The need for adaptable data management architecture has never been more pressing. Yet getting there seems to be more confusing than ever. The field is rampant with buzzwords: data lake, data lakehouse, data fabric, data mesh, data hub, data as a network. Making sense of the confusion begins with sorting out the buzzwords. Published at: https://www.eckerson.com/articles/data-architecture-complex-vs-complicated
 talk-data.com
talk-data.com
Topic
Data Lake
big_data
data_storage
analytics
311
tagged
Activity Trend
28
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
125
Databricks DATA + AI Summit 2023
43
O'Reilly Data Engineering Books
39
Data + AI Summit 2025
15
Microsoft Ignite 2025
13
Secrets of Data Analytics Leaders
6
AWS re:Invent 2024
6
Big Data & AI Paris 2025
5
Big Data LDN 2025
4
Big Data LDN 2024
3
DATA MINER Big Data Europe Conference 2020
3
Making Data Simple
3
Summary The position of Chief Data Officer (CDO) is relatively new in the business world and has not been universally adopted. As a result, not everyone understands what the responsibilities of the role are, when you need one, and how to hire for it. In this episode Tracy Daniels, CDO of Truist, shares her journey into the position, her responsibilities, and her relationship to the data professionals in her organization.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. The only thing worse than having bad data is not knowing that you have it. With Bigeye’s data observability platform, if there is an issue with your data or data pipelines you’ll know right away and can get it fixed before the business is impacted. Bigeye let’s data teams measure, improve, and communicate the quality of your data to company stakeholders. With complete API access, a user-friendly interface, and automated yet flexible alerting, you’ve got everything you need to establish and maintain trust in your data. Go to dataengineeringpodcast.com/bigeye today to sign up and start trusting your analyses. Your host is Tobias Macey and today I’m interviewing Tracy Daniels about the role and responsibilities of the Chief Data Officer and how it is evolving along with the ecosystem
Interview
Introduction How did you get involved in the area of data management? Can you describe what your path to CDO of Truist has been?
As a CDO, what are your responsibilities and scope of influence?
Not every organization has an explicit position for the CDO. What are the factors that determine when that should be a distinct role?
What is the relationship and potential overlap with a CTO?
As the CDO of Truist, what are some of the projects/activities that are vying for your time and attention? Can you share the composition of your teams and how you think about organizational structure and integration for data professionals in your company? What are the industry and business trends that are having the greatest impact on your work as a
Summary The optimal format for storage and retrieval of data is dependent on how it is going to be used. For analytical systems there are decades of investment in data warehouses and various modeling techniques. For machine learning applications relational models require additional processing to be directly useful, which is why there has been a growth in the use of vector databases. These platforms store direct representations of the vector embeddings that machine learning models rely on for computing relevant predictions so that there is no additional processing required to go from input data to inference output. In this episode Frank Liu explains how the open source Milvus vector database is implemented to speed up machine learning development cycles, how to think about proper storage and scaling of these vectors, and how data engineering and machine learning teams can collaborate on the creation and maintenance of these data sets.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Data stacks are becoming more and more complex. This brings infinite possibilities for data pipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. Sifflet solves this problem by acting as an overseeing layer to the data stack – observing data and ensuring it’s reliable from ingestion all the way to consumption. Whether the data is in transit or at rest, Sifflet can detect data quality anomalies, assess business impact, identify the root cause, and alert data teams’ on their preferred channels. All thanks to 50+ quality checks, extensive column-level lineage, and 20+ connectors across the Data Stack. In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses. Listeners of the podcast will get $2000 to use as platform credits when signing up to use Sifflet. Sifflet also offers a 2-week free trial. Find out more at dataengineeringpodcast.com/sifflet today! RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines
