DuckDB is well-loved by SQL-ophiles to handle their small data workloads. How do you make it scale? What happens when you feed it Big Data? What is this DuckLake thing I've been hearing about? This talk will help answer these questions from real-world experience running a DuckDB service in the cloud.
 talk-data.com
talk-data.com
Topic
SQL
Structured Query Language (SQL)
database_language
data_manipulation
data_definition
programming_language
1751
tagged
Activity Trend
107
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Engineering Books
780
Data Engineering Podcast
233
O'Reilly SQL Books
103
Data + AI Summit 2025
89
O'Reilly Data Science Books
82
Databricks DATA + AI Summit 2023
73
Microsoft Ignite 2025
46
Google Cloud Next '25
29
O'Reilly Business Intelligence Books
25
Google Cloud Next '24
21
Data Career Podcast: Helping You Land a Data Analyst Job FAST
18
dbt Coalesce 2022
14
Analytics engineers are at a crossroads. Back in 2018, dbt paved the way for for this new kind of data professional, people who had technical ability and could understand business context. But here's the thing: AI is automating traditional tasks like pipeline building and dashboard creation. So then what happens to analytics engineers? They don't disappear - they evolve.
The same skills that made analytics engineers valuable also make them perfect for a new role I'm calling 'Analytics Intelligence Engineers.' Instead of writing SQL, they're writing the context that makes AI actually useful for business users.
In this talk, I'll show you what this evolution looks like day-to-day. We'll explore building semantic layers, crafting AI context, and measuring AI performance - all through real examples using Lightdash. You'll see how the work shifts from data plumbing to data intelligence, and walk away with practical tips for making AI tools more effective in your organization. Whether you're an analytics engineer wondering about your future or a leader planning your data strategy, this session will help you understand where the field is heading and how to get there.
The relationship between AI assistants and data professionals is evolving rapidly, creating both opportunities and challenges. These tools can supercharge workflows by generating SQL, assisting with exploratory analysis, and connecting directly to databases—but they're far from perfect. How do you maintain the right balance between leveraging AI capabilities and preserving your fundamental skills? As data teams face mounting pressure to deliver AI-ready data and demonstrate business value, what strategies can ensure your work remains trustworthy? With issues ranging from biased algorithms to poor data quality potentially leading to serious risks, how can organizations implement responsible AI practices while still capitalizing on the positive applications of this technology? Christina Stathopoulos is an international data specialist who regularly serves as an executive advisor, consultant, educator, and public speaker. With expertise in analytics, data strategy, and data visualization, she has built a distinguished career in technology, including roles at Fortune 500 companies. Most recently, she spent over five years at Google and Waze, leading data strategy and driving cross-team projects. Her professional journey has spanned both the United States and Spain, where she has combined her passion for data, technology, and education to make data more accessible and impactful for all. Christina also plays a unique role as a “data translator,” helping to bridge the gap between business and technical teams to unlock the full value of data assets. She is the founder of Dare to Data, a consultancy created to formalize and structure her work with some of the world’s leading companies, supporting and empowering them in their data and AI journeys. Current and past clients include IBM, PepsiCo, PUMA, Shell, Whirlpool, Nitto, and Amazon Web Services.
In the episode, Richie and Christina explore the role of AI agents in data analysis, the evolving workflow with AI assistance, the importance of maintaining foundational skills, the integration of AI in data strategy, the significance of trustworthy AI, and much more.
