Apache Airflow is Scalable, Dynamic, Extensible , Elegant and can it be a lot more ? We have taken Airflow to the next level, using it as hybrid cloud data service accelerating our transformation. During this talk we will present the implementation of Airflow as an orchestration solution between LEGACY, PRIVATE and PUBLIC cloud (AWS / AZURE) : Comparison between public/private offers. Harness the power of Hybric cloud orchestrator to meet the regulatory requirements (European Financial Institutions) Real production use cases
 talk-data.com
talk-data.com
Topic
AWS
Amazon Web Services (AWS)
cloud
cloud provider
infrastructure
services
837
tagged
Activity Trend
190
peak/qtr
2020-Q1
2026-Q2
Top Events
AWS re:Invent 2024
341
Data Engineering Podcast
56
O'Reilly Data Engineering Books
54
SaaS Scaled - Interviews about SaaS Startups, Analytics, & Operations
35
Databricks DATA + AI Summit 2023
32
Data + AI Summit 2025
31
O'Reilly Data Science Books
15
Airflow Summit 2025
11
Airflow Summit 2023
7
DataFramed
7
Airflow Summit 2024
6
DATA MINER Big Data Europe Conference 2020
6
We will share the case study of Airflow at StyleSeat, where within a year our data grew from 2 million data points per day to 200 million. Our original solution for orchestrating this data was not enough, so we migrated to an Airflow based solution. Previous implementation Our tasks were orchestrated with hourly triggers on AWS Cloudwatch rules in their own log groups. Each task was a lambda individually defined as a task and executed python code from a docker image. As complexity increased, there were frequent downtimes and manual executions for failed tasks and their downstream dependencies.With every downtime, our business stakeholders started losing trust in Data and recovery times were longer with each downtime. We needed a modern orchestration platform which would enable our team to define and instrument complex pipelines as code, provide visibility into executions and define retry criteria on failures. Airflow was identified as a crucial & critical piece in modernizing our orchestration which would help us further onboard DBT. We wanted a managed solution and a partner who could help guide us to a successful migration.
Executors are a core concept in Apache Airflow and are an essential piece to the execution of DAGs. They have seen a lot of investment over the year and there are many exciting advancements that will benefit both users and contributors. This talk will briefly discuss executors, how they work and what they are responsible for. It will then describe Executor Decoupling (AIP-51) and how this has fully unlocked development of third-party executors. We’ll touch on the migration of “core” executors (such as Celery and Kubernetes) to their own package as well as the addition of new “3rd party” executors from providers such as AWS. Finally, a description/demo of Hybrid Executors, a proposed new feature to allow multiple executors to be used natively and seamlessly side by side within a single Airflow environment; which will be a powerful feature in a future full of many new Airflow executors.
Amazon Managed Workflows for Apache Airflow (MWAA) was released in November 2020. Throughout MWAA’s design we held the tenets that this service would be open-source first, not forking or deviating from the project, and that the MWAA team would focus on improving Airflow for everyone—whether they run Airflow on MWAA, on AWS, or anywhere else. This talk will cover some of the design choices made to facilitate those tenets, how the organization was set up to contribute back to the community, what those contributions look like today, how we’re getting those contributions in the hands of users, and our vision for future engagement with the community.
Deep dive into how AWS is developing Deferrable Operators for the Amazon Provider Package to help users realize the potential cost-savings provided by Deferrable Operators, and promote their usage.
by
Vincent Beck
System tests are executable DAGs for example and testing purposes. With a simple pytest command, you can run an entire DAG. From a provider point of view, they can be viewed as integration tests for all provider related operators and sensors. Running these system tests frequently and monitoring the results allow us to enforce stability amongst many other benefits. In this presentation we will explore how AWS built their system test environment, from the GitHub fork to the health dashboard that exists today…but more importantly, why you should do it as well!
High-scale orchestration of genomic algorithms using Airflow workflows, AWS Elastic Container Service (ECS), and Docker. Genomic algorithms are highly demanding of CPU, RAM, and storage. Our data science team requires a platform to facilitate the development and validation of proprietary algorithms. The Data engineering team develops a research data platform that enables Data Scientists to publish docker images to AWS ECR and run them using Airflow DAGS that provision AWS’s ECS compute power of EC2 and Fargate. We will describe a research platform that allows our data science team to check their algorithms on ~1000 cases in parallel using airflow UI and dynamic DAG generation to utilize EC2 machines, auto-scaling groups, and ECS clusters across multiple AWS regions.