Summary Exploratory data analysis works best when the feedback loop is fast and iterative. This is easy to achieve when you are working on small datasets, but as they scale up beyond what can fit on a single machine those short iterations quickly become long and tedious. The Arkouda project is a Python interface built on top of the Chapel compiler to bring back those interactive speeds for exploratory analysis on horizontally scalable compute that parallelizes operations on large volumes of data. In this episode David Bader explains how the framework operates, the algorithms that are built into it to support complex analyses, and how you can start using it today.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Data stacks are becoming more and more complex. This brings infinite possibilities for data pipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. Sifflet solves this problem by acting as an overseeing layer to the data stack – observing data and ensuring it’s reliable from ingestion all the way to consumption. Whether the data is in transit or at rest, Sifflet can detect data quality anomalies, assess business impact, identify the root cause, and alert data teams’ on their preferred channels. All thanks to 50+ quality checks, extensive column-level lineage, and 20+ connectors across the Data Stack. In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses. Listeners of the podcast will get $2000 to use as platform credits when signing up to use Sifflet. Sifflet also offers a 2-week free trial. Find out more at dataengineeringpodcast.com/sifflet today! RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodc

Unlocking the value of modern data is critical for data-driven companies. This report provides a concise, practical guide to building a data architecture that efficiently delivers big, complex, and streaming data to both internal users and customers. Authors Ori Rafael, Roy Hasson, and Rick Bilodeau from Upsolver examine how modern data pipelines can improve business outcomes. Tech leaders and data engineers will explore the role these pipelines play in the data architecture and learn how to intelligently consider tradeoffs between different data architecture patterns and data pipeline development approaches. You will: Examine how recent changes in data, data management systems, and data consumption patterns have made data pipelines challenging to engineer Learn how three data architecture patterns (event sourcing, stateful streaming, and declarative data pipelines) can help you upgrade your practices to address modern data Compare five approaches for building modern data pipelines, including pure data replication, ELT over a data warehouse, Apache Spark over data lakes, declarative pipelines over data lakes, and declarative data lake staging to a data warehouse
Summary The current stage of evolution in the data management ecosystem has resulted in domain and use case specific orchestration capabilities being incorporated into various tools. This complicates the work involved in making end-to-end workflows visible and integrated. Dagster has invested in bringing insights about external tools’ dependency graphs into one place through its "software defined assets" functionality. In this episode Nick Schrock discusses the importance of orchestration and a central location for managing data systems, the road to Dagster’s 1.0 release, and the new features coming with Dagster Cloud’s general availability.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Nick Schrock about software defined assets and improving the developer experience for data orchestration with Dagster
Interview
Introduction How did you get involved in the area of data management? What are the notable updates in Dagster since the last time we spoke? (November, 2021) One of the core concepts that you introduced and then stabilized in recent releases is the "software defined asset" (SDA). How have your users reacted to this capability?
What are the notable outcomes in development and product practices that you have seen as a result?
What are the changes to the interfaces and internals of Dagster that were necessary to support SDA? How did the API design shift from the initial implementation once the community started providing feedback? You’re releasing the stable 1.0 version of Dagster as part of something call

A common pattern in Data Lake and Lakehouse design is structuring data into zones, with Bronze, Silver and Gold being typical labels. Each zone is suitable for different workloads and different consumers: for instance, machine learning algorithms typically process against Bronze or Silver, while analytic dashboards often query Gold. This prompts the question: which layer is best suited for applying data quality rules and actions? Our answer: all of them.
In this session, we’ll expand on our answer by describing the purposes of the different zones, and mapping the categories of data quality relevant for each by assessing its qualitative requirements. We’ll describe Data Enrichment: the practice of making observed anomalies available as inputs to downstream data pipelines, and provide recommendations for when to merely alert, when to quarantine data, when to halt pipelines, and when to apply automated corrective actions.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Most organizations run complex cloud data architectures that silo applications, users, and data. As a result, most analysis is performed with stale data and there isn’t a single source of truth of data for analytics.
Join this interactive follow-along deep dive demo to learn how Databricks SQL allows you to operate a multicloud lakehouse architecture that delivers data warehouse performance at data lake economics — with up to 12x better price/performance than traditional cloud data warehouses. Now data analysts and scientists can work with the freshest and most complete data and quickly derive new insights for accurate decision-making.
