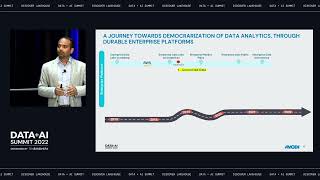
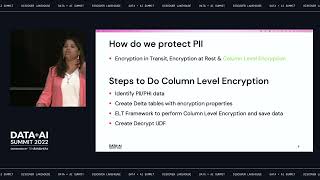
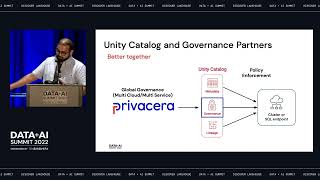
BlockFi is a cryptocurrency platform that allows its clients to grow wealth through various financial products including loans, trading and interest accounts. In this presentation, we will showcase our journey adopting Databricks to build an operational nerve center for analytics across the company. We will demonstrate how to build a cross-functional organization and solve key business problems to earn executive buy-in. We will showcase two of the early successes we've had using machine learning & data science to solve key business challenges in the domains of cyber security and IT Operations. In the domain of security, we will showcase how we are using Graph Analytics to analyze millions of blockchain transactions to identify dust attacks, account takeover and flag risky transactions. The operational IT use case will showcase how we are using Sarimax to forecast platform usage patterns to scale our infrastructure using hourly crypto prices, and financial indicators.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/