Using various operators to perform daily routines. Integration with Technologies: Redis: Acts as a caching mechanism to optimize data retrieval and processing speed, enhancing overall pipeline performance. MySQL: Utilized for storing metadata and managing task state information within Airflow’s backend database. Tableau: Integrates with Airflow to generate interactive visualizations and dashboards, providing valuable insights into the processed data. Amazon Redshift: Panasonic leverages Redshift for scalable data warehousing, seamlessly integrating it with Airflow for data loading and analytics. Foundry: Integrated with Airflow to access and process data stored within Foundry’s data platform, ensuring data consistency and reliability. Plotly Dashboards: Employed for creating custom, interactive web-based dashboards to visualize and analyze data processed through Airflow pipelines. GitLab CI/CD Pipelines: Utilized for version control and continuous integration/continuous deployment (CI/CD) of Airflow DAGs (Directed Acyclic Graphs), ensuring efficient development and deployment of workflows.
 talk-data.com
talk-data.com
Topic
DWH
Data Warehouse
568
tagged
Activity Trend
Top Events
Whether big or small, one of the biggest challenges organizations face when they want to work with data effectively is often lack of access to it. This is where building a data platform comes in. But building a data platform is no easy feat. It's not just about centralizing data in the data warehouse, it’s also about making sure that data is actionable, trustable and usable. So, how do you make sure your data platform is up to par? Shuang Li is Group Product Manager at Box. With experience of building data, analytics, ML, and observability platform products for both external and internal customers, Shuang is always passionate about the insights, optimizations, and predictions that big data and AI/ML make possible. Throughout her career, she transitioned from academia to engineering, from engineering to product management, and then from an individual contributor to an emerging product executive. In the episode, Adel and Shuang explore her career journey, including transitioning from academia to engineering and helping to work on Google Fiber, how to build a data platform, ingestion pipelines, processing pipelines, challenges and milestones in building a data platform, data observability and quality, developer experience, data democratization, future trends and a lot more. Links Mentioned in the Show: BoxConnect with Shuang on Linkedin[Course] Understanding Modern Data ArchitectureRelated Episode: Scaling Enterprise Analytics with Libby Duane Adams, Chief Advocacy Officer and Co-Founder of Alteryx New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business

Speaker: Jason Reid (Co-founder & Head of Product at Tabular)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. Unbundling a data warehouse means splitting it into constituent and modular components that interact via open standard interfaces. In this talk, Jason Reid discusses the pros and cons of both data warehouse bundling and unbundling in terms of performance, governance, and flexibility, and he examines how the trend of data warehouse unbundling will impact the data engineering landscape in the next 5 years.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.
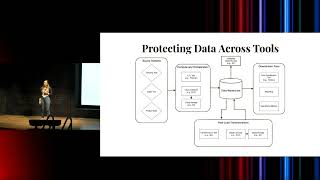
Speaker: Jessica Larson (Data Engineer & Author of “Snowflake Access Control”)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. The requirements for creating a new data warehouse in the post-GDPR world are significantly different from those of the pre-GDPR world, such as the need to prioritize sensitive data protection and regulatory compliance over performance and cost. In this talk, Jessica Larson shares her takeaways from building a new data platform post-GDPR.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.

Shant Hovsepian, Chief Technology Officer of Data Warehousing at Databricks explains why Delta Lake is the most adopted open lakehouse format.
Includes: - Delta Lake UniForm GA (support for and compatibility with Hudi, Apache Iceberg, Delta) - Delta Lake Liquid Clustering - Delta Lake production-ready catalog (Iceberg REST API) - The growth and strength of the Delta ecosystem - Delta Kernel - DuckDB integration with Delta - Delta 4.0

Data modeling is the single most overlooked feature in Power BI Desktop, yet it's what sets Power BI apart from other tools on the market. This practical book serves as your fast-forward button for data modeling with Power BI, Analysis Services tabular, and SQL databases. It serves as a starting point for data modeling, as well as a handy refresher. Author Markus Ehrenmueller-Jensen, founder of Savory Data, shows you the basic concepts of Power BI's semantic model with hands-on examples in DAX, Power Query, and T-SQL. If you're looking to build a data warehouse layer, chapters with T-SQL examples will get you started. You'll begin with simple steps and gradually solve more complex problems. This book shows you how to: Normalize and denormalize with DAX, Power Query, and T-SQL Apply best practices for calculations, flags and indicators, time and date, role-playing dimensions and slowly changing dimensions Solve challenges such as binning, budget, localized models, composite models, and key value with DAX, Power Query, and T-SQL Discover and tackle performance issues by applying solutions in DAX, Power Query, and T-SQL Work with tables, relations, set operations, normal forms, dimensional modeling, and ETL