Links Mentioned in the Show: Dare to DataJulius AIConnect with ChristinaCourse - Introduction to SQL with AIRelated Episode: The Data to AI Journey with Gerrit Kazmaier, VP & GM of Data Analytics at Google CloudRewatch RADAR AI
New to DataCamp? Learn on the go using the DataCamp mobile app Empower your business with world-class data and AI skills with DataCamp for business
Summary In this episode of the AI Engineering Podcast Mark Brooker, VP and Distinguished Engineer at AWS, talks about how agentic workflows are transforming database usage and infrastructure design. He discusses the evolving role of data in AI systems, from traditional models to more modern approaches like vectors, RAG, and relational databases. Mark explains why agents require serverless, elastic, and operationally simple databases, and how AWS solutions like Aurora and DSQL address these needs with features such as rapid provisioning, automated patching, geodistribution, and spiky usage. The conversation covers topics including tool calling, improved model capabilities, state in agents versus stateless LLM calls, and the role of Lambda and AgentCore for long-running, session-isolated agents. Mark also touches on the shift from local MCP tools to secure, remote endpoints, the rise of object storage as a durable backplane, and the need for better identity and authorization models. The episode highlights real-world patterns like agent-driven SQL fuzzing and plan analysis, while identifying gaps in simplifying data access, hardening ops for autonomous systems, and evolving serverless database ergonomics to keep pace with agentic development.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData teams everywhere face the same problem: they're forcing ML models, streaming data, and real-time processing through orchestration tools built for simple ETL. The result? Inflexible infrastructure that can't adapt to different workloads. That's why Cash App and Cisco rely on Prefect. Cash App's fraud detection team got what they needed - flexible compute options, isolated environments for custom packages, and seamless data exchange between workflows. Each model runs on the right infrastructure, whether that's high-memory machines or distributed compute. Orchestration is the foundation that determines whether your data team ships or struggles. ETL, ML model training, AI Engineering, Streaming - Prefect runs it all from ingestion to activation in one platform. Whoop and 1Password also trust Prefect for their data operations. If these industry leaders use Prefect for critical workflows, see what it can do for you at dataengineeringpodcast.com/prefect.Data migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Your host is Tobias Macey and today I'm interviewing Marc Brooker about the impact of agentic workflows on database usage patterns and how they change the architectural requirements for databasesInterview IntroductionHow did you get involved in the area of data management?Can you describe what the role of the database is in agentic workflows?There are numerous types of databases, with relational being the most prevalent. How does the type and purpose of an agent inform the type of database that should be used?Anecdotally I have heard about how agentic workloads have become the predominant "customers" of services like Neon and Fly.io. How would you characterize the different patterns of scale for agentic AI applications? (e.g. proliferation of agents, monolithic agents, multi-agent, etc.)What are some of the most significant impacts on workload and access patterns for data storage and retrieval that agents introduce?What are the categorical differences in that behavior as compared to programmatic/automated systems?You have spent a substantial amount of time on Lambda at AWS. Given that LLMs are effectively stateless, how does the added ephemerality of serverless functions impact design and performance considerations around having to "re-hydrate" context when interacting with agents?What are the most interesting, innovative, or unexpected ways that you have seen serverless and database systems used for agentic workloads?What are the most interesting, unexpected, or challenging lessons that you have learned while working on technologies that are supporting agentic applications?Contact Info BlogLinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links AWS Aurora DSQLAWS LambdaThree Tier ArchitectureVector DatabaseGraph DatabaseRelational DatabaseVector EmbeddingRAG == Retrieval Augmented GenerationAI Engineering Podcast EpisodeGraphRAGAI Engineering Podcast EpisodeLLM Tool CallingMCP == Model Context ProtocolA2A == Agent 2 Agent ProtocolAWS Bedrock AgentCoreStrandsLangChainKiroThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
CANCELLED The often overlooked, but crucial skill for success in analytics engineering is data analysis. But many analytics engineers only touch the surface. I will share with you six effective habits for improving your data analysis skills that you can apply in your daily work. With many examples from practice in technical data analysis using SQL.
Text-to-SQL promised self-serve analytics, but it failed to deliver trust. Accuracy plateaued, context was lost, and hallucinations eroded confidence. In this talk, we’ll explore what comes after: reliable, proactive AI analytics powered by semantic understanding and agentic systems.
Discover how Nationale-Nederlanden revolutionized its database infrastructure in this compelling case study. Join Matheus as he unveils the strategic journey from legacy Oracle and SQL Server on-premises systems to Amazon Aurora PostgreSQL Serverless v2. Get practical insights into architectural decisions, migration strategies, and key lessons learned from one of Europe's largest financial institutions.
