Send us a text Welcome to the cozy corner of the tech world where ones and zeros mingle with casual chit-chat. Datatopics Unplugged is your go-to spot for relaxed discussions around tech, news, data, and society. We dive into conversations smoother than your morning coffee (but let’s be honest, just as caffeinated) where industry insights meet light-hearted banter. Whether you’re a data wizard or just curious about the digital chaos around us, kick back and get ready to talk shop—unplugged style! In this episode: Farewell Pandas, Hello Future: Pandas is out, and Ibis is in. We're talking faster, smarter data processing—featuring the rise of DuckDB and the powerhouse that is Polars. Is this the end of an era for Pandas?UV vs. Rye: Forget pip—are these new Python package managers built in Rust the future? We break down UV, Rye, and what it all means for your next Python project.AI-Generated Podcasts: Is AI about to take over your favorite podcasts? We explore the potential of Google’s Notebook LM to transform content into audio gold.When AI Steals Your Voice: Jeff Geerling’s voice gets cloned by AI—without his consent. We dive into the wild world of voice cloning, the ethics, and the future of AI-generated media.Hacking AI with Prompt Injection: Could you outsmart AI? We share some wild strategies from the game Gandalf that challenge your prompt injection skills and teach you how to jailbreak even the toughest guardrails.Jony Ive’s New Gadget Rumor: Is Jony Ive plotting an Apple killer? Rumors are swirling about a new AI-powered handheld device that could shake up the smartphone market.Zero-Downtime Deployments with Kamal Proxy: No more downtime! We geek out over Kamal Proxy, the sleek HTTP tool designed for effortless Docker deployments.Function Calling and LLMs: Get ready for the next evolution in AI—function calling. We discuss its rise in LLMs and dive into the Gorilla project, the leaderboard testing the future of smart APIs.
 talk-data.com
talk-data.com
Topic
Docker
109
tagged
Activity Trend
Top Events
In this talk, we'll look into why Insee had to go beyond usual tools like JupyterHub. With data science growing, it has become important to have tools that are easy to use, can change as needed, and help people work together. The opensource software Onyxia brings a new answer by offering a user-friendly way to boost creativity in a data environment that uses massively containerization and object storage.
Migrations are often motivated by reliability, but can also harm reliability if not done with care. Tom will explore several migrations he led over the past few years, including moving 2000+ jobs to Nomad, subsequently containerizing 2600 and moving to an HA setup with RabbitMQ. We will discuss what went well and what went wrong in each instance, and how we applied what we learned to improve our migration competency.

Big Data on Kubernetes is your comprehensive guide to leveraging Kubernetes for scalable and efficient big data solutions. You will learn key concepts of Kubernetes architecture and explore tools like Apache Spark, Airflow, and Kafka. Gain hands-on experience building complete data pipelines to tackle real-world data challenges. What this Book will help me do Understand Kubernetes architecture and learn to deploy and manage clusters. Build and orchestrate big data pipelines using Spark, Airflow, and Kafka. Develop scalable and resilient data solutions with Docker and Kubernetes. Integrate and optimize data tools for real-time ingestion and processing. Apply concepts to hands-on projects addressing actual big data scenarios. Author(s) Neylson Crepalde is an experienced data specialist with extensive knowledge of Kubernetes and big data solutions. With deep practical experience, Neylson brings real-world insights to his writing. His approach emphasizes actionable guidance and relatable problem-solving with a strong foundation in scalable architecture. Who is it for? This book is ideal for data engineers, BI analysts, data team leaders, and tech managers familiar with Python, SQL, and YAML. Targeted at professionals seeking to develop or expand their expertise in scalable big data solutions, it provides practical insights into Docker, Kubernetes, and prominent big data tools.