Shant Hovsepian, CTO of Data Warehousing at Databricks announced the biggest Delta Lake release to date, Delta 4.0, during the Data + AI Summit 2024 in San Francisco.
Speaker: Shant Hovsepian, Chief Technology Officer of Data Warehousing, Databricks

Shant Hovsepian, Chief Technology Officer of Data Warehousing at Databricks, discusses the UniForm data format and its interoperability with other data formats. Shant explains that Delta Lake is the most adopted open lakehouse format.
Speaker: Shant Hovsepian, Chief Technology Officer of Data Warehousing, Databricks

Reynold Xin, Co-founder and Chief Architect at Databricks, presented during Data + AI Summit 2024 on Databricks SQL and its advancements and how to drive performance improvements with the Databricks Data Intelligence Platform.
Speakers: Reynold Xin, Co-founder and Chief Architect, Databricks Pearl Ubaru, Technical Product Engineer, Databricks
Main Points and Key Takeaways (AI-generated summary)
Introduction of Databricks SQL: - Databricks SQL was announced four years ago and has become the fastest-growing product in Databricks history. - Over 7,000 customers, including Shell, AT&T, and Adobe, use Databricks SQL for data warehousing.
Evolution from Data Warehouses to Lakehouses: - Traditional data architectures involved separate data warehouses (for business intelligence) and data lakes (for machine learning and AI). - The lakehouse concept combines the best aspects of data warehouses and data lakes into a single package, addressing issues of governance, storage formats, and data silos.
Technological Foundations: - To support the lakehouse, Databricks developed Delta Lake (storage layer) and Unity Catalog (governance layer). - Over time, lakehouses have been recognized as the future of data architecture.
Core Data Warehousing Capabilities: - Databricks SQL has evolved to support essential data warehousing functionalities like full SQL support, materialized views, and role-based access control. - Integration with major BI tools like Tableau, Power BI, and Looker is available out-of-the-box, reducing migration costs.
Price Performance: - Databricks SQL offers significant improvements in price performance, which is crucial given the high costs associated with data warehouses. - Databricks SQL scales more efficiently compared to traditional data warehouses, which struggle with larger data sets.
Incorporation of AI Systems: - Databricks has integrated AI systems at every layer of their engine, improving performance significantly. - AI systems automate data clustering, query optimization, and predictive indexing, enhancing efficiency and speed.
Benchmarks and Performance Improvements: - Databricks SQL has seen dramatic improvements, with some benchmarks showing a 60% increase in speed compared to 2022. - Real-world benchmarks indicate that Databricks SQL can handle high concurrency loads with consistent low latency.
User Experience Enhancements: - Significant efforts have been made to improve the user experience, making Databricks SQL more accessible to analysts and business users, not just data scientists and engineers. - New features include visual data lineage, simplified error messages, and AI-driven recommendations for error fixes.
AI and SQL Integration: - Databricks SQL now supports AI functions and vector searches, allowing users to perform advanced analysis and query optimizations with ease. - The platform enables seamless integration with AI models, which can be published and accessed through the Unity Catalog.
Conclusion: - Databricks SQL has transformed into a comprehensive data warehousing solution that is powerful, cost-effective, and user-friendly. - The lakehouse approach is presented as a superior alternative to traditional data warehouses, offering better performance and lower costs.

