Summary Generative AI has rapidly gained adoption for numerous use cases. To support those applications, organizational data platforms need to add new features and data teams have increased responsibility. In this episode Lior Gavish, co-founder of Monte Carlo, discusses the various ways that data teams are evolving to support AI powered features and how they are incorporating AI into their work. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino.Your host is Tobias Macey and today I'm interviewing Lior Gavish about the impact of AI on data engineersInterview IntroductionHow did you get involved in the area of data management?Can you start by clarifying what we are discussing when we say "AI"?Previous generations of machine learning (e.g. deep learning, reinforcement learning, etc.) required new features in the data platform. What new demands is the current generation of AI introducing?Generative AI also has the potential to be incorporated in the creation/execution of data pipelines. What are the risk/reward tradeoffs that you have seen in practice?What are the areas where LLMs have proven useful/effective in data engineering?Vector embeddings have rapidly become a ubiquitous data format as a result of the growth in retrieval augmented generation (RAG) for AI applications. What are the end-to-end operational requirements to support this use case effectively?As with all data, the reliability and quality of the vectors will impact the viability of the AI application. What are the different failure modes/quality metrics/error conditions that they are subject to?As much as vectors, vector databases, RAG, etc. seem exotic and new, it is all ultimately shades of the same work that we have been doing for years. What are the areas of overlap in the work required for running the current generation of AI, and what are the areas where it diverges?What new skills do data teams need to acquire to be effective in supporting AI applications?What are the most interesting, innovative, or unexpected ways that you have seen AI impact data engineering teams?What are the most interesting, unexpected, or challenging lessons that you have learned while working with the current generation of AI?When is AI the wrong choice?What are your predictions for the future impact of AI on data engineering teams?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your Links Monte CarloPodcast EpisodeNLP == Natural Language ProcessingLarge Language ModelsGenerative AIMLOpsML EngineerFeature StoreRetrieval Augmented Generation (RAG)LangchainThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
 talk-data.com
talk-data.com
Topic
Data Engineering
1127
tagged
Activity Trend
Top Events
Summary In this episode Praveen Gujar, Director of Product at LinkedIn, talks about the intricacies of product management for data and analytical platforms. Praveen shares his journey from Amazon to Twitter and now LinkedIn, highlighting his extensive experience in building data products and platforms, digital advertising, AI, and cloud services. He discusses the evolving role of product managers in data-centric environments, emphasizing the importance of clean, reliable, and compliant data. Praveen also delves into the challenges of building scalable data platforms, the need for organizational and cultural alignment, and the critical role of product managers in bridging the gap between engineering and business teams. He provides insights into the complexities of platformization, the significance of long-term planning, and the necessity of having a strong relationship with engineering teams. The episode concludes with Praveen offering advice for aspiring product managers and discussing the future of data management in the context of AI and regulatory compliance.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino.Your host is Tobias Macey and today I'm interviewing Praveen Gujar about product management for data and analytical platformsInterview IntroductionHow did you get involved in the area of data management?Product management is typically thought of as being oriented toward customer facing functionality and features. What is involved in being a product manager for data systems?Many data-oriented products that are customer facing require substantial technical capacity to serve those use cases. How does that influence the process of determining what features to provide/create?investment in technical capacity/platformsidentifying groupings of features that can be served by a common platform investmentmanaging organizational pressures between engineering, product, business, finance, etc.What are the most interesting, innovative, or unexpected ways that you have seen "Data Products & Platforms @ Big-tech" used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on "Building Data Products & Platforms for Big-tech"?When is "Data Products & Platforms @ Big-tech" the wrong choice?What do you have planned for the future of "Data Products & Platforms @ Big-tech"?Contact Info LinkedInWebsiteParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links DataHubPodcast EpisodeRAG == Retrieval Augmented GenerationThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Summary Postgres is one of the most widely respected and liked database engines ever. To make it even easier to use for developers to use, Nikita Shamgunov decided to makee it serverless, so that it can scale from zero to infinity. In this episode he explains the engineering involved to make that possible, as well as the numerous details that he and his team are packing into the Neon service to make it even more attractive for anyone who wants to build on top of Postgres. