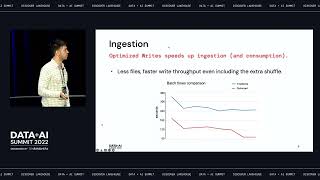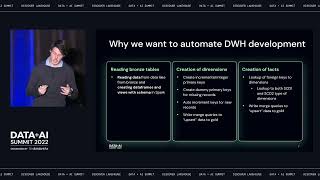
Traditional data warehouses typically struggle when it comes to handling large volumes of data and traffic, particularly when it comes to unstructured data. In contrast, data lakes overcome such issues and have become the central hub for storing data. We outline how we can enable BI Kimball data modelling in a Lakehouse environment.
We present how we built a Spark-based framework to modernize DWH development with data lake as central storage, assuring high data quality and scalability. The framework was implemented at over 15 enterprise data warehouses across Europe.
We present how one can tackle in Spark & with Delta Lake the data warehouse principles like surrogate, foreign and business keys, SCD type 1 and 2 etc. Additionally, we share our experiences on how such a unified data modelling framework can bridge BI with modern day use cases, such as machine learning and real time analytics. The session outlines the original challenges, the steps taken and the technical hurdles we faced.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/