It’s 2023, why are software engineers still breaking analytics reporting? We’ve all been there, being alerted by an analyst or C-level stakeholders, saying “this report is broken”, only to spend hours determining that an engineer deleted a column on the source database that is now breaking your pipeline and reporting.
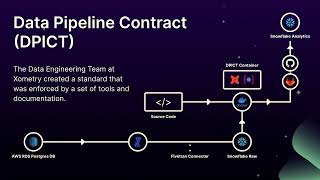
At Xometry, the data engineering team wanted to fix this problem at its root and give the engineering teams a clear and repeatable process that allowed them to be the owners of their own database data. Xometry named the process DPICT (data pipeline contract) and built several internal tools that integrated seamlessly with their developer’s microservice toolsets.
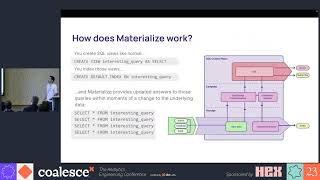
Their software engineers mostly build their database microservices using Postgres, and bring in the data using Fivetran. Using that as the baseline, the team created a set of tools that would allow the engineers to quickly build the staging layer of their database in the data warehouse (Snowflake), but also alert them of the consequences of removing a table or column in downstream reporting.
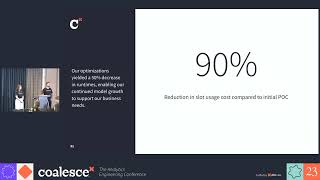
In this talk, Jisan shares the nuts and bolts of the designed solution and process that allowed the team to onboard 13 different microservices seamlessly, working with multiple domains and dozens of developers. The process also helped software engineers to own their own data and realize their impact. The team has saved hundreds hours of data engineering time and resources not having to chase down what changed upstream to break data. Overall, this process has helped to bring transparency to the whole data ecosystem.
Speaker: Jisan Zaman, Data Engineering Manager, Xometry
Register for Coalesce at https://coalesce.getdbt.com