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino.Your host is Tobias Macey and today I'm interviewing Nikita Shamgunov about his work on making Postgres a serverless database at Neon.Interview IntroductionHow did you get involved in the area of data management?Can you describe what Neon is and the story behind it?The ecosystem around Postgres is large and varied. What are the pain points that you are trying to address with Neon? What does it mean for a database to be serverless?What kinds of products and services are unlocked by making Postgres a serverless database?How does your vision for Neon compare/contrast with what you know of PlanetScale?Postgres is known for having a large ecosystem of plugins that add a lot of interesting and useful features, but the storage layer has not been as easily extensible historically. How have architectural changes in recent Postgres releases enabled your work on Neon?What are the core pieces of engineering that you have had to complete to make Neon possible?How have the design and goals of the project evolved since you first started working on it?The separation of storage and compute is one of the most fundamental promises of the cloud. What new capabilities does that enable in Postgres?How does the branching functionality change the ways that development teams are able to deliver and debug features?Because the storage is now a networked system, what new performance/latency challenges does that introduce? How have you addressed them in Neon?Anyone who has ever operated a Postgres instance has had to tackle the upgrade process. How does Neon address that process for end users?The rampant growth of AI has touched almost every aspect of computing, and Postgres is no exception. How does the introduction of pgvector and semantic/similarity search functionality impact the adoption and usage patterns of Postgres/Neon?What new challenges does that introduce for you as an operator and business owner?What are the lessons that you learned from MemSQL/SingleStore that have been most helpful in your work at Neon?What are the most interesting, innovative, or unexpected ways that you have seen Neon used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on Neon?When is Neon the wrong choice? Postgres?What do you have planned for the future of Neon?Contact Info @nikitabase on TwitterLinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links NeonPostgreSQLNeon GithubPHPMySQLSQL ServerSingleStorePodcast EpisodeAWS AuroraKhosla VenturesYugabyteDBPodcast EpisodeCockroachDBPodcast EpisodePlanetScalePodcast EpisodeClickhousePodcast EpisodeDuckDBPodcast EpisodeWAL == Write-Ahead LogPgBouncerPureStoragePaxos)HNSW IndexIVF Flat IndexRAG == Retrieval Augmented GenerationAlloyDBNeon Serverless DriverDevinmagic.devThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
We stream the podcasts on YouTube, where each session is also recorded and published on our channel, complete with timestamps, a transcript, and important links.
You can access all the podcast episodes here - https://datatalks.club/podcast.html
📚Check our free online courses ML Engineering course - http://mlzoomcamp.com Data Engineering course - https://github.com/DataTalksClub/data-engineering-zoomcamp MLOps course - https://github.com/DataTalksClub/mlops-zoomcamp Analytics in Stock Markets - https://github.com/DataTalksClub/stock-markets-analytics-zoomcamp LLM course - https://github.com/DataTalksClub/llm-zoomcamp Read about all our courses in one place - https://datatalks.club/blog/guide-to-free-online-courses-at-datatalks-club.html
👋🏼 GET IN TOUCH If you want to support our community, use this link - https://github.com/sponsors/alexeygrigorev
If you’re a company, support us at [email protected]
Looking for a way to streamline your data workflows and master the art of orchestration? As we navigate the complexities of modern data engineering, Airflow’s dynamic workflow and complex data pipeline dependencies are starting to become more and more common nowadays. In order to empower data engineers to exploit Airflow as the main orchestrator, Airflow Datasets can be easily integrated in your data journey. This session will showcase the Dynamic Workflow orchestration in Airflow and how to manage multi-DAGs dependencies with Multi-Dataset listening. We’ll take you through a real-time data pipeline with Pub/Sub messaging integration and dbt in Google Cloud environment, to ensure data transformations are triggered only upon new data ingestion, moving away from rigid time-based scheduling or the use of sensors and other legacy ways to trigger a DAG.