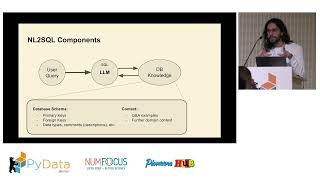
This hands-on tutorial will guide participants through building an end-to-end AI agent that translates natural language questions into SQL queries, validates and executes them on live databases, and returns accurate responses. Participants will build a system that intelligently routes between a specialized SQL agent and a ReAct chat agent, implementing RAG for query similarity matching, comprehensive safety validation, and human-in-the-loop confirmation. By the end of this session, attendees will have created a powerful and extensible system they can adapt to their own data sources.

Are your SQL queries becoming tangled webs that are difficult to decipher, debug, and maintain? This talk explores how to write shorter, more debuggable, and extensible SQL code using Pipelined SQL, an alternative syntax where queries are written as a series of orthogonal, understandable steps. We'll survey which databases and query engines currently support pipelined SQL natively or through extensions, and how it can be used on any platform by compiling pipelined SQL to any SQL dialect using open-source tools. A series of real-world examples, comparing traditional and pipelined SQL syntax side by side for a variety of use cases, will show you how to simplify existing code and make complex data transformations intuitive and manageable.
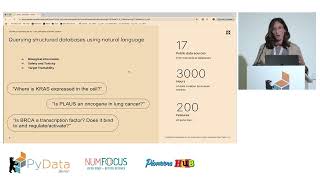
With a focus on healthcare applications where accuracy is non negotiable, this talk highlights challenges and delivers practical insights on building AI agents which query complex biological and scientific data to answer sophisticated questions. Drawing from our experience developing Owkin-K Navigator, a free-to-use AI co-pilot for biological research, I'll share hard-won lessons about combining natural language processing with SQL querying and vector database retrieval to navigate large biomedical knowledge sources, addressing challenges of preventing hallucinations and ensuring proper source attribution. This session is ideal for data scientists, ML engineers, and anyone interested in applying python and LLM ecosystem to the healthcare domain.
Here are 5 exciting and unique data analyst projects that will build your skills and impress hiring managers! These range from beginner to advanced and are designed to enhance your data storytelling abilities. ✨ Try Julius today at https://landadatajob.com/Julius-YT Where I Go To Find Datasets (as a data analyst) 👉 https://youtu.be/DHfuvMyBofE?si=ABsdUfzgG7Nsbl89 💌 Join 10k+ aspiring data analysts & get my tips in your inbox weekly 👉 https://www.datacareerjumpstart.com/newsletter 🆘 Feeling stuck in your data journey? Come to my next free "How to Land Your First Data Job" training 👉 https://www.datacareerjumpstart.com/training 👩💻 Want to land a data job in less than 90 days? 👉 https://www.datacareerjumpstart.com/daa 👔 Ace The Interview with Confidence 👉 https://www.datacareerjumpstart.com/interviewsimulator
⌚ TIMESTAMPS 00:00 - Introduction 00:24 - Project 1: Stock Price Analysis 03:46 - Project 2: Real Estate Data Analysis (SQL) 07:52 - Project 3: Personal Finance Dashboard (Tableau or Power BI) 11:20 - Project 4: Pokemon Analysis (Python) 14:16 - Project 5: Football Data Analysis (any tool)
🔗 CONNECT WITH AVERY 🎥 YouTube Channel: https://www.youtube.com/@averysmith 🤝 LinkedIn: https://www.linkedin.com/in/averyjsmith/ 📸 Instagram: https://instagram.com/datacareerjumpstart 🎵 TikTok: https://www.tiktok.com/@verydata 💻 Website: https://www.datacareerjumpstart.com/ Mentioned in this episode: Join the last cohort of 2025! The LAST cohort of The Data Analytics Accelerator for 2025 kicks off on Monday, December 8th and enrollment is officially open!
To celebrate the end of the year, we’re running a special End-of-Year Sale, where you’ll get: ✅ A discount on your enrollment 🎁 6 bonus gifts, including job listings, interview prep, AI tools + more
If your goal is to land a data job in 2026, this is your chance to get ahead of the competition and start strong.
