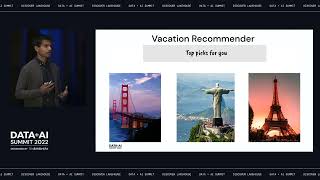
This talk will look at the current state of tools to automate library and language upgrades in Python and Scala and apply them to upgrading to new version of Apache Spark. After doing a very informal survey, it seems that many users are stuck on no longer supported versions of Spark, so this talk will expand on the first attempt at automating upgrades (2.4 - 3.0) to explore the problem all the way back to 2.1.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/