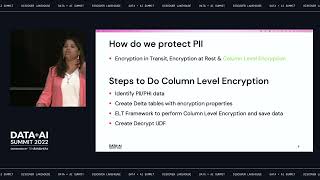
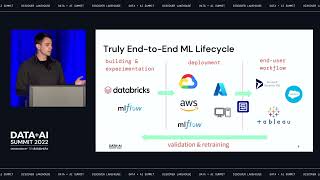
As AI continues to shape human-computer interaction, there’s a growing opportunity and responsibility to ensure these technologies serve everyone, including people with communication disabilities. In this talk, I will present my ongoing work in developing a real-time American Sign Language (ASL) recognition system, and explore how integrating accessible design principles into AI research can expand both usability and impact.
The core of the talk will cover the Sign Language Recogniser project (available on GitHub), in which I used MediaPipe Studio together with TensorFlow, Keras, and OpenCV to train a model that classifies ASL letters from hand-tracking features.
I’ll share the methodology: data collection, feature extraction via MediaPipe, model training, and demo/testing results. I’ll also discuss challenges encountered, such as dealing with gesture variability, lighting and camera differences, latency constraints, and model generalization.
Beyond the technical implementation, I’ll reflect on the broader implications: how accessibility-focused AI projects can promote inclusion, how design decisions affect trust and usability, and how women in AI & data science can lead innovation that is both rigorous and socially meaningful. Attendees will leave with actionable insights for building inclusive AI systems, especially in domains involving rich human modalities such as gesture or sign.