Here’s what we’ll cover: • Managing data access and permissions and monitoring how the data is being used and accessed in real time across your entire lakehouse infrastructure • Configuring and managing compute resources for fast performance, low latency, and high user concurrency to your data lake • Creating and working with queries, dashboards, query refresh, troubleshooting features and alerts • Creating connections to third-party BI and database tools (Power BI, Tableau, DbVisualizer, etc.) so that you can query your lakehouse without making changes to your analytical and dashboarding workflows
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Organizations want data lakes to be the source of truth for analytics. But operational teams rarely recognize the power the data lake, shortening the reach of all the valuable data within it. Instead, these business users often treat operational tools like Salesforce, Marketo, and NetSuite as their source of truth.
The reality is lakehouses and operational tools alike have missed critical pieces of data and don’t provide the full customer picture. Operational Analytics solves this last mile problem by making it possible to sync transformed data directly from your data lake back into these systems to expand the reach of your data.
In this talk you’ll learn: - What Operational Analytics & Reverse ETL are and why they're taking off - How Operational Analytics helps companies today activate and expand the reach of their data - Real-life use cases from companies using Operational Analytics to empower their data teams & give them the seat at the table they deserve
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Apache Kafka is the de facto standard for real-time event streaming, but what do you do if you want to perform user-facing, ad-hoc, real-time analytics too? That's where Apache Pinot comes in.
Apache Pinot is a realtime distributed OLAP datastore, which is used to deliver scalable real time analytics with low latency. It can ingest data from batch data sources (S3, HDFS, Azure Data Lake, Google Cloud Storage) as well as streaming sources such as Kafka. Pinot is used extensively at LinkedIn and Uber to power many analytical applications such as Who Viewed My Profile, Ad Analytics, Talent Analytics, Uber Eats and many more serving 100k+ queries per second while ingesting 1Million+ events per second.
Apache Kafka's highly performant, distributed, fault-tolerant, real-time publish-subscribe messaging platform powers big data solutions at Airbnb, LinkedIn, MailChimp, Netflix, the New York Times, Oracle, PayPal, Pinterest, Spotify, Twitter, Uber, Wikimedia Foundation, and countless other businesses.
Come hear from Neha Power, Founding Engineer at a StarTree and PMC and committer of Apache Pinot, and Karin Wolok, Head of Developer Community at StarTree, on an introduction to both systems and a view of how they work together.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Due to the unique cybersecurity challenges that HSBC faces daily - from high data volumes to untrustworthy sources to the privacy and security restrictions of a highly regulated industry - the resulting architecture was an unwieldy set of disparate data silos. So, how do we build a cybersecurity advanced analytics environment to enrich and transform these myriad data sources into a unified, well-documented, robust, resilient, repeatable, scalable, maintainable platform that will empower the cyber analysts of the future? That at the same time remains cost-effective and enables everyone from the less-technical junior reporting user to the senior machine learning engineers?
In this session, Ryan Harris, Principal Cybersecurity Engineer at HSBC, dives into the infrastructure and architecture employed, ranging from the landing zone concepts, secure access workstations, data lake structure, and isolated data ingestion, to the enterprise integration layer. In the process of building the data pipelines and lakehouses, we ended up building a hybrid data mesh leveraging Delta Lake. The result is a flexible, secure, self-service environment that is unlocking the capabilities of our humans.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

"Why did our dashboard break?" "What happened to my data?" "Why is this column missing?" If you've been on the receiving end of these messages (and many others!) from downstream stakeholders, you're not alone. Data engineering teams spend 40 percent or more of their time tackling data downtime, or periods of time when data is missing, erroneous, or otherwise inaccurate, and as data systems become increasingly complex and distributed, this number will only increase. To address this problem, data observability is becoming an increasingly important part of the cloud data stack, helping engineers and analysts reduce time to detection and resolution for data incidents caused by faulty data, code, and operational environments. But what does data observability actually look like in practice? During this presentation, Barr Moses, CEO and co-founder of Monte Carlo, will present on how some of today's best data leaders implement observability across their data lake ecosystem and share best practices for data teams seeking to achieve end-to-end visibility into their data at scale. Topics addressed will include: building automated lineage for Apache Spark, applying data reliability workflows, and extending beyond testing and monitoring to solve for unknown unknowns in your data pipelines.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Delta Lake has quickly grown in usage across data lakes everywhere due to the growing use cases that require DML capabilities that Delta Lake brings. Outside of support for ACID transactions, users want the ability to interactively query the data in their data lake. This is where a query engine like Trino (formerly PrestoSQL) comes in. Starburst provides an enterprise version of the popular Trino MPP SQL query engine and has recently open sourced their Delta Lake connector.