In the realm of data engineering, machine learning pipelines and using cloud and web services there is a huge demand for orchestration technologies. Apache Airflow belongs to the most popular orchestration technologies or even is the most popular one. In this presentation we are going to focus these aspects of Airflow that make it so popular and whether it became the orchestration industry standard.
Does your organization feel like the responsibility to write Airflow DAGs, handle the Airflow infrastructure administration, debug failing tasks, and keep up with new features and best practices is too much for too few people? Perhaps you only have one data team that owns all of that; or you have too many teams that have too many permissions into other teams’ DAGs. The topic of this talk is how Rakuten Kobo enables self-service for various teams within its organization to build their own DAGs in Airflow. The talk will include how we delineate the Airflow responsibilities of various teams, build guard rails for new Airflow developers, how different teams automatically have permissions required for their “own” DAGs (but not others), the unique responsibilities of Operations and Data Engineering teams, and how it is done in a scalable manner. Maybe you’ll be inspired to make changes in your own organization, or have some tips of your own to share! Depending on questions, we could discuss some of the technical details as well.
Every data team out there is being asked from their business stakeholders about Generative AI. Taking LLM centric workloads to production is not a trivial task. At the foundational level, there are a set of challenges around data delivery, data quality, and data ingestion that mirror traditional data engineering problems. Once you’re past those, there’s a set of challenges related to the underlying use case you’re trying to solve. Thankfully, because of how Airflow was already being used at these companies for data engineering and MLOps use cases, it has become the defacto orchestration layer behind many GenAI use cases for startups and Fortune 500s. This talk will be a tour of various methods, best practices, and considerations used in the Airflow community when taking GenAI use cases to production. We’ll focus on 4 primary use cases; RAG, fine tuning, resource management, and batch inference and take a walk through patterns different members in the community have used to productionize this new, exciting technology.
In the realm of data engineering, there is a prevalent tendency for professionals to develop similar Directed Acyclic Graphs (DAGs) to manage analogous tasks. Leveraging Dag Params presents an effective strategy for mitigating redundancy within these DAGs. Moreover, the utilization of Dag Params facilitates seamless enforcement of user inputs, thereby streamlining the process of incorporating validations into the DAG codebase.
While Airflow is widely known for orchestrating and managing workflows, particularly in the context of data engineering, data science, ML (Machine Learning), and ETL (Extract, Transform, Load) processes, its flexibility and extensibility make it a highly versatile tool suitable for a variety of use cases beyond these domains. In fact, Cloudflare has publicly shared in the past an example on how Airflow was leveraged to build a system that automates datacenter expansions. In this talk, I will share a few more of our use cases beyond traditional data engineering, demonstrating Airflow’s sophisticated capabilities for orchestrating a wide variety of complex workflows, and discussing how Airflow played a crucial role in building some of the highly successful autonomous systems at Cloudflare, from handling automated bare metal server diagnostics and recovery at scale, to Zero Touch Provisioning that is helping us accelerate the roll out of inference-optimized GPUs in 150+ cities in multiple countries globally.