In "Geospatial Data Analytics on AWS," you will learn how to store, manage, and analyze geospatial data effectively using various AWS services. This book provides insight into building geospatial data lakes, leveraging AWS databases, and applying best practices to derive insights from spatial data in the cloud. What this Book will help me do Design and manage geospatial data lakes on AWS leveraging S3 and other storage solutions. Analyze geospatial data using AWS services such as Athena and Redshift. Utilize machine learning models for geospatial data processing and analytics using SageMaker. Visualize geospatial data through services like Amazon QuickSight and OpenStreetMap integration. Avoid common pitfalls when managing geospatial data in the cloud. Author(s) Scott Bateman, Janahan Gnanachandran, and Jeff DeMuth bring their extensive experience in cloud computing and geospatial analytics to this book. With backgrounds in cloud architecture, data science, and geospatial applications, they aim to make complex topics accessible. Their collaborative approach ensures readers can practically apply concepts to real-world challenges. Who is it for? This book is ideal for GIS and data professionals, including developers, analysts, and scientists. It suits readers with a basic understanding of geographical concepts but no prior AWS experience. If you're aiming to enhance your cloud-based geospatial data management and analytics skills, this is the guide for you.

by
Raquel Carvalho
(NIQ)
,
Clifford McDowel
(Doorda)
,
Phil Cooper
(Amazon Web Services)
,
Justin Meynell
(Experian)
Raquel Carvalho,Director, Partner Development at NIQ; Clifford McDowel,Founder & CEO at Doorda; Phil Cooper, Global Geospatial Lead at Amazon Web Services; and Justin Meynell, Client Director at Experian, discuss some of the new types of data that Spatial Data Scientists are turning to create innovative spatial models for their companies and examine how recent advances in technology and ai are changing the way we access data.
When I joined Grammarly, it could fit in a small apartment. My first task was to fix a scalability problem: the service crashed with . . . 300 online users. Ten years later, millions of users relied on Grammarly apps everywhere—in browsers, on Windows, Mac, mobile, at home, in the enterprise, and through partnerships. Our product footprint grew, and so did our team. Along the way, we realized that scaling a software company is harder than scaling servers on AWS. As we kept hiring engineers and other essential experts, we began asking ourselves: Are we really moving faster with this big team? Are we productive? Can we even measure our developers' productivity? In this meetup I’ll tell you about engineering processes, software tools, and even the computer science principles we tried on our quest to scale engineering productivity and ease the growing pains. Join our conversation and have fun guessing: What worked and what didn't?
by
Tobias Macey
Summary
All of the advancements in our technology is based around the principles of abstraction. These are valuable until they break down, which is an inevitable occurrence. In this episode the host Tobias Macey shares his reflections on recent experiences where the abstractions leaked and some observances on how to deal with that situation in a data platform architecture.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudderstack Your host is Tobias Macey and today I'm sharing some thoughts and observances about abstractions and impedance mismatches from my experience building a data lakehouse with an ELT workflow
Interview
Introduction impact of community tech debt
hive metastore new work being done but not widely adopted
tensions between automation and correctness data type mapping
integer types complex types naming things (keys/column names from APIs to databases)
disaggregated databases - pros and cons
flexibility and cost control not as much tooling invested vs. Snowflake/BigQuery/Redshift
data modeling
dimensional modeling vs. answering today's questions
What are the most interesting, unexpected, or challenging lessons that you have learned while working on your data platform? When is ELT the wrong choice? What do you have planned for the future of your data platform?
Contact Info
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
dbt Airbyte
Podcast Episode
Dagster
Podcast Episode
Trino
Podcast Episode
ELT Data Lakehouse Snowflake BigQuery Redshift Technical Debt Hive Metastore AWS Glue
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Rudderstack: 
RudderStack provides all your customer data pipelines in one platform. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
RudderStack’s warehouse-first approach means it does not store sensitive information, and it allows you to leverage your existing data warehouse/data lake infrastructure to build a single source of truth for every team.