Databricks Data + AI Summit 2024 Keynote Day 1
Experts, researchers and open source contributors — from Databricks and across the data and AI community gathered in San Francisco June 10 - 13, 2024 to discuss the latest technologies in data management, data warehousing, data governance, generative AI for the enterprise, and data in the era of AI.
Hear from Databricks Co-founder and CEO Ali Ghodsi on building generative AI applications, putting your data to work, and how data + AI leads to data intelligence.
Plus a fireside chat between Ali Ghodsi and Nvidia Co-founder and CEO, Jensen Huang, on the expanded partnership between Nvidia and Databricks to accelerate enterprise data for the era of generative AI
Product announcements in the video include: - Databricks Data Intelligence Platform - Native support for NVIDIA GPU acceleration on the Databricks Data Intelligence Platform - Databricks open source model DBRX available as an NVIDIA NIM microservice - Shutterstock Image AI powered by Databricks - Databricks AI/BI - Databricks LakeFlow - Databricks Mosaic AI - Mosaic AI Agent Framework - Mosaic AI Agent Evaluation - Mosaic AI Tools Catalog - Mosaic AI Model Training - Mosaic AI Gateway
In this keynote hear from: - Ali Ghodsi, Co-founder and CEO, Databricks (1:45) - Brian Ames, General Motors (29:55) - Patrick Wendall, Co-founder and VP of Engineering, Databricks (38:00) - Jackie Brosamer, Head of AI, Data and Analytics, Block (1:14:42) - Fei Fei Li, Professor, Stanford University and Denning Co-Director, Stanford Institute for Human-Centered AI (1:23:15) - Jensen Huang, Co-founder and CEO of NVIDIA with Ali Ghodsi, Co-founder and CEO of Databricks (1:42:27) - Reynold Xin, Co-founder and Chief Architect, Databricks (2:07:43) - Ken Wong, Senior Director, Product Management, Databricks (2:31:15) - Ali Ghodsi, Co-founder and CEO, Databricks (2:48:16)
In the fast-paced work environments we are used to, the ability to quickly find and understand data is essential. Data professionals can often spend more time searching for data than analyzing it, which can hinder business progress. Innovations like data catalogs and automated lineage systems are transforming data management, making it easier to ensure data quality, trust, and compliance. By creating a strong metadata foundation and integrating these tools into existing workflows, organizations can enhance decision-making and operational efficiency. But how did this all come to be, who is driving better access and collaboration through data? Prukalpa Sankar is the Co-founder of Atlan. Atlan is a modern data collaboration workspace (like GitHub for engineering or Figma for design). By acting as a virtual hub for data assets ranging from tables and dashboards to models & code, Atlan enables teams to create a single source of truth for all their data assets, and collaborate across the modern data stack through deep integrations with tools like Slack, BI tools, data science tools and more. A pioneer in the space, Atlan was recognized by Gartner as a Cool Vendor in DataOps, as one of the top 3 companies globally. Prukalpa previously co-founded SocialCops, world leading data for good company (New York Times Global Visionary, World Economic Forum Tech Pioneer). SocialCops is behind landmark data projects including India’s National Data Platform and SDGs global monitoring in collaboration with the United Nations. She was awarded Economic Times Emerging Entrepreneur for the Year, Forbes 30u30, Fortune 40u40, Top 10 CNBC Young Business Women 2016, and a TED Speaker. In the episode, Richie and Prukalpa explore challenges within data discoverability, the inception of Atlan, the importance of a data catalog, personalization in data catalogs, data lineage, building data lineage, implementing data governance, human collaboration in data governance, skills for effective data governance, product design for diverse audiences, regulatory compliance, the future of data management and much more. Links Mentioned in the Show: AtlanConnect with Prukalpa[Course] Artificial Intelligence (AI) StrategyRelated Episode: Adding AI to the Data Warehouse with Sridhar Ramaswamy, CEO at SnowflakeSign up to RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile app Empower your business with world-class data and AI skills with DataCamp for business
In today's fast-paced digital world, managing IT operations is more complex than ever. With the rise of cloud services, microservices, and constant software deployments, the pressure on IT teams to keep everything running smoothly is immense. But how do you keep up with the ever-growing flood of data and ensure your systems are always available? AIOps is the use of artificial intelligence to automate and scale IT operations. But what exactly is AIOps, and how can it transform your IT operations? Assaf Resnick is the CEO and Co-Founder of BigPanda. Before founding BigPanda, Assaf was an investor at Sequoia Capital, where he focused on early and growth-stage investing in software, internet, and mobile sectors. Assaf’s time at Sequoia gave him a front-row seat to the challenges of IT scale, complexity, and velocity faced by Operations teams in rapidly scaling and accelerating organizations. This is the problem that Assaf founded BigPanda to solve. In the episode, Richie and Assaf explore AIOps, how AIOps helps manage increasingly complex IT operations, how AIOps differs from DevOps and MLOps, examples of AIOps projects, a real world application of AIOps, the key benefits of AIOps, how to implement AIOps, excitement in the space, how GenAI is improving AIOps and much more. Links Mentioned in the Show: BigPandaGartner: Market Guide for AIOps Platforms[Course] Implementing AI Solutions in BusinessRelated Episode: Adding AI to the Data Warehouse with Sridhar Ramaswamy, CEO at SnowflakeSign up to RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile app Empower your business with world-class data and AI skills with DataCamp for business

Express Learning is a series of books designed as quick reference guides to important undergraduate computer courses. The organized and accessible format of these books allows students to learn important concepts in an easy-to-understand, question-and-answer format. These portable learning tools have been designed as one-stop references for students to understand and master the subjects by themselves.
Features –
• Designed as a student-friendly self-learning guide. The book is written in a clear, concise, and lucid manner. • Easy-to-understand question-and-answer format. • Includes previously asked as well as new questions organized in chapters. • All types of questions including MCQs, short and long questions are covered. • Solutions to numerical questions asked at examinations are provided. • All ideas and concepts are presented with clear examples. • Text is well structured and well supported with suitable diagrams. • Inter-chapter dependencies are kept to a minimum
Book Contents –
1: Database System 2: Conceptual Modelling 3: Relational Model 4: Relational Algebra and Calculus 5: Structured Query Language 6: Relational Database Design 7: Data Storage and Indexing 8: Query Processing and Optimization 9: Introduction to Transaction Processing 10: Concurrency Control Techniques 11: Database Recovery System 12: Database Security 13: Database System Architecture 14: Data Warehousing, OLAP, and Data Mining 15: Information Retrieval 16: Miscellaneous Questions