Summary This episode features an insightful conversation with Petr Janda, the CEO and founder of Synq. Petr shares his journey from being an engineer to founding Synq, emphasizing the importance of treating data systems with the same rigor as engineering systems. He discusses the challenges and solutions in data reliability, including the need for transparency and ownership in data systems. Synq's platform helps data teams manage incidents, understand data dependencies, and ensure data quality by providing insights and automation capabilities. Petr emphasizes the need for a holistic approach to data reliability, integrating data systems into broader business processes. He highlights the role of data teams in modern organizations and how Synq is empowering them to achieve this. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino.Your host is Tobias Macey and today I'm interviewing Petr Janda about Synq, a data reliability platform focused on leveling up data teams by supporting a culture of engineering rigorInterview IntroductionHow did you get involved in the area of data management?Can you describe what Synq is and the story behind it? Data observability/reliability is a category that grew rapidly over the past ~5 years and has several vendors focused on different elements of the problem. What are the capabilities that you saw as lacking in the ecosystem which you are looking to address?Operational/infrastructure engineers have spent the past decade honing their approach to incident management and uptime commitments. How do those concepts map to the responsibilities and workflows of data teams? Tooling only plays a small part in SLAs and incident management. How does Synq help to support the cultural transformation that is necessary?What does an on-call rotation for a data engineer/data platform engineer look like as compared with an application-focused team?How does the focus on data assets/data products shift your approach to observability as compared to a table/pipeline centric approach?With the focus on sharing ownership beyond the boundaries on the data team there is a strong correlation with data governance principles. How do you see organizations incorporating Synq into their approach to data governance/compliance?Can you describe how Synq is designed/implemented? How have the scope and goals of the product changed since you first started working on it?For a team who is onboarding onto Synq, what are the steps required to get it integrated into their technology stack and workflows?What are the types of incidents/errors that you are able to identify and alert on? What does a typical incident/error resolution process look like with Synq?What are the most interesting, innovative, or unexpected ways that you have seen Synq used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on Synq?When is Synq the wrong choice?What do you have planned for the future of Synq?Contact Info LinkedInSubstackParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links SynqIncident ManagementSLA == Service Level AgreementData GovernancePodcast EpisodePagerDutyOpsGenieClickhousePodcast EpisodedbtPodcast EpisodeSQLMeshPodcast EpisodeThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA

Unlock the potential of the Elastic Stack with the "Elastic Stack 8.x Cookbook." This book provides over 80 hands-on recipes, guiding you through ingesting, processing, and visualizing data using Elasticsearch, Logstash, Kibana, and more. You'll also explore advanced features like machine learning and observability to create data-driven applications with ease. What this Book will help me do Implement a robust workflow for ingesting, transforming, and visualizing diverse datasets. Utilize Kibana to create insightful dashboards and visual analytics. Leverage Elastic Stack's AI capabilities, such as natural language processing and machine learning. Develop search solutions and integrate advanced features like vector search. Monitor and optimize your Elastic Stack deployments for performance and security. Author(s) Huage Chen and Yazid Akadiri are experienced professionals in the field of Elastic Stack. They bring years of practical experience in data engineering, observability, and software development. Huage and Yazid aim to provide a clear, practical pathway for both beginners and experienced users to get the most out of the Elastic Stack's capabilities. Who is it for? This book is perfect for developers, data engineers, and observability practitioners looking to harness the power of Elastic Stack. It caters to both beginners and experts, providing clear instructions to help readers understand and implement powerful data solutions. If you're working with search applications, data analysis, or system observability, this book is an ideal resource.
Summary
Data lakehouse architectures have been gaining significant adoption. To accelerate adoption in the enterprise Microsoft has created the Fabric platform, based on their OneLake architecture. In this episode Dipti Borkar shares her experiences working on the product team at Fabric and explains the various use cases for the Fabric service.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm interviewing Dipti Borkar about her work on Microsoft Fabric and performing analytics on data withou
Interview
Introduction How did you get involved in the area of data management? Can you describe what Microsoft Fabric is and the story behind it? Data lakes in various forms have been gaining significant popularity as a unified interface to an organization's analytics. What are the motivating factors that you see for that trend? Microsoft has been investing heavily in open source in recent years, and the Fabric platform relies on several open components. What are the benefits of layering on top of existing technologies rather than building a fully custom solution?
What are the elements of Fabric that were engineered specifically for the service? What are the most interesting/complicated integration challenges?
How has your prior experience with Ahana and Presto informed your current work at Microsoft? AI plays a substantial role in the product. What are the benefits of embedding Copilot into the data engine?
What are the challenges in terms of safety and reliability?
What are the most interesting, innovative, or unexpected ways that you have seen the Fabric platform used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on data lakes generally, and Fabric specifically? When is Fabric the wrong choice? What do you have planned for the future of data lake analytics?
Contact Info
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.