👉 Join the December Cohort & Claim Your Bonuses: https://DataCareerJumpstart.com/daa https://www.datacareerjumpstart.com/daa
Summary In this episode of the Data Engineering Podcast Serge Gershkovich, head of product at SQL DBM, talks about the socio-technical aspects of data modeling. Serge shares his background in data modeling and highlights its importance as a collaborative process between business stakeholders and data teams. He debunks common misconceptions that data modeling is optional or secondary, emphasizing its crucial role in ensuring alignment between business requirements and data structures. The conversation covers challenges in complex environments, the impact of technical decisions on data strategy, and the evolving role of AI in data management. Serge stresses the need for business stakeholders' involvement in data initiatives and a systematic approach to data modeling, warning against relying solely on technical expertise without considering business alignment.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Enterprises today face an enormous challenge: they’re investing billions into Snowflake and Databricks, but without strong foundations, those investments risk becoming fragmented, expensive, and hard to govern. And that’s especially evident in large, complex enterprise data environments. That’s why companies like DirecTV and Pfizer rely on SqlDBM. Data modeling may be one of the most traditional practices in IT, but it remains the backbone of enterprise data strategy. In today’s cloud era, that backbone needs a modern approach built natively for the cloud, with direct connections to the very platforms driving your business forward. Without strong modeling, data management becomes chaotic, analytics lose trust, and AI initiatives fail to scale. SqlDBM ensures enterprises don’t just move to the cloud—they maximize their ROI by creating governed, scalable, and business-aligned data environments. If global enterprises are using SqlDBM to tackle the biggest challenges in data management, analytics, and AI, isn’t it worth exploring what it can do for yours? Visit dataengineeringpodcast.com/sqldbm to learn more.Your host is Tobias Macey and today I'm interviewing Serge Gershkovich about how and why data modeling is a sociotechnical endeavorInterview IntroductionHow did you get involved in the area of data management?Can you start by describing the activities that you think of when someone says the term "data modeling"?What are the main groupings of incomplete or inaccurate definitions that you typically encounter in conversation on the topic?How do those conceptions of the problem lead to challenges and bottlenecks in execution?Data modeling is often associated with data warehouse design, but it also extends to source systems and unstructured/semi-structured assets. How does the inclusion of other data localities help in the overall success of a data/domain modeling effort?Another aspect of data modeling that often consumes a substantial amount of debate is which pattern to adhere to (star/snowflake, data vault, one big table, anchor modeling, etc.). What are some of the ways that you have found effective to remove that as a stumbling block when first developing an organizational domain representation?While the overall purpose of data modeling is to provide a digital representation of the business processes, there are inevitable technical decisions to be made. What are the most significant ways that the underlying technical systems can help or hinder the goals of building a digital twin of the business?What impact (positive and negative) are you seeing from the introduction of LLMs into the workflow of data modeling?How does tool use (e.g. MCP connection to warehouse/lakehouse) help when developing the transformation logic for achieving a given domain representation? What are the most interesting, innovative, or unexpected ways that you have seen organizations address the data modeling lifecycle?What are the most interesting, unexpected, or challenging lessons that you have learned while working with organizations implementing a data modeling effort?What are the overall trends in the ecosystem that you are monitoring related to data modeling practices?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links sqlDBMSAPJoe ReisERD == Entity Relation DiagramMaster Data ManagementdbtData ContractsData Modeling With Snowflake book by Serge (affiliate link)Type 2 DimensionData VaultStar SchemaAnchor ModelingRalph KimballBill InmonSixth Normal FormMCP == Model Context ProtocolThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA

Most Python developers reach for Pandas or Polars when working with tabular data—but DuckDB offers a powerful alternative that’s more than just another DataFrame library. In this tutorial, you’ll learn how to use DuckDB as an in-process analytical database: building data pipelines, caching datasets, and running complex queries with SQL—all without leaving Python. We’ll cover common use cases like ETL, lightweight data orchestration, and interactive analytics workflows. You’ll leave with a solid mental model for using DuckDB effectively as the “SQLite for analytics.”
