MLOps on Databricks: A How-To Guide
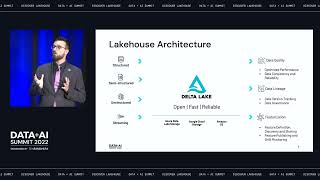
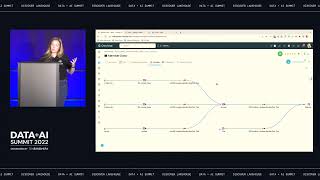
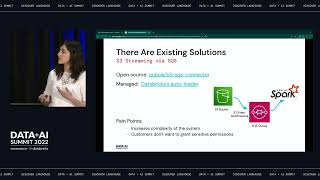
As companies roll out ML pervasively, operational concerns become the primary source of complexity. Machine Learning Operations (MLOps) has emerged as a practice to manage this complexity. At Databricks, we see firsthand how customers develop their MLOps approaches across a huge variety of teams and businesses. In this session, we will show how your organization can build robust MLOps practices incrementally. We will unpack general principles which can guide your organization’s decisions for MLOps, presenting the most common target architectures we observe across customers. Combining our experiences designing and implementing MLOps solutions for Databricks customers, we will walk through our recommended approaches to deploying ML models and pipelines on Databricks. You will come away with a deeper understanding of how to scale deployment of ML models across your organization, as well as a practical, coded example illustrating how to implement an MLOps workflow on Databricks.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/