Apache Airflow is the backbone of countless data pipelines, but optimizing performance and resource utilization can be a challenge. This talk introduces a novel performance testing framework designed to measure, monitor, and improve the efficiency of Airflow deployments. I’ll delve into the framework’s modular architecture, showcasing how it can be tailored to various Airflow setups (Docker, Kubernetes, cloud providers). By measuring key metrics across schedulers, workers, triggers, and databases, this framework provides actionable insights to identify bottlenecks and compare performance across different versions or configurations. Attendees will learn: The motivation behind developing a standardized performance testing approach. Key design considerations and challenges in measuring performance across diverse Airflow environments. How to leverage the framework to construct test suites for different use cases (e.g., version comparison). Practical tips for interpreting performance test results and making informed decisions about resource allocation. How this framework contributes to greater transparency in Airflow release notes, empowering users with performance data.
DAG Authors, while constructing DAGs, generally use native libraries provided by Airflow in conjunction with python libraries available over public PyPI repositories. But sometimes, DAG authors need to construct DAG using libraries that are either in-house or not available over public PyPI repositories. This poses a serious challenge for users who want to run their custom code with Airflow DAGs, particularly when Airflow is deployed in a cloud-native fashion. Traditionally, these packages are baked in Airflow Docker images. This won’t work post deployment and is super impractical if your library is under development. We propose a solution that creates a dedicated Airflow global python environment that dynamically generates the requirements, establishes a version-compatible pyenv adhering to Airflow’s policies, and manages custom pip repository authentication seamlessly. Importantly, the service executes these steps in a fail-safe manner, not compromising core components. Join us as we discuss the solution to this common problem, touching upon the design, and seeing the solution in action. We also candidly discuss some challenges, and the shortcomings of the proposed solution.
Build an NGINX Dockerfile using Pulumi and Docker Build Cloud.
Learn how to create and configure a Docker Build Cloud (DBC) builder and use Pulumi's Docker Build provider to automate Docker builds.

Build faster, more reliable Rails apps by taking the best advanced PostgreSQL and Active Record capabilities, and using them to solve your application scale and growth challenges. Gain the skills needed to comfortably work with multi-terabyte databases, and with complex Active Record, SQL, and specialized Indexes. Develop your skills with PostgreSQL on your laptop, then take them into production, while keeping everything in sync. Make slow queries fast, perform any schema or data migration without errors, use scaling techniques like read/write splitting, partitioning, and sharding, to meet demanding workload requirements from Internet scale consumer apps to enterprise SaaS. Deepen your firsthand knowledge of high-scale PostgreSQL databases and Ruby on Rails applications with dozens of practical and hands-on exercises. Unlock the mysteries surrounding complex Active Record. Make any schema or data migration change confidently, without downtime. Grow your experience with modern and exclusive PostgreSQL features like SQL Merge, Returning, and Exclusion constraints. Put advanced capabilities like Full Text Search and Publish Subscribe mechanisms built into PostgreSQL to work in your Rails apps. Improve the quality of the data in your database, using the advanced and extensible system of types and constraints to reduce and eliminate application bugs. Tackle complex topics like how to improve query performance using specialized indexes. Discover how to effectively use built-in database functions and write your own, administer replication, and make the most of partitioning and foreign data wrappers. Use more than 40 well-supported open source tools to extend and enhance PostgreSQL and Ruby on Rails. Gain invaluable insights into database administration by conducting advanced optimizations - including high-impact database maintenance - all while solving real-world operational challenges. Take your new skills into production today and then take your PostgreSQL and Rails applications to a whole new level of reliability and performance. What You Need: A computer running macOS, Linux, or Windows and WSL2 PostgreSQL version 16, installed by package manager, compiled, or running with Docker An Internet connection
Join iConstruye, a SaaS supply management company, as they detail their multi-phase digital transformation. They successfully migrated 135 VMs to a multi-zone Google Cloud deployment, slashing IT costs by 32%, followed by containerization on Google Kubernetes Engine, where they achieved a 25% reduction in time-to-market.
You'll gain actionable insights into their modernization strategy, including the emphasis on investing in training for their IT team on new cloud tools, reducing technical debt, and setting the stage for continued growth.
