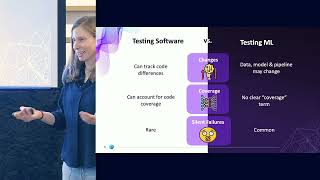
ABOUT THE TALK: In this talk, Dan Selans shows you how we developed a schema discovery process that is able to automatically evolve schemas in a complex distributed system that is processing upwards of a 100,000 messages per second.
He dives deep into the details of schema versioning, detecting schema conflicts, compatibility and normalization, all without the use of any batching processes.
He shows how they developed a schema discovery process that is able to automatically evolve schemas in a complex distributed system that is processing upwards of a 100,000 messages per second. He also details how to detect schema drift, determine compatibility and ultimately how to do all of this, without having to involve batching.
ABOUT THE SPEAKER: Daniel Selans is the co-founder and CTO of Streamdal.com, a streaming data performance monitoring company. Dan previously wrote software at companies such as InVisionApp, New Relic and DigitalOcean and before that, spent over 10 years doing integration and R&D work at data centers.
ABOUT DATA COUNCIL: Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL: Twitter: https://twitter.com/DataCouncilAI LinkedIn: https://www.linkedin.com/company/datacouncil