In this talk, Tom and Claudius will talk about the connector, its features, and how their users are taking advantage of expanding the functionality of their data lakes with improved performance and the ability to handle colliding modifications. Get started with this feature-rich and open stack without the need of a multi-million dollar budget.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Amgen has developed a suite of enterprise data & analytics platforms powered by modern, cloud native and open source technologies, that have played a vital role in building game changing analytics capabilities within the organization. Our platforms include a mature Data Lake with extensive self service capabilities, a Data Fabric with semantically connected data, a Data Marketplace for advanced cataloging, an intelligent Enterprise search among others to solve for a range of high value business problems. In this talk, we - Amgen and our partner ZS Associates - will share learning from our journey so far, best practices for building enterprise scale data & analytics platforms, and describe several business use cases and how we leverage modern technologies such as Databricks to enable our business teams. We will cover use cases related to Delta Lake, microservices, platform monitoring, fine grained security, and more.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

John Deere’s Expert alerts is a proactive monitoring system that notifies dealers of potential machine issues. This allows technicians to diagnose issues remotely and fix them before they become a problem thereby avoiding multiple trips by a repair technician and minimizing downtime. John Deere ingests petabytes of data every year from its Connected Machines across the globe. To improve the availability, uptime and performance of the John Deere machines globally, our data scientists perform machine data analysis on our data lake in an efficient and scalable manner. The result is dramatically improved mean time to repair, decreased downtime with predictive alerts, improved cost efficiency, improved customer satisfaction and great yields and results for John Deere’s customers.
You will learn • What are Experts Alerts at John Deere and what challenges they seek to solve • How John Deere migrated from a legacy application for alerting to flexible and scalable Lakehouse framework • Getting stakeholder buy in and converting business logic to AI • Overcoming the scale problem: processing petabytes of data within SLAs • What is next for Alert
Other Resources • Two Minute Overview of Expert Alerts: https://www.youtube.com/watch?v=yFnMhMhipXA • Expert Alerts: Dealer Execution - John Deere: https://www.youtube.com/watch?v=2FGz0lx4UiM • Ben Burgess FarmSight services - Expert Alerts from John Deere: https://www.youtube.com/watch?v=BrQhX4oCsSw • U.S. Farm Report Driving Technology: John Deere Expert Alerts: https://www.youtube.com/watch?v=h8IGtk61EDo
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Presto was originally designed to run interactive queries against data warehouses, but now it has evolved into a unified SQL engine on top of open data lake analytics for both interactive and batch workloads. However, Presto doesn't scale to very large and complex batch pipelines. Presto Unlimited was designed to address such scalability challenges but it didn’t fully solve fault tolerance, isolation, and resource management.
Spark is the tool of choice across the industry for running large scale complex batch ETL pipelines. This motivated the development of Presto On Spark. Presto on Spark runs Presto as a library that is submitted with spark-submit to a Spark cluster. It leverages Spark for scaling shuffle, worker execution, and resource management. It thereby eliminates any query conversion between interactive and batch use cases. This solution helps enable a performant and scalable platform with seamless end-to-end experience to explore and process data.