Click the blue “Learn more” button above to tap into special offers designed to help you implement what you are learning at Google Cloud Next 25.

Whether you’ve been in the developer kitchen for decades or are just taking the plunge to do it yourself, The Complete Developer will show you how to build and implement every component of a modern stack—from scratch. You’ll go from a React-driven frontend to a fully fleshed-out backend with Mongoose, MongoDB, and a complete set of REST and GraphQL APIs, and back again through the whole Next.js stack. The book’s easy-to-follow, step-by-step recipes will teach you how to build a web server with Express.js, create custom API routes, deploy applications via self-contained microservices, and add a reactive, component-based UI. You’ll leverage command line tools and full-stack frameworks to build an application whose no-effort user management rides on GitHub logins. You’ll also learn how to: Work with modern JavaScript syntax, TypeScript, and the Next.js framework Simplify UI development with the React library Extend your application with REST and GraphQL APIs Manage your data with the MongoDB NoSQL database Use OAuth to simplify user management, authentication, and authorization Automate testing with Jest, test-driven development, stubs, mocks, and fakes Whether you’re an experienced software engineer or new to DIY web development, The Complete Developer will teach you to succeed with the modern full stack. After all, control matters. Covers: Docker, Express.js, JavaScript, Jest, MongoDB, Mongoose, Next.js, Node.js, OAuth, React, REST and GraphQL APIs, and TypeScript
We will share the case study of Airflow at StyleSeat, where within a year our data grew from 2 million data points per day to 200 million. Our original solution for orchestrating this data was not enough, so we migrated to an Airflow based solution. Previous implementation Our tasks were orchestrated with hourly triggers on AWS Cloudwatch rules in their own log groups. Each task was a lambda individually defined as a task and executed python code from a docker image. As complexity increased, there were frequent downtimes and manual executions for failed tasks and their downstream dependencies.With every downtime, our business stakeholders started losing trust in Data and recovery times were longer with each downtime. We needed a modern orchestration platform which would enable our team to define and instrument complex pipelines as code, provide visibility into executions and define retry criteria on failures. Airflow was identified as a crucial & critical piece in modernizing our orchestration which would help us further onboard DBT. We wanted a managed solution and a partner who could help guide us to a successful migration.
New users starting with Airflow frequently encounter several challenges, ranging from the complexities of Containers and virtual environments to the Python dependency hell. Moreover, their familiarity with tools such as Docker, docker-compose, and Helm might be somewhat limited and even overkill. In contrast, seasoned Airflow users encounter their problems, encompassing configuration conflics with ongoing Airflow projects and intricacies stemming from Docker and docker-compose configurations and lack of visibility into all the projects. With airflowctl, users can install & setup Airflow using a single command. For existing users, they can use it to manage multiple Airflow projects with different Airflow versions on the same machine. This allows creating & debugging DAGs in an IDE seamlessly. Agenda for the call: Why airflowctl? Goal Current functionality & Demo Vision / Roadmap
High-scale orchestration of genomic algorithms using Airflow workflows, AWS Elastic Container Service (ECS), and Docker. Genomic algorithms are highly demanding of CPU, RAM, and storage. Our data science team requires a platform to facilitate the development and validation of proprietary algorithms. The Data engineering team develops a research data platform that enables Data Scientists to publish docker images to AWS ECR and run them using Airflow DAGS that provision AWS’s ECS compute power of EC2 and Fargate. We will describe a research platform that allows our data science team to check their algorithms on ~1000 cases in parallel using airflow UI and dynamic DAG generation to utilize EC2 machines, auto-scaling groups, and ECS clusters across multiple AWS regions.

ABOUT THE TALK: In this talk, Erik Bernhardsson will share how Modal starts 1000s of large containers in seconds, and what they had to do under the surface to build this. This includes a custom file system written in Rust, their own container runtime, and their own container image builder. This talk will give you an idea of how containers work along with some of the low-level Linux details underneath. We'll also talk about many infrastructure tools hold data teams back, and why they deserve faster and better tools.