Links
Microsoft Fabric Ahana episode DB2 Distributed Spark Presto Azure Data MAD Landscape
Podcast Episode ML Podcast Episode
Tableau dbt Medallion Architecture Microsoft Onelake ORC Parquet Avro Delta Lake Iceberg
Podcast Episode
Hudi
Podcast Episode
Hadoop PowerBI
Podcast Episode
Velox Gluten Apache XTable GraphQL Formula 1 McLaren
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Starburst: 
This episode is brought to you by Starburst - an end-to-end data lakehouse platform for data engineers who are battling to build and scale high quality data pipelines on the data lake. Powered by T

Speaker: Jason Reid (Co-founder & Head of Product at Tabular)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. Unbundling a data warehouse means splitting it into constituent and modular components that interact via open standard interfaces. In this talk, Jason Reid discusses the pros and cons of both data warehouse bundling and unbundling in terms of performance, governance, and flexibility, and he examines how the trend of data warehouse unbundling will impact the data engineering landscape in the next 5 years.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.

Speaker: Jide Ogunjobi (Founder & CTO at Context Data)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. As organizations accumulate ever-larger stores of data across disparate systems, efficiently querying and gaining insights from enterprise data remain ongoing challenges. To address this, we propose developing an intelligent agent that can automatically discover, map, and query all data within an enterprise. This “Enterprise Data Model/Architect Agent” employs generative AI techniques for autonomous enterprise data modeling and architecture.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.

Speaker: Iaroslav Zeigerman (Co-Founder and Chief Architect at Tobiko Data)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. The development and evolution of data pipelines are hindered by outdated tooling compared to software development. Creating new development environments is cumbersome: Populating them with data is compute-intensive, and the deployment process is error-prone, leading to higher costs, slower iteration, and unreliable data. SQLMesh, an open-source project born from our collective experience at companies like Airbnb, Apple, Google, and Netflix, is designed to handle the complexities of evolving data pipelines at an internet scale. In this talk, Iaroslav Zeigerman discusses challenges faced by data practitioners today and how core SQLMesh concepts solve them.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.

Speakers: Stephanie Vezich Tamayo (Senior Machine Learning Engineer at Netflix) Binbing Hou (Senior Software Engineer at Netflix)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. At Netflix, hundreds of thousands of workflows and millions of jobs are running every day on our big data platform, but diagnosing and remediating job failures can impose considerable operational burdens. To handle errors efficiently, Netflix developed a rule-based classifier for error classification called “Pensive.” However, as the system has increased in scale and complexity, Pensive has been facing challenges due to its limited support for operational automation, especially for handling memory configuration errors and unclassified errors. To address these challenges, we have developed a new feature called “Auto Remediation,” which integrates the rules-based classifier with an ML service.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.

Speaker: Tulika Bhatt (Senior Data Engineer at Netflix)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. Netflix generates approximately 18 billion impressions daily. These impressions significantly influence a viewer’s browsing experience, as they are essential for powering video ranker algorithms and computing adaptive pages, With the evolution of user interfaces to be more responsive to in-session interactions, coupled with the growing demand for real-time adaptive recommendations, it has become highly imperative that these impressions are provided on a near real-time basis. This talk will delve into the creative solutions Netflix deploys to manage this high-volume, real-time data requirement while balancing scalability and cost.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.
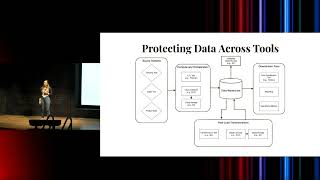
Speaker: Jessica Larson (Data Engineer & Author of “Snowflake Access Control”)
This tech talk is a part of the Data Engineering Open Forum at Netflix 2024. The requirements for creating a new data warehouse in the post-GDPR world are significantly different from those of the pre-GDPR world, such as the need to prioritize sensitive data protection and regulatory compliance over performance and cost. In this talk, Jessica Larson shares her takeaways from building a new data platform post-GDPR.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.

Max Schmeiser (Vice President of Studio and Content Data Science & Engineering) extends a warm welcome to all attendees, marking the beginning of our inaugural Data Engineering Open Forum.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group (https://groups.google.com/g/data-engineering-open-forum) to stay tuned to event announcements.