Oracle brings the power of AI to the database with Oracle Database 23ai. By now, you've probably heard about Oracle Database 23ai AI Vector Search, which essentially transforms the Oracle Database into a powerful, best-in-class Vector Database. But there are many more new innovations introduced to support all manner of AI workloads, and best of all, Oracle makes it easy to start using these tools without having to learn any new programming languages or frameworks. All of these AI innovations can be used today without any additional installation necessary, and can be accessed using your favorite code editor or IDE. Perhaps there's a problem you are trying to solve with AI today and don't know where to start? This is the session to get you there. In this session, you will learn how to: - Load embedding models into the Oracle database - Run AI Vector Search in your database using regular SQL - Build Agentic RAG operations with Oracle 23ai - Accelerate your AI similarity search operations with HNSW and IVF_Flat indexes - Communicate with your database using natural language prompts with MCP - Use AI to generate synthetic table data - Use AI for document summarization inside the Oracle database.

Uncover the power of Graph Query Language (GQL) with 'Getting Started with the Graph Query Language'. This book is your comprehensive guide to mastering GQL, the cornerstone of managing and analyzing complex graph data. Dive into foundational concepts, explore advanced capabilities, and apply them using real-world examples. What this Book will help me do Understand and use GQL syntax effectively, including commands like MATCH, RETURN, INSERT, and DELETE. Master operations with graph patterns, variables, and functions to manipulate and query graph data. Apply advanced GQL techniques such as path matching modes, shortest paths, and transaction commands. Optimize graph database performance using indexing or caching strategies. Utilize GQL on a practical application, such as analyzing money transaction data for behavior and risk insights. Author(s) Ricky Sun, Jason Zhang, and Yuri Simione are seasoned experts in graph database technologies and standards. With years of professional experience and a collaborative spirit, they bring clarity and practice-oriented guidance to understanding GQL. Their passion for teaching and simplifying complex ideas shines through this well-crafted book. Who is it for? This book is ideal for graph database developers, database administrators, and data engineers looking to grasp GQL's fundamentals and advanced features. Beginners familiar with databases and programming fundamentals can follow along seamlessly. It also appeals to analysts and programmers seeking to enhance their graph data handling skills. Prior knowledge of graph theory concepts like nodes and edges is helpful but not mandatory, ensuring accessibility for learners of diverse levels.
Feeling behind on your data journey? Don't worry. Today, I'll list down the 13 signs that prove you're actually ahead (even if you're actually doing just some of these). ✨ Try Julius today at https://landadatajob.com/Julius-YT 💌 Join 10k+ aspiring data analysts & get my tips in your inbox weekly 👉 https://www.datacareerjumpstart.com/newsletter 🆘 Feeling stuck in your data journey? Come to my next free "How to Land Your First Data Job" training 👉 https://www.datacareerjumpstart.com/training 👩💻 Want to land a data job in less than 90 days? 👉 https://www.datacareerjumpstart.com/daa 👔 Ace The Interview with Confidence 👉 https://www.datacareerjumpstart.com/interviewsimulator ⌚ TIMESTAMPS 00:00 Introduction 00:05 #1 You can analyze data in Excel without panicking 00:52 #2 You know how to write basic SQL queries 01:17 #3 You can build a bar chart and scatter plot in Tableau or Power BI 01:59 #4 You can Google (or ChatGPT) your way through any error 02:45 #5 You can send me one portfolio project right now 03:45 #6 You talk about your data journey with friends and family regularly 05:50 #7 You’re actually applying to jobs (not just watching tutorials) 07:03 #8 You’ve joined a data community 07:48 #9 Your resume now includes (lots of) the right keywords 10:11 #10 You’ve optimized your LinkedIn for data roles 10:45 #11 A recruiter reaches out to you on LinkedIn 11:58 #12 You’ve had at least one real interview 12:52 #13 You’re comfortable not knowing everything (yet) 🔗 CONNECT WITH AVERY 🎥 YouTube Channel: https://www.youtube.com/@averysmith 🤝 LinkedIn: https://www.linkedin.com/in/averyjsmith/ 📸 Instagram: https://instagram.com/datacareerjumpstart 🎵 TikTok: https://www.tiktok.com/@verydata 💻 Website: https://www.datacareerjumpstart.com/ Mentioned in this episode: Join the last cohort of 2025! The LAST cohort of The Data Analytics Accelerator for 2025 kicks off on Monday, December 8th and enrollment is officially open!