ABOUT THE SPEAKER: Erik Bernhardsson is the founder and CEO of Modal, which is an infrastructure provider for data teams. Before Modal, Erik was the CTO at Better for six years, and previously spent seven years at Spotify, building the music recommendation system and running data teams.
ABOUT DATA COUNCIL: Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL: Twitter: https://twitter.com/DataCouncilAI LinkedIn: https://www.linkedin.com/company/datacouncil-ai/
Summary
Data is a team sport, but it's often difficult for everyone on the team to participate. For a long time the mantra of data tools has been "by developers, for developers", which automatically excludes a large portion of the business members who play a crucial role in the success of any data project. Quilt Data was created as an answer to make it easier for everyone to contribute to the data being used by an organization and collaborate on its application. In this episode Aneesh Karve shares the journey that Quilt has taken to provide an approachable interface for working with versioned data in S3 that empowers everyone to collaborate.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Truly leveraging and benefiting from streaming data is hard - the data stack is costly, difficult to use and still has limitations. Materialize breaks down those barriers with a true cloud-native streaming database - not simply a database that connects to streaming systems. With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. Go to dataengineeringpodcast.com/materialize today and sign up for early access to get started. If you like what you see and want to help make it better, they're hiring across all functions! Your host is Tobias Macey and today I'm interviewing Aneesh Karve about how Quilt Data helps you bring order to your chaotic data in S3 with transactional versioning and data discovery built in
Interview
Introduction How did you get involved in the area of data management? Can you describe what Quilt is and the story behind it?
How have the goals and features of the Quilt platform changed since I spoke with Kevin in June of 2018?
What are the main problems that users are trying to solve when they find Quilt?
What are some of the alternative approaches/products that they are coming from?
How does Quilt compare with options such as LakeFS, Unstruk, Pachyderm, etc.? Can you describe how Quilt is implemented? What are the types of tools and systems that Quilt gets integrated with?
How do you manage the tension between supporting the lowest common denominator, while providing options for more advanced capabilities?
What is a typical workflow for a team that is using Quilt to manage their data? What are the most interesting, innovative, or unexpected ways that you have seen Quilt used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Quilt? When is Quilt the wrong choice? What do you have planned for the future of Quilt?
Contact Info
LinkedIn @akarve on Twitter
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Quilt Data
Podcast Episode
UW Madison Docker Swarm Kaggle open.quiltdata.com FinOS Perspective LakeFS
Podcast Episode
Pachyderm
Podcast Episode
Unstruk
Podcast Episode
Parquet Avro ORC Cloudformation Troposphere CDK == Cloud Development Kit Shadow IT
Podcast Episode
Delta Lake
Podcast Episode
Apache Iceberg
Podcast Episode
Datasette Frictionless DVC
Podcast.init Episode
The in

Application modernization is essential for continuous improvements to your business value. Modernizing your applications includes improvements to your software architecture, application infrastructure, development techniques, and business strategies. All of which allows you to gain increased business value from existing application code. IBM® z/OS® Container Extensions (IBM zCX) is a part of the IBM z/OS operating system. It makes it possible to run Linux on IBM Z® applications that are packaged as Docker container images on z/OS. Application developers can develop, and data centers can operate, popular open source packages, Linux applications, IBM software, and third-party software together with z/OS applications and data. This IBM Redbooks® publication presents the capabilities of IBM zCX along with several use cases that demonstrate Red Hat OpenShift Container Platform for IBM zCX and the application modernization benefits your business can realize.

