECM) is and the story behind it?
How does it compare to dimensional modeling strategies? What are some of the other competing methods Comparison to activity schema
What impact does this have on ML teams? (e.g. feature engineering)
What role does the tooling of a team have in the ways that they end up thinking about modeling? (e.g. dbt vs. informatica vs. ETL scripts, etc.)
What is the impact on the underlying compute engine on the modeling strategies used?
What are some examples of data sources or problem domains for which this approach is well suited?
What are some cases where entity centric modeling techniques might be counterproductive?
What are the ways that the benefits of ECM manifest in use cases that are down-stream from the warehouse?
What are some concrete tactical steps that teams should be thinking about to implement a workable domain model using entity-centric principles?
How does this work across business domains within a given organization (especially at "enterprise" scale)?
What are the most interesting, innovative, or unexpected ways that you have seen ECM used?
What are the most interesting, unexpected, or challenging lessons that you have learned while working on ECM?
When is ECM the wrong choice?
What are your predictions for the future direction/adoption of ECM or other modeling techniques?
Contact Info
mistercrunch on GitHub LinkedIn
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Entity Centric Modeling Blog Post Max's Previous Apperances
Defining Data Engineering with Maxime Beauchemin Self Service Data Exploration And Dashboarding With Superset Exploring The Evolving Role Of Data Engineers Alumni Of AirBnB's Early Years Reflect On What They Learned About Building Data Driven Organizations
Apache Airflow Apache Superset Preset Ubisoft Ralph Kimball The Rise Of The Data Engineer The Downfall Of The Data Engineer The Rise Of The Data Scientist Dimensional Data Modeling Star Schema Databas
I've spoken earlier about why I think data modeling is on life support, and if not dead, definitely a zombie. In this rant, I explore how we got here, the consequences, and what we can do to resurrect data modeling.
If you like this show, give it a 5-star rating on your favorite podcast platform.
Purchase Fundamentals of Data Engineering at your favorite bookseller.
Subscribe to my Substack: https://joereis.substack.com/
Summary
Architectural decisions are all based on certain constraints and a desire to optimize for different outcomes. In data systems one of the core architectural exercises is data modeling, which can have significant impacts on what is and is not possible for downstream use cases. By incorporating column-level lineage in the data modeling process it encourages a more robust and well-informed design. In this episode Satish Jayanthi explores the benefits of incorporating column-aware tooling in the data modeling process.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudderstack- Your host is Tobias Macey and today I'm interviewing Satish Jayanthi about the practice and promise of building a column-aware data architecture through intentional modeling
Interview
Introduction How did you get involved in the area of data management? How has the move to the cloud for data warehousing/data platforms influenced the practice of data modeling?
There are ongoing conversations about the continued merits of dimensional modeling techniques in modern warehouses. What are the modeling practices that you have found to be most useful in large and complex data environments?
Can you describe what you mean by the term column-aware in the context of data modeling/data architecture?
What are the capabilities that need to be built into a tool for it to be effectively column-aware?
What are some of the ways that tools like dbt miss the mark in managing large/complex transformation workloads? Column-awareness is obviously critical in the context of the warehouse. What are some of the ways that that information can be fed into other contexts? (e.g. ML, reverse ETL, etc.) What is the importance of embedding column-level lineage awareness into transformation tool vs. layering on top w/ dedicated lineage/metadata tooling? What are the most interesting, innovative, or unexpected ways that you have seen column-aware data modeling used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on building column-aware tooling? When is column-aware modeling the wrong choice? What are some additional resources that you recommend for individuals/teams who want to learn more about data modeling/column aware principles?
Contact Info
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Coalesce
Podcast Episode
Star Schema Conformed Dimensions Data Vault
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Rudderstack: 
RudderStack provides all your customer data pipeli
The word "model" is used a lot by data professionals. There are dbt models, machine learning models, relational models, and conceptual, logical, and physical models. My concern is we're missing the bigger picture of what data modeling was initially supposed to accomplish, which was to represent reality and structure it as data. The bigger implication is that our various "models" will become too myopic and miss the larger broader context of the reality of how we use data to serve our organizations.