Many analysts at Intuit use Presto to explore data in the Data Lake/S3 and use Spark for batch processing. These analysts would earlier spend several hours converting these exploration SQLs written for Presto to Spark SQL to operationalize/schedule them as data pipelines. Presto On Spark is now used by analysts at Intuit to run thousands of critical jobs. No query conversion is required here, improved analysts' productivity and empowered them to deliver insights at high speed.
Benefits from session: Attendees will learn about Presto On Spark architecture Attendees will learn when To Use Spark's Execution Engine With Presto Attendees will learn how Intuit runs thousands of presto jobs daily leveraging databricks platform which they can apply to their own work
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
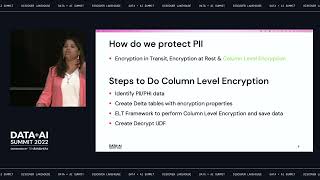
Data breach is a concern for any data collection company including Northwestern mutual. Every measure is taken to avoid the identity theft and fraud for our customers; however they are still not sufficient if the security around it is not updated periodically. A multiple layer of encryption is the most common approach utilized to avoid breaches however unauthorized internal access to this sensitive data still poses a threat
This presentation will walk you following steps: - Design to build encryption at column level - How to protect PII data that is used as key for joins - Ability for authorized users to decrypt data at run time - Ability to rotate the encryption keys if needed
At Northwestern Mutual, a combination of Fernet, AES encryption libraries, user-defined functions (UDFs), and Databricks secrets, were utilized to develop a process to encrypt PII information. Access was only provided to those with a business need to decrypt it, this helps avoids the internal threat. This is also done without data duplication or metadata (view/tables) duplication. Our goal is to help you understand on how you can build a secure data lake for your organization which can eliminate threats of data breach internally and externally. Associated blog: https://databricks.com/blog/2020/11/20/enforcing-column-level-encryption-and-avoiding-data-duplication-with-pii.html
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

To learn more, visit the Databricks Security and Trust Center: https://www.databricks.com/trust
As you embark on a lakehouse project or evolve your existing data lake, you may want to improve your security posture and take advantage of new security features—there may even be a security team at your company that demands it! Databricks has worked with thousands of customers to securely deploy the Databricks Platform to meet their architecture and security requirements. While many organizations deploy security differently, we have found a common set of guidelines and features among organizations who require a high level of security. In this talk, we will detail the security features and architectural choices frequently used by these organizations and walk through a series of threat models for the risks that most concern security teams. While this session is great for people who already know Databricks, don’t worry, that knowledge isn’t required.
You will walk away with a full handbook detailing all of the concepts, configurations, and code from the session so that you can make immediate progress when you get back to the office. Security can be hard, but we’ve collected the hard work already done by some of the best in the industry, to make it easier. Come learn how.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Apache Kafka in conjunction with Apache Spark became the de facto standard for processing and analyzing data. Both frameworks are open, flexible, and scalable. Unfortunately, the latter makes operations a challenge for many teams. Ideally, teams can use serverless SaaS offerings to focus on business logic. However, hybrid and multi-cloud scenarios require a cloud-native platform that provides automated and elastic tooling to reduce the operations burden.
This post explores different architecture to build serverless Kafka and Spark multi-cloud architectures across regions and continents. We start from the analytics perspective of a data lake and explore its relation to a fully integrated data streaming layer with Kafka to build a modern data lakehouse. Real-world use cases show the joint value and explore the benefit of the "delta lake" integration.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
One of the largest State based health exchanges in the country was looking to modernize their data warehouse (DWH) environment to support the vision that every decision to design, implement and evaluate their state-based health exchange portal is informed by timely and rigorous evidence about its consumers’ experiences. The scope of the project was to replace existing Oracle-based DWH with an analytics platform that could support a much broader range of requirements with an ability to provide unified analytics capabilities including machine learning. The modernized analytics platform comprises a cloud native data lake and DWH solution using Databricks. The solution provides significantly higher performance and elastic scalability to better handle larger and varying data volumes with a much lower cost of ownership compared to the existing solution. In this session, we will walk through the rationale behind tool selection, solution architecture, project timeline and benefits expected.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/