RudderStack also supports real-time use cases. You can Implement RudderStack SDKs once, then automatically send events to your warehouse and 150+ business tools, and you’ll never have to worry about API changes again.
Visit dataengineeringpodcast.com/rudderstack to sign up for free today, and snag a free T-Shirt just for being a Data Engineering Podcast listener.Support Data Engineering Podcast

ABOUT THE TALK: Wesley Faulkner explores the various types of communities and discusses how to determine the most suitable one for your company at various stages of growth. Whether you are looking to double down on your current community or expand to new platforms, Wesley provides the guidance you'll need to make informed decisions about building a strong and effective community.
ABOUT THE SPEAKER: Wesley Faulkner is a first-generation American, public speaker, and podcaster. He is a founding member of the government transparency group Open Austin and a staunch supporter of racial justice, workplace equity, and neurodiversity. His professional experience spans technology from AMD, Atlassian, Dell, IBM, and MongoDB.
ABOUT DATA COUNCIL: Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL: Twitter: https://twitter.com/DataCouncilAI LinkedIn: https://www.linkedin.com/company/datacouncil-ai/

ABOUT THE TALK: The power to gather, analyze, and quickly act on real-time bidding data is critical for advertisers and publishers. A data platform that supports real-time bidding empowers these participants to obtain insights from the huge amounts of data generated by programmatic advertising.
Learn how our Beeswax data platform captures real-time information about bids and impressions and provides feedback to advertisers, enabling them to make data-driven decisions for optimal results. It is built on an event-based architecture, leveraging AWS Kinesis and Snowflake's Snowpipe, that is capable of processing bid requests at a massive scale - around half a million QPS in real-time! We also talk about how the platform evolved over time and how we've built the platform and monitoring infrastructure to enable sustained growth.
ABOUT THE SPEAKER: Margi Dubal is a Director of Data Engineering at Freewheel, a Comcast Company. She currently leads various data teams to build scalable, reliable, and high-quality data solutions. Prior to joining Freewheel, Margi has held data engineering management positions at Paperless Post, Amplify and Adknowledge Inc.
ABOUT DATA COUNCIL: Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL: Twitter: https://twitter.com/DataCouncilAI LinkedIn: https://www.linkedin.com/company/datacouncil-ai/
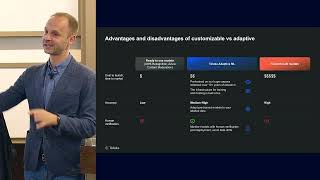
ABOUT THE TALK: In this talk, Fedor Zhdanov explains how to combat the concept of drift in ML with crowdsourcing. He shows you how to build complex drift-monitoring systems and human-in-the-loop ML models that can be fully automated. He also shares how this has led him and his team to start building so-called “adaptive ML models”. Learn what they are and how to build and maintain them.
ABOUT THE SPEAKER: Fedor Zhdanov is the Head of AI at Toloka, who had previous roles as Principal Applied Scientist at AWS, Microsoft and Amazon. Fedor has been creating products with R&D in Machine Learning for the last 18+ years. For the last 6 years, he has been focusing on connecting ML and humans in human-in-the-loop processes. His ventures are focused on building responsible state of the art AI-first business solutions with human oversight.
ABOUT DATA COUNCIL: Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL: Twitter: https://twitter.com/DataCouncilAI LinkedIn: https://www.linkedin.com/company/datacouncil-ai/
On today’s episode, we’re joined by Scott Hurff, Founder & Chief Product Officer at Churnkey, a platform built to supercharge every part of customer retention and optimize your company’s growth.
We talk about:
- Scott’s background and the story of Churnkey.
- What a good SaaS product needs.
- Ensuring company alignment when it comes to design.
- Balancing flexibility, power and ease of use.
- How pricing impacts customer retention.
- How to raise SaaS prices without losing customers.
Scott Hurff - https://www.linkedin.com/in/scotthurff/ Churnkey - https://www.linkedin.com/company/churnkey/
This episode is brought to you by Qrvey
The tools you need to take action with your data, on a platform built for maximum scalability, security and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com.
Qrvey, the modern no-code analytics solution for SaaS companies on AWS.
On today’s episode, we’re joined by Atif Ghauri, Senior Vice President at Cyderes, a global cybersecurity powerhouse offering comprehensive solutions around managed security, identity and access management, and professional services.