If you like this show, give it a 5-star rating on your favorite podcast platform.
Purchase Fundamentals of Data Engineering at your favorite bookseller.
Subscribe to my Substack: https://joereis.substack.com/
George Park is a Czechia-based data engineer. We chat about automation, change management and culture, data modeling (Data Vault in particular), and much more. George lives on the front lines of helping customers, so this is a good discussion if you like to hear from a real practitioner.
George's LinkedIn: https://www.linkedin.com/in/george-park-599846136/
If you like this show, give it a 5-star rating on your favorite podcast platform.
Purchase Fundamentals of Data Engineering at your favorite bookseller.
Subscribe to my Substack: https://joereis.substack.com/
Summary
A significant portion of the time spent by data engineering teams is on managing the workflows and operations of their pipelines. DataOps has arisen as a parallel set of practices to that of DevOps teams as a means of reducing wasted effort. Agile Data Engine is a platform designed to handle the infrastructure side of the DataOps equation, as well as providing the insights that you need to manage the human side of the workflow. In this episode Tevje Olin explains how the platform is implemented, the features that it provides to reduce the amount of effort required to keep your pipelines running, and how you can start using it in your own team.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudderstack Your host is Tobias Macey and today I'm interviewing Tevje Olin about Agile Data Engine, a platform that combines data modeling, transformations, continuous delivery and workload orchestration to help you manage your data products and the whole lifecycle of your warehouse
Interview
Introduction How did you get involved in the area of data management? Can you describe what Agile Data Engine is and the story behind it? What are some of the tools and architectures that an organization might be able to replace with Agile Data Engine?
How does the unified experience of Agile Data Engine change the way that teams think about the lifecycle of their data? What are some of the types of experiments that are enabled by reduced operational overhead?
What does CI/CD look like for a data warehouse?
How is it different from CI/CD for software applications?
Can you describe how Agile Data Engine is architected?
How have the design and goals of the system changed since you first started working on it? What are the components that you needed to develop in-house to enable your platform goals?
What are the changes in the broader data ecosystem that have had the most influence on your product goals and customer adoption? Can you describe the workflow for a team that is using Agile Data Engine to power their business analytics?
What are some of the insights that you generate to help your customers understand how to improve their processes or identify new opportunities?
In your "about" page it mentions the unique approaches that you take for warehouse automation. How do your practices differ from the rest of the industry? How have changes in the adoption/implementation of ML and AI impacted the ways that your customers exercise your platform? What are the most interesting, innovative, or unexpected ways that you have seen the Agile Data Engine platform used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Agile Data Engine? When is Agile Data Engine the wrong choice? What do you have planned for the future of Agile Data Engine?
Guest Contact Info
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
About Agile Data Engine
Agile Data Engine unlocks the potential of your data to drive business value - in a rapidly changing world. Agile Data Engine is a DataOps Management platform for designing, deploying, operating and managing data products, and managing the whole lifecycle of a data warehouse. It combines data modeling, transformations, continuous delivery and workload orchestration into the same platform.
Links
Agile Data Engine Bill Inmon Ralph Kimball Snowflake Redshift BigQuery Azure Synapse Airflow
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Rudderstack:
RudderStack provides all your customer data pipelines in one platform. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
RudderStack’s warehouse-first approach means it does not store sensitive information, and it allows you to leverage your existing data warehouse/data lake infrastructure to build a single source of truth for every team.
RudderStack also supports real-time use cases. You can Implement RudderStack SDKs once, then automatically send events to your warehouse and 150+ business tools, and you’ll never have to worry about API changes again.
Visit dataengineeringpodcast.com/rudderstack to sign up for free today, and snag a free T-Shirt just for being a Data Engineering Podcast listener.Support Data Engineering Podcast