Simplify data science infrastructure to give data scientists an efficient path from prototype to production. In Effective Data Science Infrastructure you will learn how to: Design data science infrastructure that boosts productivity Handle compute and orchestration in the cloud Deploy machine learning to production Monitor and manage performance and results Combine cloud-based tools into a cohesive data science environment Develop reproducible data science projects using Metaflow, Conda, and Docker Architect complex applications for multiple teams and large datasets Customize and grow data science infrastructure Effective Data Science Infrastructure: How to make data scientists more productive is a hands-on guide to assembling infrastructure for data science and machine learning applications. It reveals the processes used at Netflix and other data-driven companies to manage their cutting edge data infrastructure. In it, you’ll master scalable techniques for data storage, computation, experiment tracking, and orchestration that are relevant to companies of all shapes and sizes. You’ll learn how you can make data scientists more productive with your existing cloud infrastructure, a stack of open source software, and idiomatic Python. The author is donating proceeds from this book to charities that support women and underrepresented groups in data science. About the Technology Growing data science projects from prototype to production requires reliable infrastructure. Using the powerful new techniques and tooling in this book, you can stand up an infrastructure stack that will scale with any organization, from startups to the largest enterprises. About the Book Effective Data Science Infrastructure teaches you to build data pipelines and project workflows that will supercharge data scientists and their projects. Based on state-of-the-art tools and concepts that power data operations of Netflix, this book introduces a customizable cloud-based approach to model development and MLOps that you can easily adapt to your company’s specific needs. As you roll out these practical processes, your teams will produce better and faster results when applying data science and machine learning to a wide array of business problems. What's Inside Handle compute and orchestration in the cloud Combine cloud-based tools into a cohesive data science environment Develop reproducible data science projects using Metaflow, AWS, and the Python data ecosystem Architect complex applications that require large datasets and models, and a team of data scientists About the Reader For infrastructure engineers and engineering-minded data scientists who are familiar with Python. About the Author At Netflix, Ville Tuulos designed and built Metaflow, a full-stack framework for data science. Currently, he is the CEO of a startup focusing on data science infrastructure. Quotes By reading and referring to this book, I’m confident you will learn how to make your machine learning operations much more efficient and productive. - From the Foreword by Travis Oliphant, Author of NumPy, Founder of Anaconda, PyData, and NumFOCUS Effective Data Science Infrastructure is a brilliant book. It’s a must-have for every data science team. - Ninoslav Cerkez, Logit More data science. Less headaches. - Dr. Abel Alejandro Coronado Iruegas, National Institute of Statistics and Geography of Mexico Indispensable. A copy should be on every data engineer’s bookshelf. - Matthew Copple, Grand River Analytics

Since the general availability of Apache Spark’s native support for running on Kubernetes with Spark 3.1 in March 2021, the Spark community is increasingly choosing to run on k8s to benefit of containerization, efficient resource-sharing, and the tools from the cloud-native ecosystem.
Data teams are faced with complexities in this transition, including how to leverage spot VMs. These instances enable up to 90% cost savings but are not guaranteed to be available and face the risk of termination. This session will cover concrete guidelines on how to make Spark run reliably on spot instances, with code examples from real-world use cases.
Main topics: • Using spot nodes for Spark executors • Mixing instance types & sizes to reduce risk of spot interruptions - cluster autoscaling • Spark 3.0: Graceful Decommissioning - preserve shuffle files on executor shutdown • Spark 3.1: PVC reuse on executor restart - disaggregate compute & shuffle storage • What to look for in future Spark releases
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Elixir is an Erlang-VM bytecode-compatible programming language that is growing in popularity.
In this session I will show how you can apply Elixir towards solving data engineering problems in novel ways.
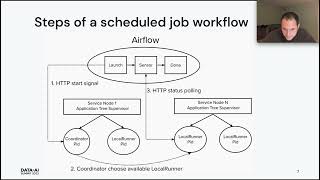
Examples include: • How to leverage Erlang's lightweight distributed process coordination to run clusters of workers across docker containers and perform data ingestion. • A framework that hooks Elixir functions as steps into Airflow graphs. • How to consume and process Kafka events directly within Elixir microservices.
For each of the above I'll show real system examples and walk through the key elements step by step. No prior familiarity with Erlang or Elixir will be required.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/