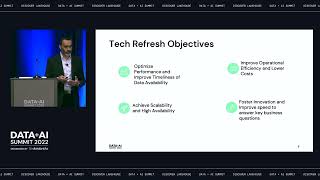
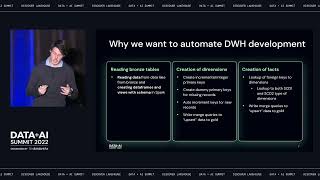
Implement the Snowflake Data Cloud using best practices and reap the benefits of scalability and low-cost from the industry-leading, cloud-based, data warehousing platform. This book provides a detailed how-to explanation, and assumes familiarity with Snowflake core concepts and principles. It is a project-oriented book with a hands-on approach to designing, developing, and implementing your Data Cloud with security at the center. As you work through the examples, you will develop the skill, knowledge, and expertise to expand your capability by incorporating additional Snowflake features, tools, and techniques. Your Snowflake Data Cloud will be fit for purpose, extensible, and at the forefront of both Direct Share, Data Exchange, and Snowflake Marketplace. Building the Snowflake Data Cloud helps you transform your organization into monetizing the value locked up within your data. As the digital economy takes hold, with data volume, velocity, and variety growing at exponential rates, you need tools and techniques to quickly categorize, collate, summarize, and aggregate data. You also need the means to seamlessly distribute to release value. This book shows how Snowflake provides all these things and how to use them to your advantage. The book helps you succeed by delivering faster than you can deliver with legacy products and techniques. You will learn how to leverage what you already know, and what you don’t, all applied in a Snowflake Data Cloud context. After reading this book, you will discover and embrace the future where the Data Cloud is central. You will be able to position your organization to take advantage by identifying, adopting, and preparing your tooling for the coming wave of opportunity around sharing and monetizing valuable, corporate data. What You Will Learn Understand why Data Cloud is important tothe success of your organization Up-skill and adopt Snowflake, leveraging the benefits of cloud platforms Articulate the Snowflake Marketplace and identify opportunities to monetize data Identify tools and techniques to accelerate integration with Data Cloud Manage data consumption by monitoring and controlling access to datasets Develop data load and transform capabilities for use in future projects Who This Book Is For Solution architects seeking implementation patterns to integrate with a Data Cloud; data warehouse developers looking for tips, tools, and techniques to rapidly deliver data pipelines; sales managers who want to monetize their datasets and understand the opportunities that Data Cloud presents; and anyone who wishes to unlock value contained within their data silos