To celebrate the end of the year, we’re running a special End-of-Year Sale, where you’ll get: ✅ A discount on your enrollment 🎁 6 bonus gifts, including job listings, interview prep, AI tools + more
If your goal is to land a data job in 2026, this is your chance to get ahead of the competition and start strong.
👉 Join the December Cohort & Claim Your Bonuses: https://DataCareerJumpstart.com/daa https://www.datacareerjumpstart.com/daa
Summary In this episode of the Data Engineering Podcast Lucas Thelosen and Drew Gilson from Gravity talk about their development of Orion, an autonomous data analyst that bridges the gap between data availability and business decision-making. Lucas and Drew share their backgrounds in data analytics and how their experiences have shaped their approach to leveraging AI for data analysis, emphasizing the potential of AI to democratize data insights and make sophisticated analysis accessible to companies of all sizes. They discuss the technical aspects of Orion, a multi-agent system designed to automate data analysis and provide actionable insights, highlighting the importance of integrating AI into existing workflows with accuracy and trustworthiness in mind. The conversation also explores how AI can free data analysts from routine tasks, enabling them to focus on strategic decision-making and stakeholder management, as they discuss the future of AI in data analytics and its transformative impact on businesses.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Your host is Tobias Macey and today I'm interviewing Lucas Thelosen and Drew Gilson about the engineering and impact of building an autonomous data analystInterview IntroductionHow did you get involved in the area of data management?Can you describe what Orion is and the story behind it?How do you envision the role of an agentic analyst in an organizational context?There have been several attempts at building LLM-powered data analysis, many of which are essentially a text-to-SQL interface. How have the capabilities and architectural patterns grown in the past ~2 years to enable a more capable system?One of the key success factors for a data analyst is their ability to translate business questions into technical representations. How can an autonomous AI-powered system understand the complex nuance of the business to build effective analyses?Many agentic approaches to analytics require a substantial investment in data architecture, documentation, and semantic models to be effective. What are the gradations of effectiveness for autonomous analytics for companies who are at different points on their journey to technical maturity?Beyond raw capability, there is also a significant need to invest in user experience design for an agentic analyst to be useful. What are the key interaction patterns that you have found to be helpful as you have developed your system?How does the introduction of a system like Orion shift the workload for data teams?Can you describe the overall system design and technical architecture of Orion?How has that changed as you gained further experience and understanding of the problem space?What are the most interesting, innovative, or unexpected ways that you have seen Orion used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on Orion?When is Orion/agentic analytics the wrong choice?What do you have planned for the future of Orion?Contact Info LucasLinkedInDrewLinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links OrionLookerGravityVBA == Visual Basic for ApplicationsText-To-SQLOne-shotLookMLData GrainLLM As A JudgeGoogle Large Time Series ModelThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
What if you could ensure the accuracy and integrity of your data effortlessly? Join this session on Data Constraints in databases, where we'll uncover the fundamental rules that keep your data reliable and consistent. Starting with the basics, we'll explore what data constraints are and why they are essential for maintaining the quality of your database. We'll dive into different types of data constraints, including primary keys, foreign keys, unique constraints, and check constraints, explaining how each one helps in enforcing data rules and relationships within your database. You'll learn the correct syntax for defining these constraints and see practical examples of how they can prevent errors and ensure data integrity. Through real-world scenarios, we'll illustrate how data constraints can be used to enforce business rules and improve the overall robustness of your database applications. We'll also discuss the performance implications of using constraints and best practices for their implementation to optimize both efficiency and accuracy. Finally, we'll cover common challenges and pitfalls associated with data constraints, providing tips on how to avoid them and ensure your database remains a reliable asset for your organization. Whether you're a novice or looking to deepen your understanding, this session will equip you with the knowledge to leverage data constraints effectively and enhance the reliability of your database systems.
Talk by Reut Nissan Rosen from Lightricks.
Let's learn how to create and update database schemas using just prompts with GitHub Copilot in VS Code. You will see an example of using GibsonAI MCP together with GitHub MCP Servers to create GitHub pull requests with auto-generated model classes in any programming language.