We talk about:
- How Cyderes works and the problems they solve.
- The evolution of cloud security.
- The impact of AI on cybersecurity.
- The biggest risk factors in cloud security today.
- How new SaaS founders today should think about cybersecurity and common mistakes to avoid.
- The turning point where SaaS companies have to start taking security more seriously.
- Some of the things Atif has found surprising in his security career.
Atif Ghauri - https://www.linkedin.com/in/aghauri Cyderes - https://www.linkedin.com/company/the-herjavec-group/
This episode is brought to you by Qrvey
The tools you need to take action with your data, on a platform built for maximum scalability, security and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com.
Qrvey, the modern no-code analytics solution for SaaS companies on AWS.
saas #analytics #AWS #BI
In today’s episode, we’re joined by Reha Jhunjhunwala, Product Manager of AI ML Initiatives at eClinical Solutions, a company that helps life sciences organizations around the world accelerate clinical development initiatives with expert data services.
We talk about:
- Reha’s background as a dentist and how she got into tech.
- How machine learning and AI impact the software development process.
- How AI will affect the traditional strengths of software in general.
- What the considerations are around AI in healthcare where regulations are strict.
- Some of the things slowing AI down.
Reha Jhunjhunwala - https://www.linkedin.com/in/rehajhunjhunwala/ eClinical Solutions - https://www.linkedin.com/company/eclinical-solutions/
This episode is brought to you by Qrvey
The tools you need to take action with your data, on a platform built for maximum scalability, security, and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com.
Qrvey, the modern no-code analytics solution for SaaS companies on AWS.
saas #analytics #AWS #BI
On today’s episode, we’re joined by Vlad Eidelman. Vlad is CTO and Chief Scientist at FiscalNote — a leading technology provider of global policy and market intelligence uniquely combining AI technology, actionable data, and expert and peer insights to give customers mission-critical insights.
We talk about:
- Vlad’s story and what FiscalNote does.
- How AI changes software.
- The importance of adding extra value to software.
- What to do with user data?
- How Vlad makes internal decisions at FiscalNote.
- The impact of remote work.
- The importance of building the right data analytics stack to acquire data.
Vlad Eidelman - https://www.linkedin.com/in/veidelman/ FiscalNote - https://www.linkedin.com/company/fiscalnote/
This episode is brought to you by Qrvey
The tools you need to take action with your data, on a platform built for maximum scalability, security, and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com.
Qrvey, the modern no-code analytics solution for SaaS companies on AWS.
saas #analytics #AWS #BI
In today’s episode, we’re joined by Gleb Polyakov. Gleb is the CEO and Co-Founder of Nylas, a platform that allows developers to automate manual, repetitive everyday tasks with little to no code.
We talk about:
- How Nylas works, the benefits it provides and who it targets.
- The definition of first-party data and why it’s important.
- The growth of the API economy.
- The new roles of sales and marketing when selling to developers.
- The trend of using education as a sales technique.
Gleb Polyakov - https://www.linkedin.com/in/gpolyakov Nylas - https://www.linkedin.com/company/nylas/
This episode is brought to you by Qrvey
The tools you need to take action with your data, on a platform built for maximum scalability, security and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com.
Qrvey, the modern no-code analytics solution for SaaS companies on AWS.
saas #analytics #AWS #BI
On today’s episode, we’re joined by Ellie Fields. Ellie is the Chief Product and Engineering Officer at Salesloft, which helps sales teams drive more revenue with the only complete sales engagement platform available in the market. We talk about:
- Ellie’s background and what Salesloft does.
- The changing trends in how companies use data.
- Drawing valuable insights from unstructured data.
- Putting workflow at the center of what you do, and the challenges involved.
- Ellie’s experiences managing both product and engineering.
- Are more autonomous teams more scalable?
- Applying a metric- and data-oriented culture internally.
- The impact of remote work on how companies operate.
Ellie Fields - https://www.linkedin.com/in/elliefields/ Salesloft - https://www.linkedin.com/company/salesloft/
This episode is brought to you by Qrvey
The tools you need to take action with your data, on a platform built for maximum scalability, security, and cost efficiencies. If you’re ready to reduce complexity and dramatically lower costs, contact us today at qrvey.com.
Qrvey, the modern no-code analytics solution for SaaS companies on AWS.