Express Learning is a series of books designed as quick reference guides to important undergraduate courses. The organized and accessible format of these books allows students to learn important concepts in an easy-to-understand, question-and-answer format. These portable learning tools have been designed as one-stop references for students to understand and master the subjects by themselves.
Book Contents –
Chapter 1: Introduction to Data Warehouse Chapter 2: Building a Data Warehouse Chapter 3: Data Warehouse: Architecture Chapter 4: OLAP Technology Chapter 5: Introduction to Data Mining Chapter 6: Data Preprocessing Chapter 7: Mining Association Rules Chapter 8: Classification and Prediction Chapter 9: Cluster Analysis Chapter 10: Advanced Techniques of Data Mining and Its Applications Index
Rapid change seems to be the new norm within the data and AI space, and due to the ecosystem constantly changing, it can be tricky to keep up. Fortunately, any self-respecting venture capitalist looking into data and AI will stay on top of what’s changing and where the next big breakthroughs are likely to come from. We all want to know which important trends are emerging and how we can take advantage of them, so why not learn from a leading VC. Tomasz Tunguz is a General Partner at Theory Ventures, a $235m early-stage venture capital firm. He blogs sat tomtunguz.com & co-authored Winning with Data. He has worked or works with Looker, Kustomer, Monte Carlo, Dremio, Omni, Hex, Spot, Arbitrum, Sui & many others. He was previously the product manager for Google's social media monetization team, including the Google-MySpace partnership, and managed the launches of AdSense into six new markets in Europe and Asia. Before Google, Tunguz developed systems for the Department of Homeland Security at Appian Corporation. In the episode, Richie and Tom explore trends in generative AI, the impact of AI on professional fields, cloud+local hybrid workflows, data security, and changes in data warehousing through the use of integrated AI tools, the future of business intelligence and data analytics, the challenges and opportunities surrounding AI in the corporate sector. You'll also get to discover Tom's picks for the hottest new data startups. Links Mentioned in the Show: Tom’s BlogTheory VenturesArticle: What Air Canada Lost In ‘Remarkable’ Lying AI Chatbot Case[Course] Implementing AI Solutions in BusinessRelated Episode: Making Better Decisions using Data & AI with Cassie Kozyrkov, Google's First Chief Decision ScientistSign up to RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
Experience the transformative power of real-time interactions with your dashboards through natural language. Say goodbye to waiting for analysts to provide graphics and conclusions. Witness the immediacy of getting your questions answered accurately and precisely, grounded in your data warehouse. Join us for an immersive exploration of data-driven decision-making, complete with a live demo showcasing a practical business scenario. By attending this session, your contact information may be shared with the sponsor for relevant follow up for this event only.
Click the blue “Learn more” button above to tap into special offers designed to help you implement what you are learning at Google Cloud Next 25.
Experience the transformative power of real-time interactions with your dashboards through natural language. Say goodbye to waiting for analysts to provide graphics and conclusions. Witness the immediacy of getting your questions answered accurately and precisely, grounded in your data warehouse. Join us for an immersive exploration of data-driven decision-making, complete with a live demo showcasing a practical business scenario. By attending this session, your contact information may be shared with the sponsor for relevant follow up for this event only.
Click the blue “Learn more” button above to tap into special offers designed to help you implement what you are learning at Google Cloud Next 25.
In this session, we'll "break the ice" on the debate between Google BigQuery vs Snowflake for cloud data warehousing. From performance to scalability, we'll explore the key considerations to help you make the right choice for your data needs. Whether you're a Google Cloud customer or partner, this session will arm you with actionable insights to navigate the cloud data landscape confidently. By attending this session, your contact information may be shared with the sponsor for relevant follow up for this event only.
Click the blue “Learn more” button above to tap into special offers designed to help you implement what you are learning at Google Cloud Next 25.
Slow query engines are forcing users to copy data from open data lakehouses into proprietary data warehouses to achieve their desired performance, but this results in a complex, costly ingestion pipeline that undermines data governance. In this talk, we will dive into the latest developments in data lakehouse querying, why you should avoid using proprietary data warehouses for accelerating queries, and how enterprises like Trip.com are unifying their SQL workloads directly on open data lakehouses.
BigQuery offers a comprehensive solution for migrating your data warehouse, including no-cost tools that help you accelerate migrations, reduce risk, and speed up the time to value. Join this session to discover the new migration tools and best practices.
Click the blue “Learn more” button above to tap into special offers designed to help you implement what you are learning at Google Cloud Next 25.